
In December 2022, we introduced our partnership with Isovalent to convey subsequent era prolonged Berkeley Packet Filter (eBPF) dataplane for cloud-native purposes in Microsoft Azure and it was revealed that the subsequent era of Azure Container Community Interface (CNI) dataplane can be powered by eBPF and Cilium.
At the moment, we’re thrilled to announce the overall availability of Azure CNI powered by Cilium. Azure CNI powered by Cilium is a next-generation networking platform that mixes two highly effective applied sciences: Azure CNI for scalable and versatile Pod networking management, built-in with the Azure Digital Community stack, and Cilium, an open-source mission that makes use of eBPF-powered knowledge airplane for networking, safety, and observability in Kubernetes. Azure CNI powered by Cilium takes benefit of Cilium’s direct routing mode inside visitor digital machines and combines it with the Azure native routing contained in the Azure community, enabling improved community efficiency for workloads deployed in Azure Kubernetes Service (AKS) clusters, and with inbuilt assist for imposing networking safety.
On this weblog, we are going to delve additional into the efficiency and scalability outcomes achieved via this highly effective networking providing in Azure Kubernetes Service.
Efficiency and scale outcomes
Efficiency checks are carried out in AKS clusters in overlay mode to research system habits and consider efficiency below heavy load circumstances. These checks simulate situations the place the cluster is subjected to excessive ranges of useful resource utilization, corresponding to giant concurrent requests or excessive workloads. The target is to measure numerous efficiency metrics like response instances, throughput, scalability, and useful resource utilization to know the cluster’s habits and determine any efficiency bottlenecks.
Service routing latency
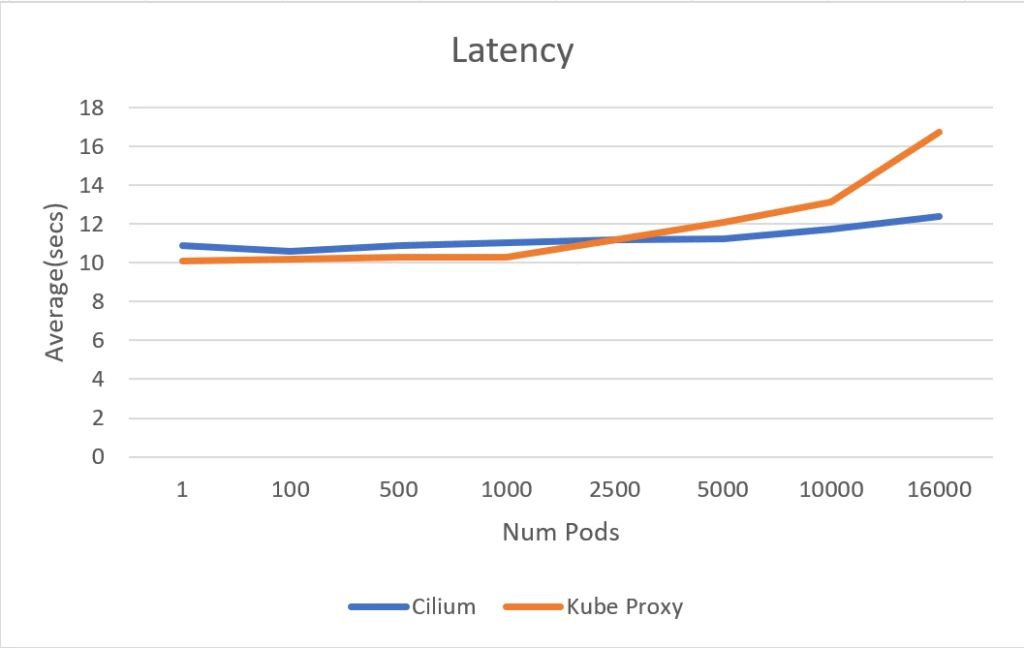
The experiment utilized the Normal D4 v3 SKU nodepool (16 GB mem, 4 vCPU) in an AKS cluster. The apachebench instrument, generally used for benchmarking and cargo testing internet servers, was used for measuring service routing latency. A complete of fifty,000 requests have been generated and measured for total completion time. It has been noticed that the service routing latency of Azure CNI powered by Cilium and kube-proxy initially exhibit comparable efficiency till the variety of pods reaches 5000. Past this threshold, the latency for the service routing for kube-proxy primarily based cluster begins to extend, whereas it maintains a constant latency stage for Cilium primarily based clusters.
Notably, when scaling as much as 16,000 pods, the Azure CNI powered by Cilium cluster demonstrates a major enchancment with a 30 p.c discount in service routing latency in comparison with the kube-proxy cluster. These outcomes reconfirm that eBPF primarily based service routing performs higher at scale in comparison with IPTables primarily based service routing utilized by kube-proxy.
Service routing latency in seconds
Scale check efficiency
The size check was carried out in an Azure CNI powered by Cilium Azure Kubernetes Service cluster, using the Normal D4 v3 SKU nodepool (16 GB mem, 4 vCPU). The aim of the check was to judge the efficiency of the cluster below excessive scale circumstances. The check targeted on capturing the central processing unit (CPU) and reminiscence utilization of the nodes, in addition to monitoring the load on the API server and Cilium.
The check encompassed three distinct situations, every designed to evaluate totally different features of the cluster’s efficiency below various circumstances.
Scale check with 100k pods with no community coverage
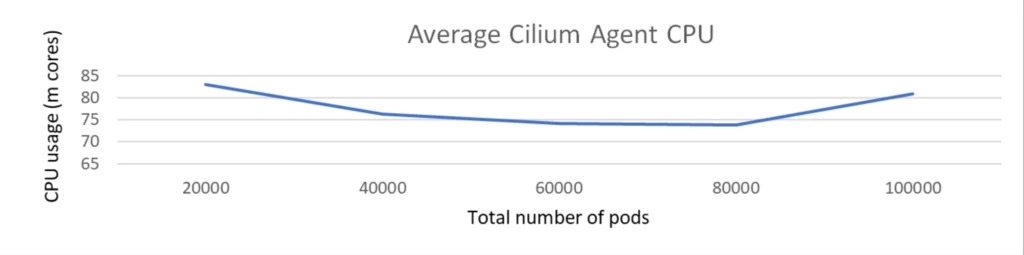
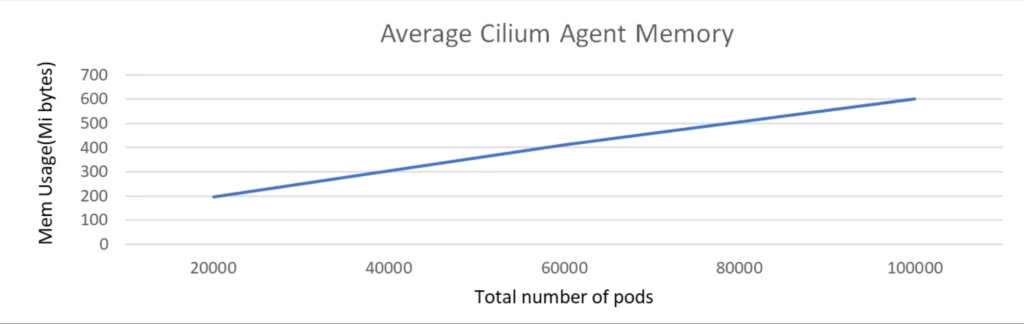
The size check was executed with a cluster comprising 1k nodes and a complete of 100k pods. The check was carried out with none community insurance policies and Kubernetes providers deployed.
Throughout the scale check, because the variety of pods elevated from 20K to 100K, the CPU utilization of the Cilium agent remained persistently low, not exceeding 100 milli cores and reminiscence is round 500 MiB.
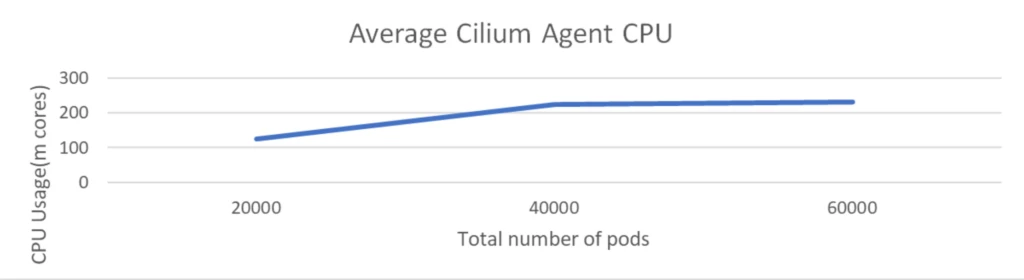
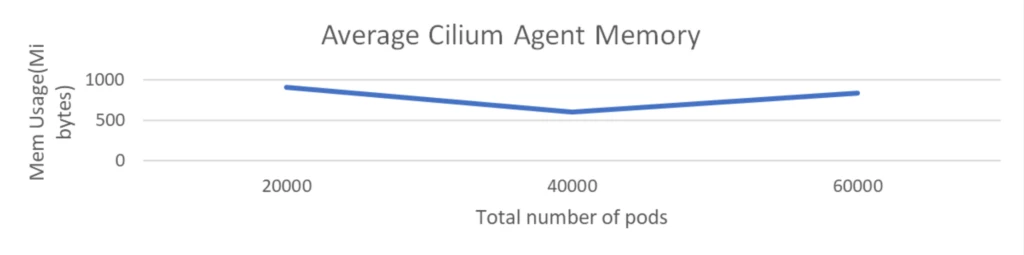
Scale check with 100k pods with 2k community insurance policies
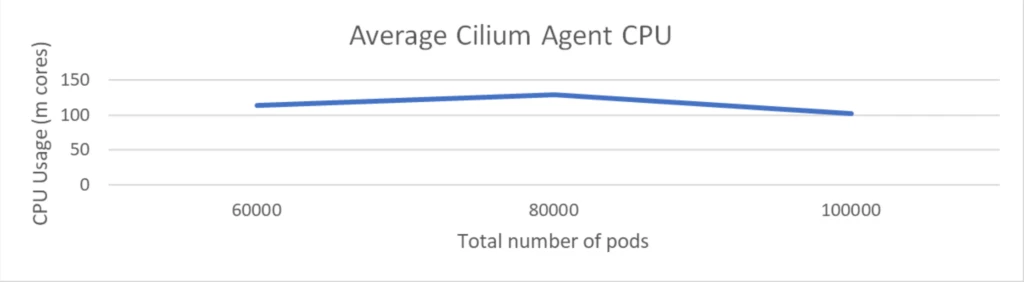
The size check was executed with a cluster comprising 1K nodes and a complete of 100K pods. The check concerned the deployment of 2K community insurance policies however didn’t embody any Kubernetes providers.
The CPU utilization of the Cilium agent remained below 150 milli cores and reminiscence is round 1 GiB. This demonstrated that Cilium maintained low overhead despite the fact that the variety of community insurance policies obtained doubled.
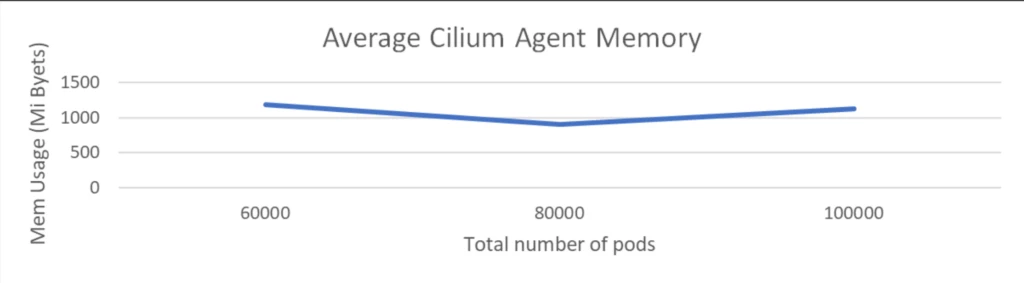
Scale check with 1k providers with 60k pods backend and 2k community insurance policies
This check is executed with 1K nodes and 60K pods, accompanied by 2K community insurance policies and 1K providers, every having 60 pods related to it.
The CPU utilization of the Cilium agent remained at round 200 milli cores and reminiscence stays at round 1 GiB. This demonstrates that Cilium continues to take care of low overhead even when giant variety of providers obtained deployed and as we have now seen beforehand service routing through eBPF supplies important latency good points for purposes and it’s good to see that’s achieved with very low overhead at infra layer.
Get began with Azure CNI powered by Cilium
To wrap up, as evident from above outcomes, Azure CNI with eBPF dataplane of Cilium is most performant and scales significantly better with nodes, pods, providers, and community insurance policies whereas holding overhead low. This product providing is now usually out there in Azure Kubernetes Service (AKS) and works with each Overlay and VNET mode for CNI. We’re excited to ask you to strive Azure CNI powered by Cilium and expertise the advantages in your AKS surroundings.
To get began at the moment, go to the documentation out there on Azure CNI powered by Cilium.