

Rockset is a database used for real-time search and analytics on streaming information. In eventualities involving analytics on large information streams, we’re usually requested the utmost throughput and lowest information latency Rockset can obtain and the way it stacks as much as different databases. To seek out out, we determined to check the streaming ingestion efficiency of Rockset’s subsequent era cloud structure and evaluate it to open-source search engine Elasticsearch, a preferred sink for Apache Kafka.
For this benchmark, we evaluated Rockset and Elasticsearch ingestion efficiency on throughput and information latency. Throughput measures the speed at which information is processed, impacting the database’s potential to effectively assist high-velocity information streams. Knowledge latency, then again, refers back to the period of time it takes to ingest and index the info and make it obtainable for querying, affecting the power of a database to offer up-to-date outcomes. We study latency on the ninety fifth and 99th percentile, provided that each databases are used for manufacturing purposes and require predictable efficiency.
We discovered that Rockset beat Elasticsearch on each throughput and end-to-end latency on the 99th percentile. Rockset achieved as much as 4x greater throughput and a pair of.5x decrease latency than Elasticsearch for streaming information ingestion.
On this weblog, we’ll stroll by the benchmark framework, configuration and outcomes. We’ll additionally delve beneath the hood of the 2 databases to higher perceive why their efficiency differs in terms of search and analytics on high-velocity information streams.
Study extra in regards to the efficiency of Elasticsearch and Rockset by watching the tech speak Evaluating Elasticsearch and Rockset Streaming Ingest and Question Efficiency with CTO Dhruba Borthakur and principal engineer and architect Igor Canadi.
Why measure streaming information ingestion?
Streaming information is on the rise with over 80% of Fortune 100 firms utilizing Apache Kafka. Many industries together with gaming, web and monetary providers are mature of their adoption of occasion streaming platforms and have already graduated from information streams to torrents. This makes it essential to know the dimensions at which finally constant databases Rockset and Elasticsearch can ingest and index information for real-time search and analytics.
With the intention to unlock streaming information for real-time use instances together with personalization, anomaly detection and logistics monitoring, organizations pair an occasion streaming platform like Confluent Cloud, Apache Kafka and Amazon Kinesis with a downstream database. There are a number of benefits that come from utilizing a database like Rockset or Elasticsearch together with:
- Incorporating historic and real-time streaming information for search and analytics
- Supporting transformations and rollups at time of ingest
- Supreme when information mannequin is in flux
- Supreme when question patterns require particular indexing methods
Moreover, many search and analytics purposes are latency delicate, leaving solely a small window of time to take motion. That is the advantage of databases that have been designed with streaming in thoughts, they will effectively course of incoming occasions as they arrive into the system quite than go into sluggish batch processing modes.
Now, let’s leap into the benchmark so you’ll be able to have an understanding of the streaming ingest efficiency you’ll be able to obtain on Rockset and Elasticsearch.
Utilizing RockBench to measure throughput and latency
We evaluated the streaming ingest efficiency of Rockset and Elasticsearch on RockBench, a benchmark that measures the height throughput and end-to-end latency of databases.
RockBench has two parts: a knowledge generator and a metrics evaluator. The info generator writes occasions each second to the database; the metrics evaluator measures the throughput and end-to-end latency or the time from when the occasion is generated till it’s queryable.
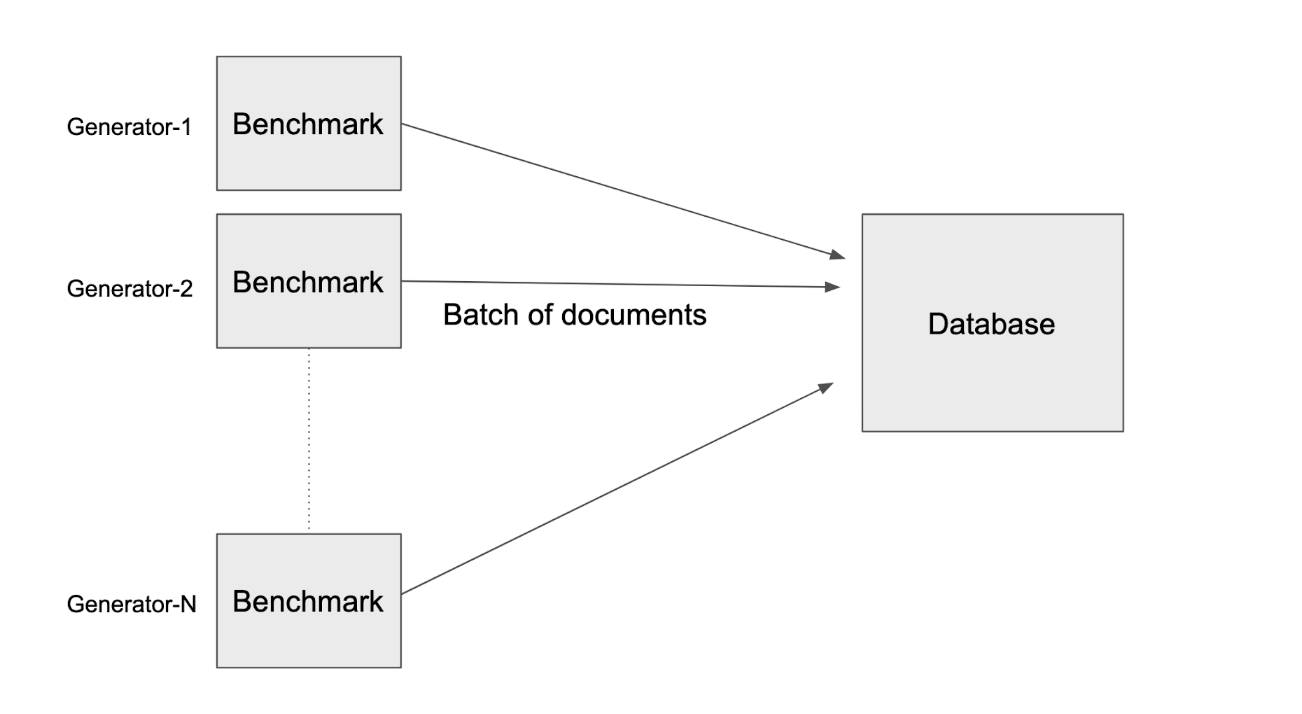
The info generator generates paperwork, every doc is the dimensions of 1.25KB and represents a single occasion. Which means that 8,000 writes is equal to 10 MB/s.
Peak throughput is the best throughput at which the database can sustain with out an ever-growing backlog. For this benchmark, we regularly added ingested information in increments of 10 MB/s till the database may not sustainably sustain with the throughput for a interval of 45 minutes. We decided the height throughput because the increment of 10 MB/s above which the database may not maintain the write price.
Every doc has 60 fields containing nested objects and arrays to reflect semi-structured occasions in actual life eventualities. The paperwork additionally comprise a number of fields which are used to calculate the end-to-end latency:
_id: The distinctive identifier of the doc_event_time: Displays the clock time of the generator machinegenerator_identifier: 64-bit random quantity
The _event_time of that doc is then subtracted from the present time of the machine to reach on the information latency of the doc. This measurement additionally consists of round-trip latency—the time required to run the question and get outcomes from the database again to the consumer. This metric is revealed to a Prometheus server and the p50, p95 and p99 latencies are calculated throughout all evaluators.
On this efficiency analysis, the info generator inserts new paperwork to the database and doesn’t replace any current paperwork.
RockBench Configuration & Outcomes
To check the scalability of ingest and indexing efficiency in Rockset and Elasticsearch, we used two configurations with completely different compute and reminiscence allocations. We chosen the Elasticsearch Elastic Cloud cluster configuration that the majority carefully matches the CPU and reminiscence allocations of the Rockset digital situations. Each configurations made use of Intel Ice Lake processors.
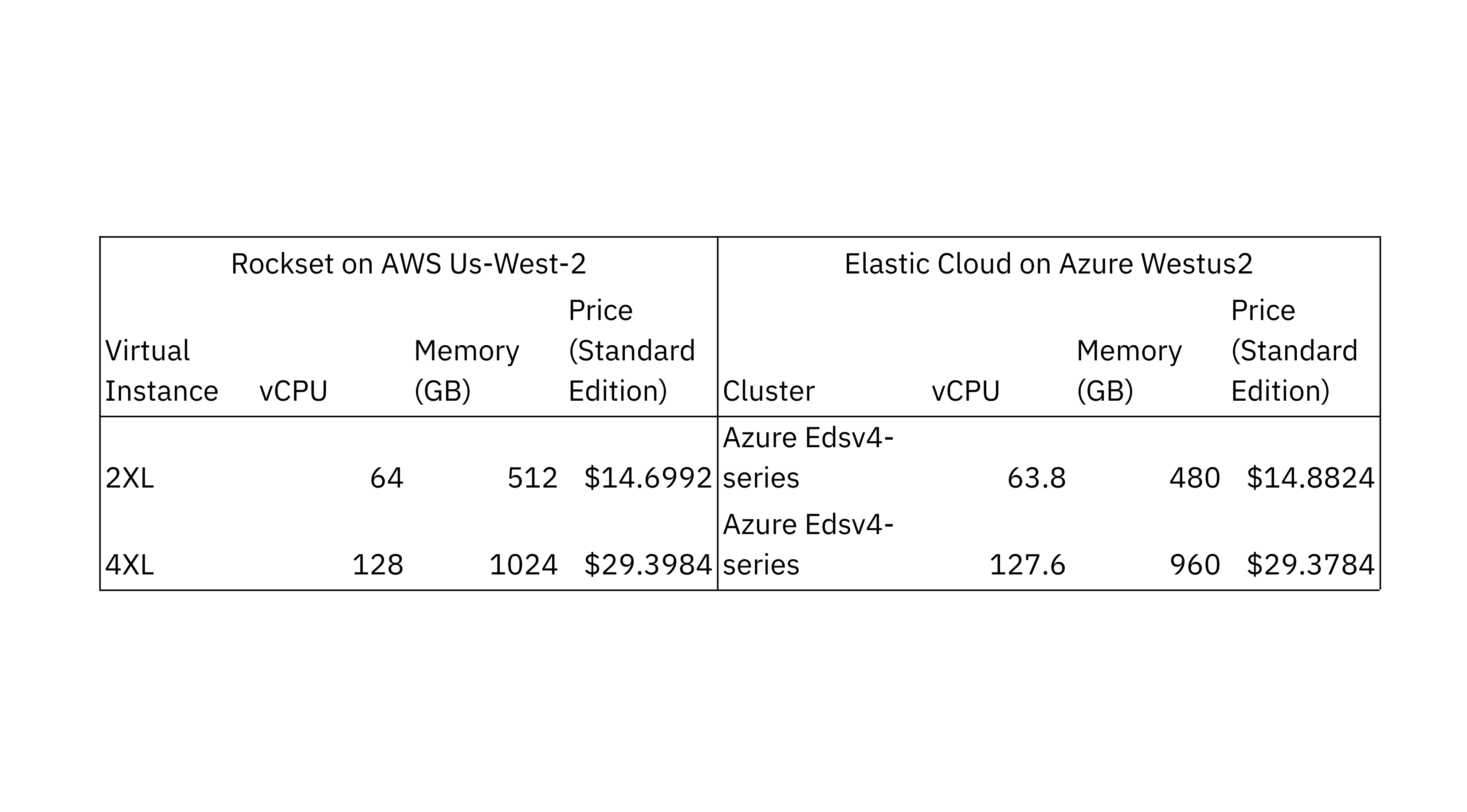
The info turbines and information latency evaluators for Rockset and Elasticsearch have been run of their respective clouds and the US West 2 areas for regional compatibility. We chosen Elastic Elasticsearch on Azure as it’s a cloud that provides Intel Ice Lake processors. The info generator used Rockset’s write API and Elasticsearch’s bulk API to put in writing new paperwork to the databases.
We ran the Elasticsearch benchmark on the Elastic Elasticsearch managed service model v8.7.0, the most recent steady model, with 32 major shards, a single duplicate and availability zone. We examined a number of completely different refresh intervals to tune for higher efficiency and landed on a refresh interval of 1 second which additionally occurs to be the default setting in Elasticsearch. We settled on a 32 major shard rely after evaluating efficiency utilizing 64 and 32 shards, following the Elastic steerage that shard measurement vary from 10 GB to 50 GB. We ensured that the shards have been equally distributed throughout all the nodes and that rebalancing was disabled.
As Rockset is a SaaS service, all cluster operations together with shards, replicas and indexes are dealt with by Rockset. You possibly can count on to see comparable efficiency on customary version Rockset to what was achieved on the RockBench benchmark.
We ran the benchmark utilizing batch sizes of fifty and 500 paperwork per write request to showcase how nicely the databases can deal with greater write charges. We selected batch sizes of fifty and 500 paperwork as they mimic the load sometimes present in incrementally updating streams and excessive quantity information streams.
Throughput: Rockset sees as much as 4x greater throughput than Elasticsearch
Peak throughput is the best throughput at which the database can sustain with out an ever-growing backlog. The outcomes with a batch measurement of fifty showcase that Rockset achieves as much as 4x greater throughput than Elasticsearch.
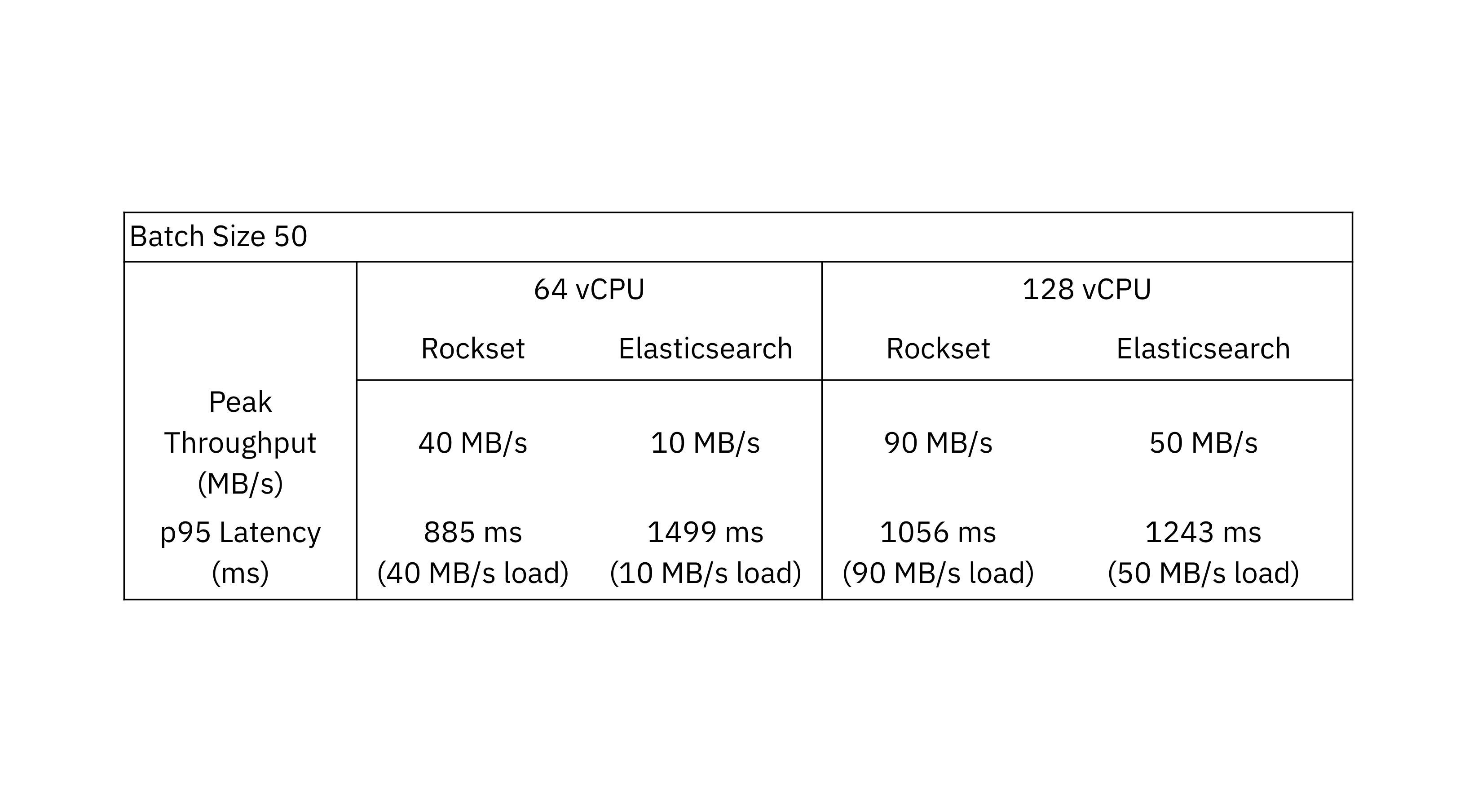
The outcomes with a batch measurement of fifty showcase that Rockset achieves as much as 4x greater throughput than Elasticsearch.
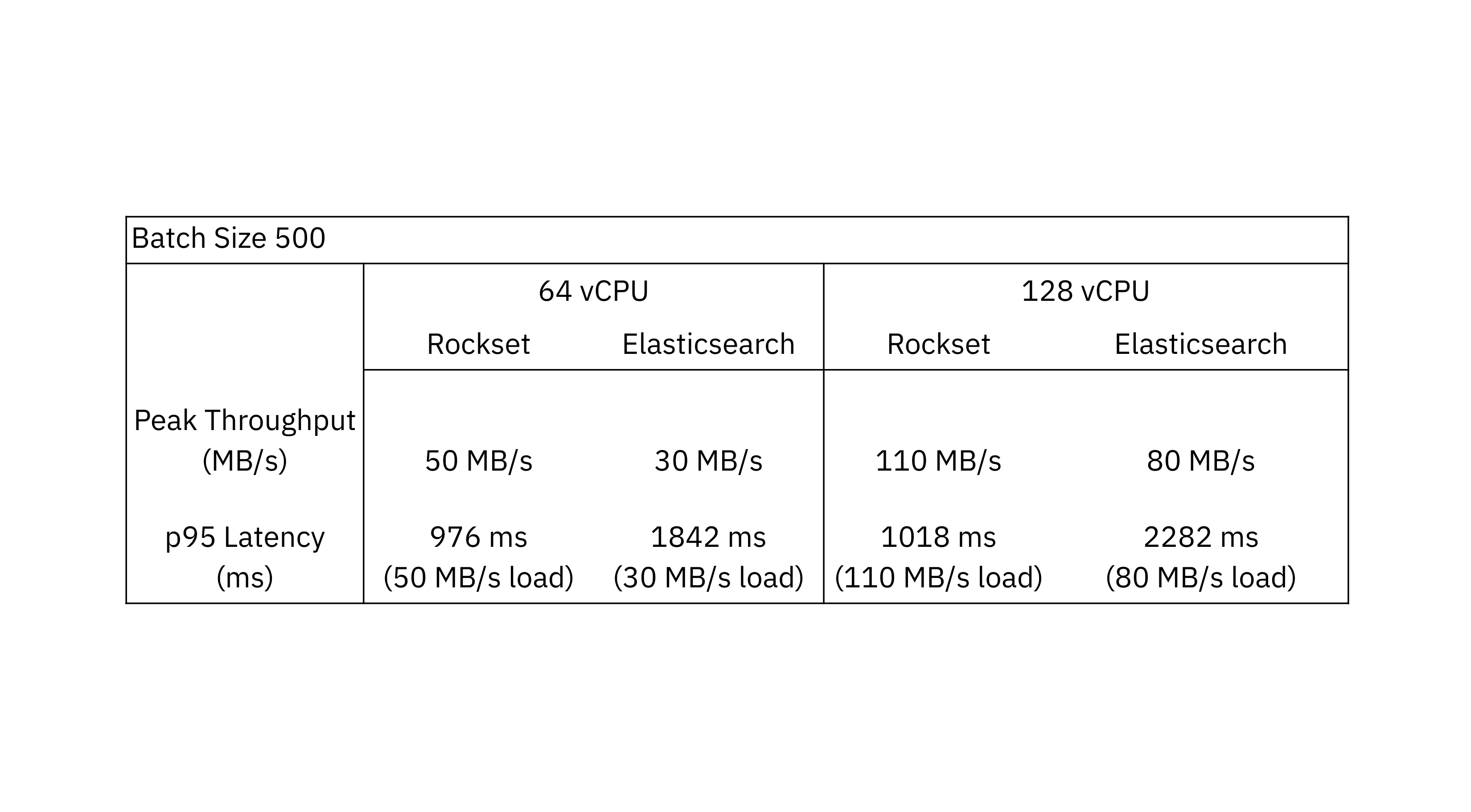
With a batch measurement of 500, Rockset achieves as much as 1.6x greater throughput than Elasticsearch.
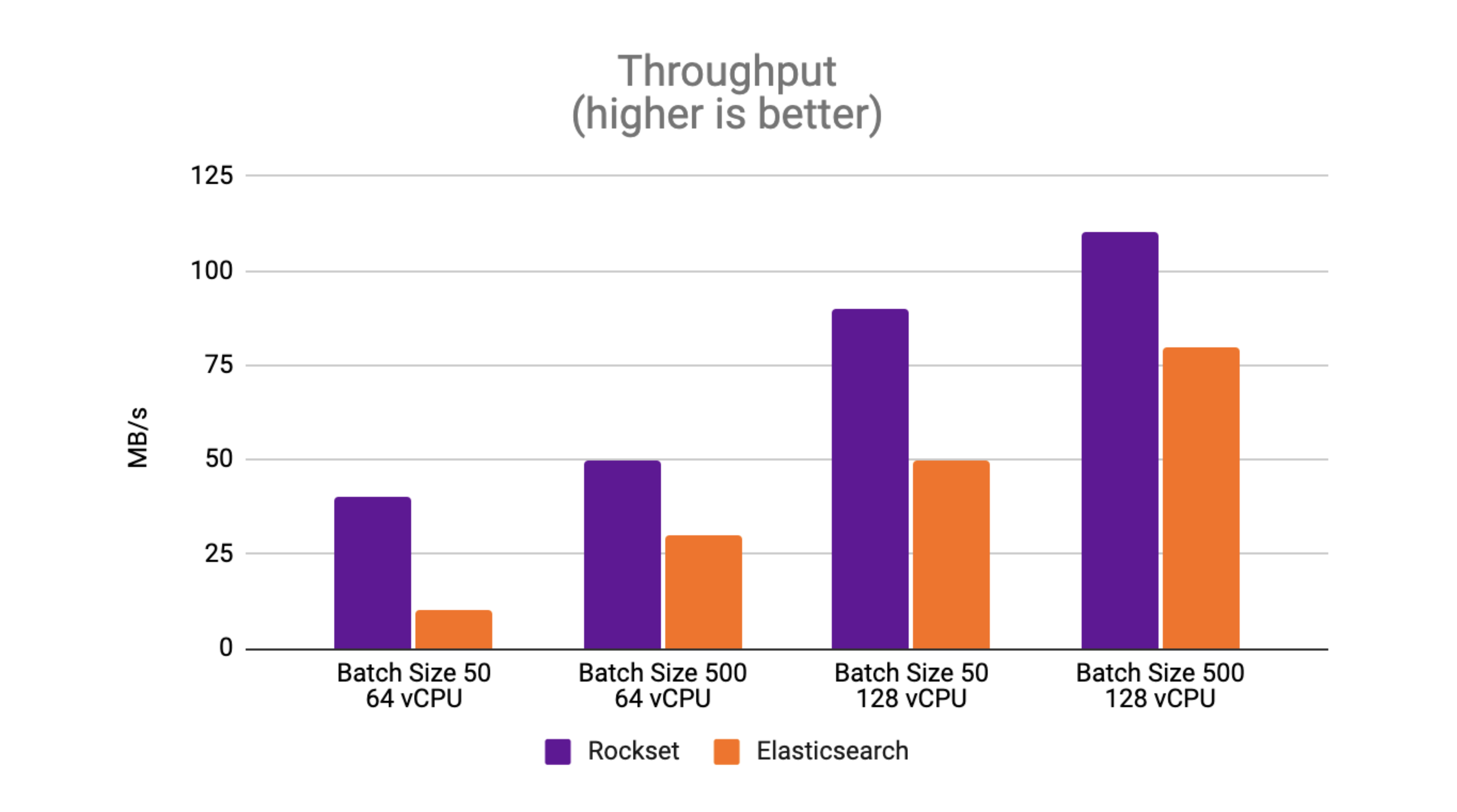
One remark from the efficiency benchmark is that Elasticsearch handles bigger batch sizes higher than smaller batch sizes. The Elastic documentation recommends utilizing bulk requests as they obtain higher efficiency than single-document index requests. Compared to Elasticsearch, Rockset sees higher throughput efficiency with smaller batch sizes because it’s designed to course of incrementally updating streams.
We additionally observe that the height throughput scales linearly as the quantity of assets will increase on Rockset and Elasticsearch. Rockset constantly beats the throughput of Elasticsearch on RockBench, making it higher suited to workloads with excessive write charges.
Knowledge Latency: Rockset sees as much as 2.5x decrease information latency than Elasticsearch
We evaluate Rockset and Elasticsearch end-to-end latency on the highest attainable throughput that every system achieved. To measure the info latency, we begin with a dataset measurement of 1 TB and measure the common information latency over a interval of 45 minutes on the peak throughput.
We see that for a batch measurement of fifty the utmost throughput in Rockset is 90 MB/s and in Elasticsearch is 50 MB/s. When evaluating on a batch measurement of 500, the utmost throughput in Rockset is 110 MB/s and Elasticsearch is 80 MB/s.
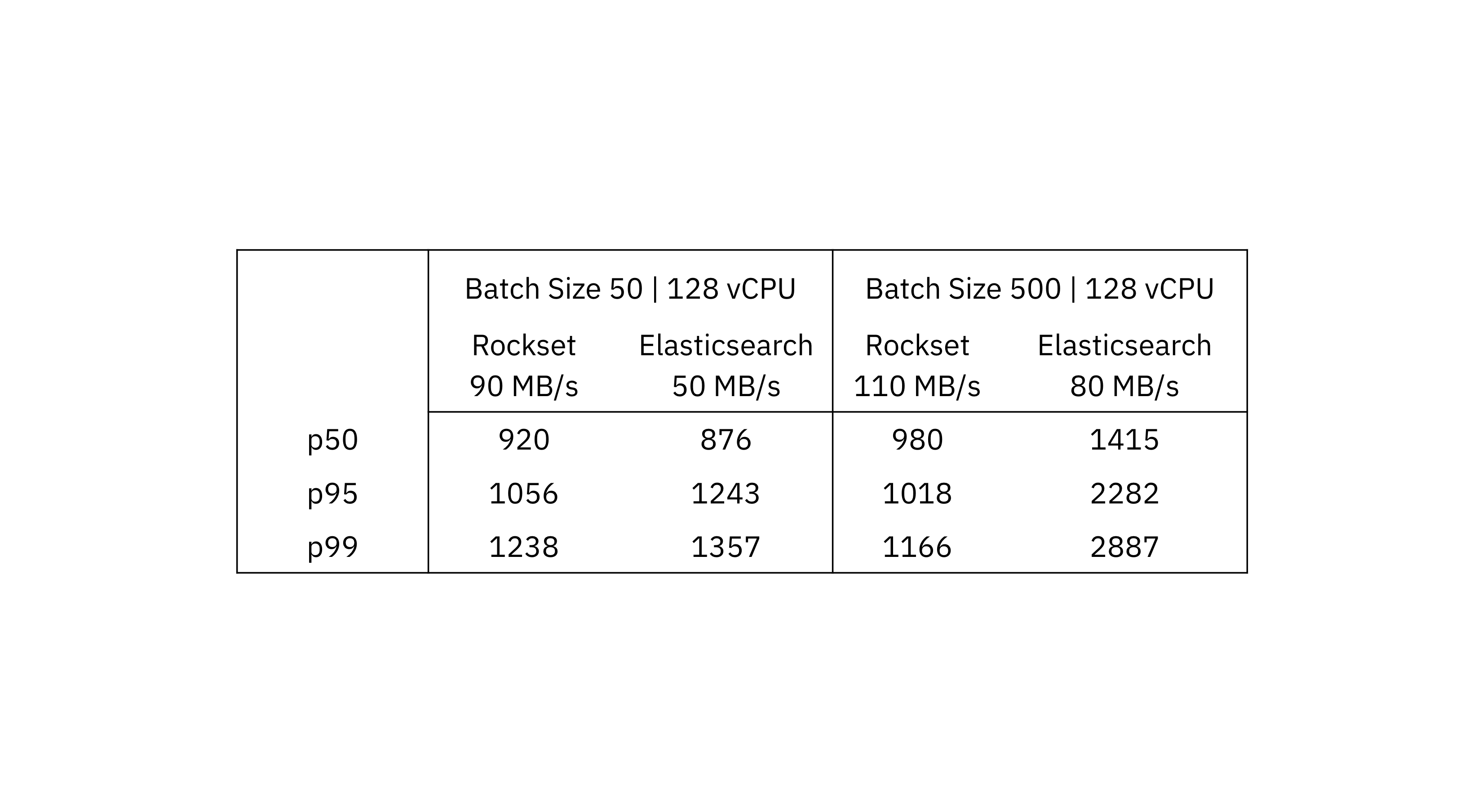
On the ninety fifth and 99th percentiles, Rockset delivers decrease information latency than Elasticsearch on the peak throughput. What you too can see is that the info latency is inside a tighter certain on Rockset in comparison with the delta between p50 and p99 on Elasticsearch.
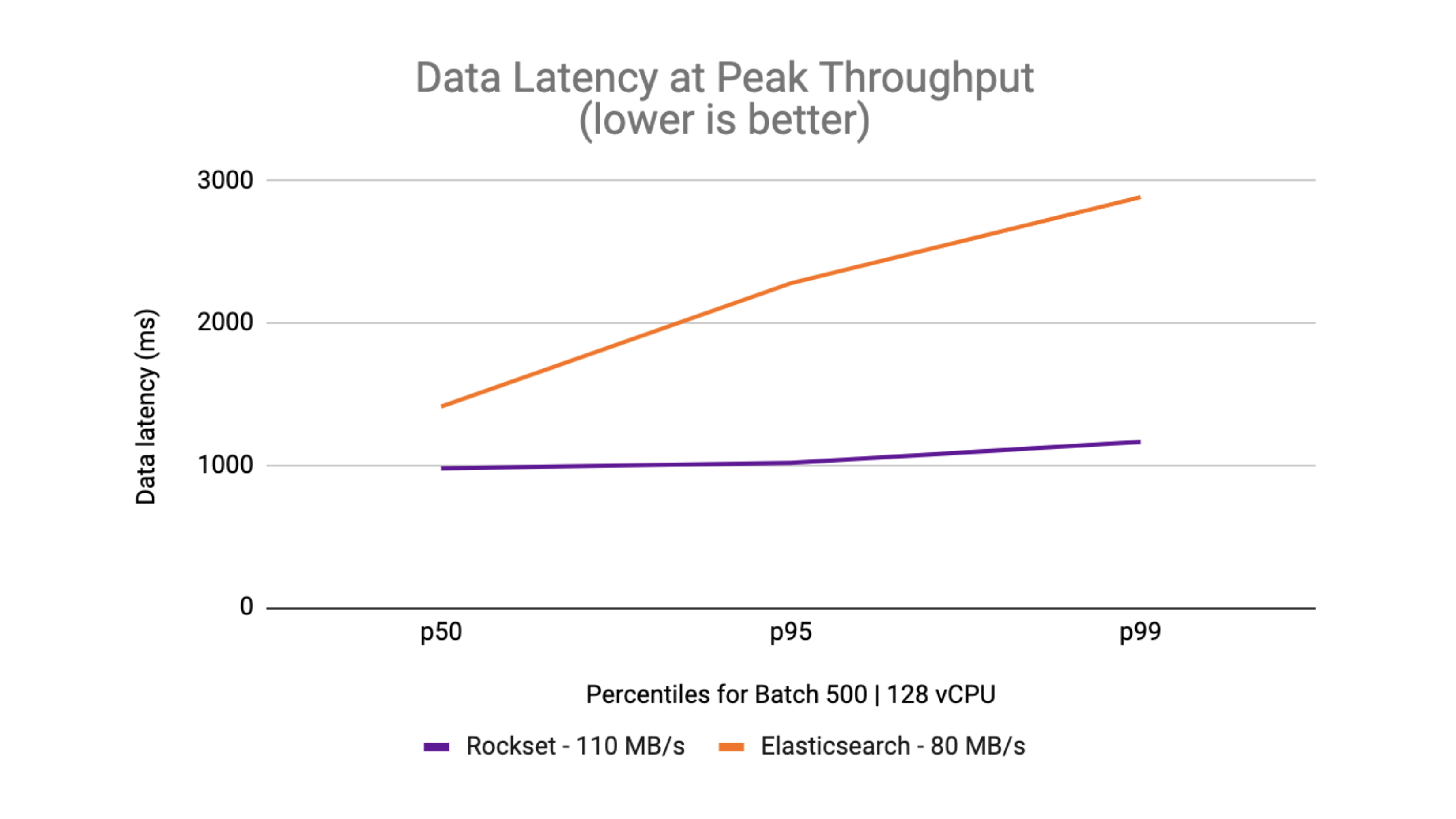
Rockset was in a position to obtain as much as 2.5x decrease latency than Elasticsearch for streaming information ingestion.
How did we do it?: Rockset beneficial properties because of cloud-native effectivity
There have been open questions as as to whether it’s attainable for a database to attain each isolation and real-time efficiency. The de-facto structure for real-time database methods, together with Elasticsearch, is a shared nothing structure the place compute and storage assets are tightly coupled for higher efficiency. With these outcomes, we present that it’s attainable for a disaggregated cloud structure to assist search and analytics on high-velocity streaming information.
One of many tenets of a cloud-native structure is useful resource decoupling, made well-known by compute-storage separation, which gives higher scalability and effectivity. You not have to overprovision assets for peak capability as you’ll be able to scale up and down on demand. And, you’ll be able to provision the precise quantity of storage and compute wanted on your software.
The knock towards decoupled architectures is that they’ve traded off efficiency for isolation. In a shared nothing structure, the tight coupling of assets underpins efficiency; information ingestion and question processing use the identical compute items to make sure that essentially the most not too long ago generated information is accessible for querying. Storage and compute are additionally colocated in the identical nodes for quicker information entry and improved question efficiency.
Whereas tightly coupled architectures made sense previously, they’re not vital because of advances in cloud architectures. Rockset’s compute-storage and compute-compute separation for real-time search and analytics paved the way by isolating streaming ingest compute, question compute and scorching storage from one another. Rockset is ready to guarantee queries entry the latest writes by replicating the in-memory state throughout digital situations, a cluster of compute and reminiscence assets, making the structure well-suited to latency delicate eventualities. Moreover, Rockset creates an elastic scorching storage tier that could be a shared useful resource for a number of purposes.
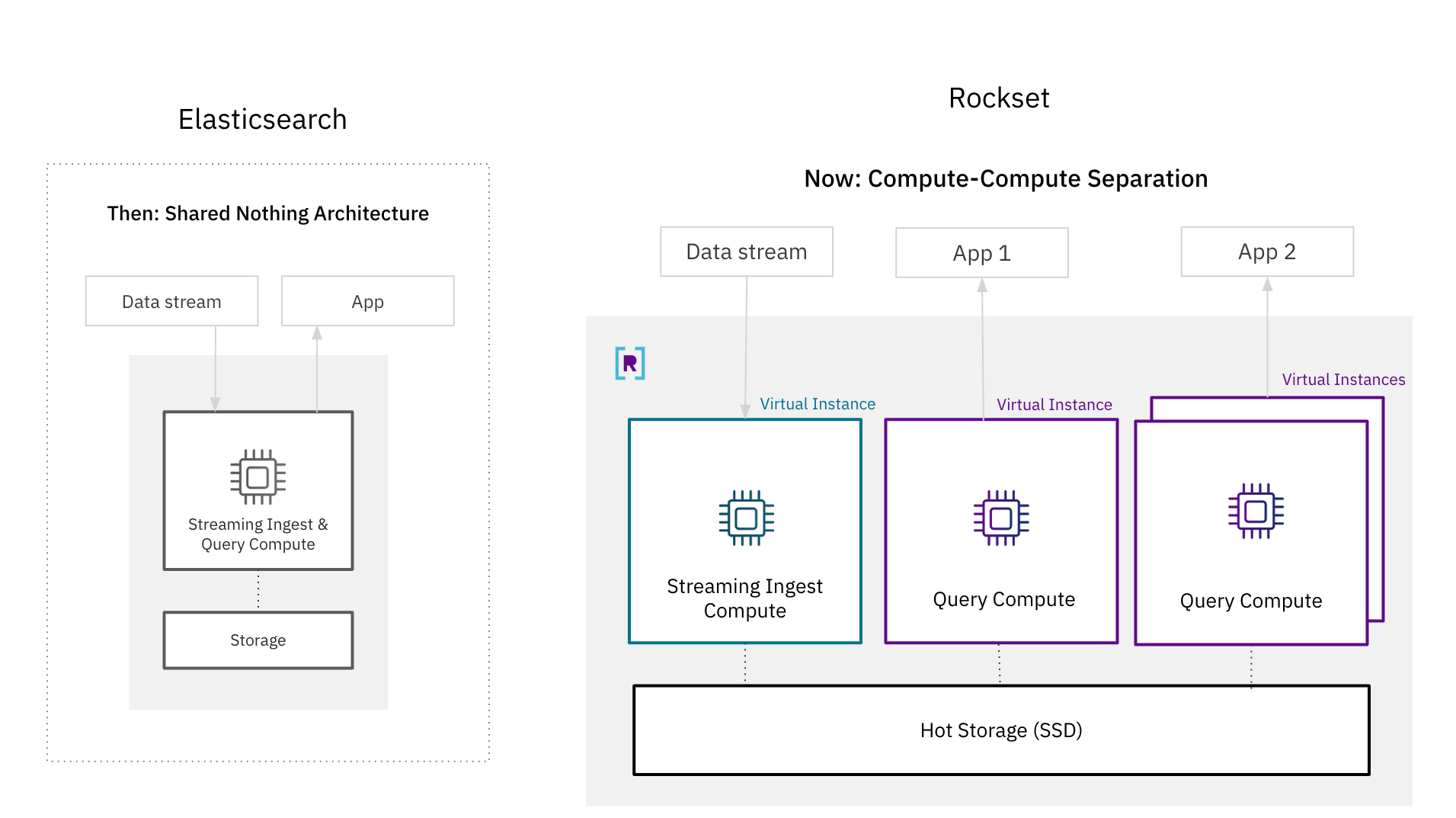
With compute-compute separation, Rockset achieves higher ingest efficiency than Elasticsearch as a result of it solely has to course of incoming information as soon as. In Elasticsearch, which has a primary-backup mannequin for replication, each duplicate must expend compute indexing and compacting newly generated writes. With compute-compute separation, solely a single digital occasion does the indexing and compaction earlier than transferring the newly written information to different situations for software serving. The effectivity beneficial properties from needing to solely course of incoming writes as soon as is why Rockset recorded as much as 4x greater throughput and a pair of.5x decrease end-to-end latency than Elasticsearch on RockBench.
In Abstract: Rockset achieves as much as 4x greater throughput and a pair of.5x decrease latency
On this weblog, we now have walked by the efficiency analysis of Rockset and Elasticsearch for high-velocity information streams and are available to the next conclusions:
Throughput: Rockset helps greater throughput than Elasticsearch, writing incoming streaming information as much as 4x quicker. We got here to this conclusion by measuring the height throughput, or the speed during which information latency begins monotonically rising, on completely different batch sizes and configurations.
Latency: Rockset constantly delivers decrease information latencies than Elasticsearch on the ninety fifth and 99th percentile, making Rockset nicely suited to latency delicate software workloads. Rockset gives as much as 2.5x decrease end-to-end latency than Elasticsearch.
Price/Complexity: We in contrast Rockset and Elasticsearch streaming ingest efficiency on {hardware} assets, utilizing comparable allocations of CPU and reminiscence. We additionally discovered that Rockset gives one of the best worth. For the same value level, you cannot solely get higher efficiency on Rockset however you are able to do away with managing clusters, shards, nodes and indexes. This vastly simplifies operations so your staff can give attention to constructing production-grade purposes.
We ran this efficiency benchmark on Rockset’s subsequent era cloud structure with compute-compute separation. We have been in a position to show that even with the isolation of streaming ingestion compute, question compute and storage Rockset was nonetheless in a position to obtain higher efficiency than Elasticsearch.
If you’re fascinated by studying extra in regards to the efficiency of Rockset and Elasticsearch, watch the tech speak Evaluating Elasticsearch and Rockset Streaming Ingest and Question Efficiency with CTO Dhruba Borthakur and founding engineer and architect Igor Canadi. They delve into the efficiency and architectural variations in better element.
You can too consider Rockset on your personal real-time search and analytics workload by beginning a free trial with $300 in credit. We’ve built-in connectors to Confluent Cloud, Kafka and Kinesis together with a number of OLTP databases to make it straightforward so that you can get began.
Authors: Richard Lin, Software program Engineering and Julie Mills, Product Advertising and marketing