

Reinforcement Studying (RL) excels at tackling particular person duties however struggles with multitasking, particularly throughout totally different robotic kinds. World fashions, which simulate environments, provide scalable options however usually depend on inefficient, high-variance optimization strategies. Whereas massive fashions skilled on huge datasets have superior generalizability in robotics, they usually want near-expert knowledge and fail to adapt throughout numerous morphologies. RL can be taught from suboptimal knowledge, making it promising for multitask settings. Nonetheless, strategies like zeroth-order planning in world fashions face scalability points and grow to be much less efficient as mannequin dimension will increase, notably in large fashions like GAIA-1 and UniSim.
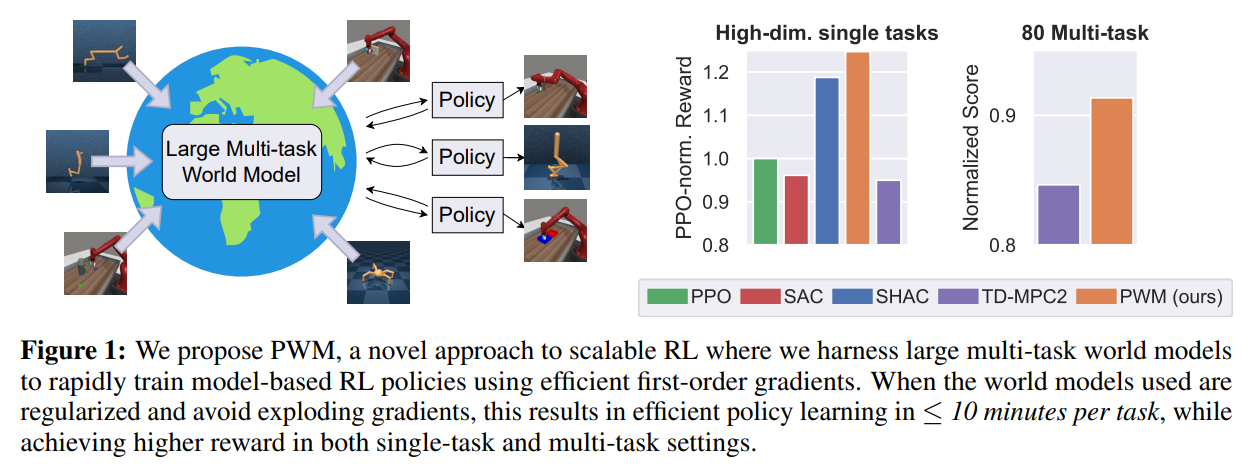
Researchers from Georgia Tech and UC San Diego have launched Coverage studying with massive World Fashions (PWM), an modern model-based reinforcement studying (MBRL) algorithm. PWM pretrains world fashions on offline knowledge and makes use of them for first-order gradient coverage studying, enabling it to resolve duties with as much as 152 motion dimensions. This method outperforms present strategies by reaching as much as 27% larger rewards with out expensive on-line planning. PWM emphasizes the utility of clean, secure gradients over lengthy horizons relatively than mere accuracy. It demonstrates that environment friendly first-order optimization results in higher insurance policies and quicker coaching than conventional zeroth-order strategies.
RL splits into model-based and model-free approaches. Mannequin-free strategies like PPO and SAC dominate real-world purposes and make use of actor-critic architectures. SAC makes use of First-order Gradients (FoG) for coverage studying, providing low variance however dealing with points with goal discontinuities. Conversely, PPO depends on zeroth-order gradients, that are strong to discontinuities however liable to excessive variance and slower optimization. Lately, the main target in robotics has shifted to massive multi-task fashions skilled by way of conduct cloning. Examples embody RT-1 and RT-2 for object manipulation. Nonetheless, the potential of huge fashions in RL nonetheless must be explored. MBRL strategies like DreamerV3 and TD-MPC2 leverage massive world fashions, however their scalability might be improved, notably with the rising dimension of fashions like GAIA-1 and UniSim.
The examine focuses on discrete-time, infinite-horizon RL situations represented by a Markov Choice Course of (MDP) involving states, actions, dynamics, and rewards. RL goals to maximise cumulative discounted rewards by means of a coverage. Generally, that is tackled utilizing actor-critic architectures, which approximate state values and optimize insurance policies. In MBRL, extra parts akin to discovered dynamics and reward fashions, usually referred to as world fashions, are used. These fashions can encode true states into latent representations. Leveraging these world fashions, PWM effectively optimizes insurance policies utilizing FoG, lowering variance and bettering pattern effectivity even in complicated environments.
In evaluating the proposed technique, complicated management duties had been tackled utilizing the flex simulator, specializing in environments like Hopper, Ant, Anymal, Humanoid, and muscle-actuated Humanoid. Comparisons had been made towards SHAC, which makes use of floor reality fashions, and TD-MPC2, a model-free technique that actively plans at inference time. Outcomes confirmed that PWM achieved larger rewards and smoother optimization landscapes than SHAC and TD-MPC2. Additional exams on 30 and 80 multi-task environments revealed PWM’s superior reward efficiency and quicker inference time than TD-MPC2. Ablation research highlighted PWM’s robustness to stiff contact fashions and better pattern effectivity, particularly with better-trained world fashions.
The examine launched PWM as an method in MBRL. PWM makes use of massive multi-task world fashions as differentiable physics simulators, leveraging first-order gradients for environment friendly coverage coaching. The evaluations highlighted PWM’s means to outperform present strategies, together with these with entry to ground-truth simulation fashions like TD-MPC2. Regardless of its strengths, PWM depends closely on intensive pre-existing knowledge for world mannequin coaching, limiting its applicability in low-data situations. Moreover, whereas PWM gives environment friendly coverage coaching, it requires re-training for every new process, posing challenges for speedy adaptation. Future analysis may discover enhancements in world mannequin coaching and lengthen PWM to image-based environments and real-world purposes.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.