
![[Big Book of MLOps Updated for Generative AI]](https://www.databricks.com/static/og-databricks-58419d0d868b05ddb057830066961ebe.png "[Big Book of MLOps Updated for Generative AI]")
Final 12 months, we revealed the Huge E book of MLOps, outlining guiding rules, design issues, and reference architectures for Machine Studying Operations (MLOps). Since then, Databricks has added key options simplifying MLOps, and Generative AI has introduced new necessities to MLOps platforms and processes. We’re excited to announce a brand new model of the Huge E book of MLOps masking these product updates and Generative AI necessities.
This weblog publish highlights key updates within the eBook, which may be downloaded right here. We offer updates on governance, serving, and monitoring and focus on the accompanying design choices to make. We mirror these updates in improved reference architectures. We additionally embody a brand new part on LLMOps (MLOps for Massive Language Fashions), the place we focus on implications on MLOps, key elements of LLM-powered functions, and LLM-specific reference architectures.
This weblog publish and eBook can be helpful to ML Engineers, ML Architects, and different roles seeking to perceive the most recent in MLOps and the affect of Generative AI on MLOps.
Huge E book v1 recap
When you have not learn the unique Huge E book of MLOps, this part offers a short recap. The identical motivations, guiding rules, semantics, and deployment patterns kind the premise of our up to date MLOps greatest practices.
Why ought to I care about MLOps?
We hold our definition of MLOps as a set of processes and automation to handle knowledge, code and fashions to fulfill the 2 objectives of steady efficiency and long-term effectivity in ML techniques.
MLOps = DataOps + DevOps + ModelOps
In our expertise working with prospects like CareSource and Walgreens, implementing MLOps architectures accelerates the time to manufacturing for ML-powered functions, reduces the chance of poor efficiency and non-compliance, and reduces long-term upkeep burdens on Information Science and ML groups.
Guiding rules
Our guiding rules stay the identical:
- Take a data-centric strategy to machine studying.
- At all times hold what you are promoting objectives in thoughts.
- Implement MLOps in a modular style.
- Course of ought to information automation.
The primary precept, taking a data-centric strategy, lies on the coronary heart of the updates within the eBook. As you learn beneath, you will notice how our “Lakehouse AI” philosophy unifies knowledge and AI at each the governance and mannequin/pipeline layers.
Semantics of improvement, staging and manufacturing
We construction MLOps when it comes to how ML belongings—code, knowledge, and fashions—are organized into phases from improvement, to staging, and to manufacturing. These phases correspond to steadily stricter entry controls and stronger high quality ensures.

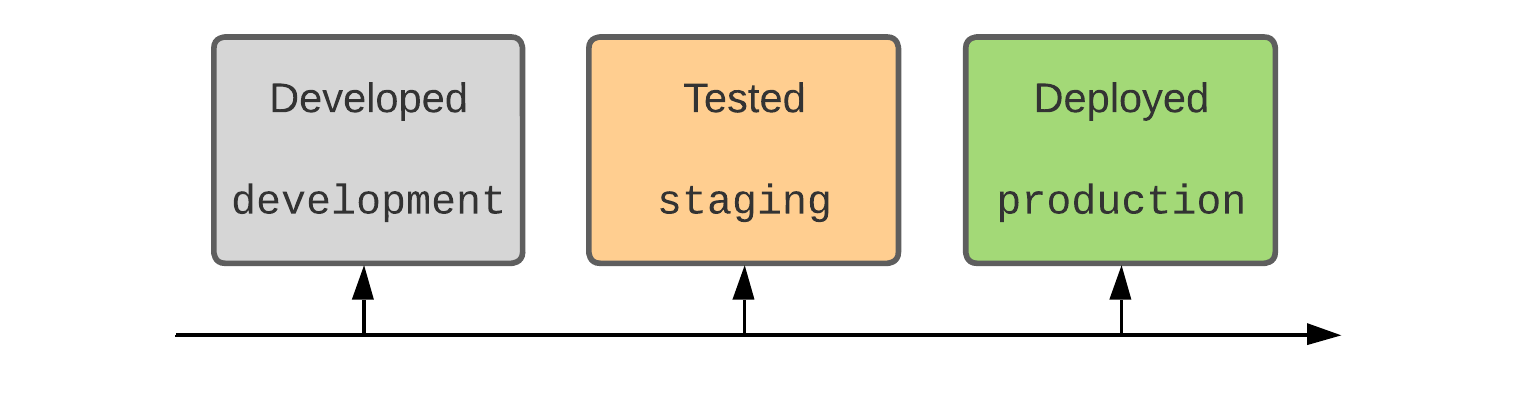
ML deployment patterns
We mentioned how code and/or fashions are deployed from improvement in direction of manufacturing, and the tradeoffs in deploying code, fashions, or each. We present architectures for deploying code, however our steerage stays largely the identical for deploying fashions.
For extra particulars on any of those matters, please consult with the unique eBook.
What’s new?
On this part, we define the important thing product options that enhance our MLOps structure. For every of those, we spotlight the advantages they carry and their affect on our end-to-end MLOps workflow.
Unity Catalog
An information-centric AI platform should present unified governance for each knowledge and AI belongings on high of the Lakehouse. Databricks Unity Catalog centralizes entry management, auditing, lineage, and knowledge discovery capabilities throughout Databricks workspaces.
Unity Catalog now consists of MLflow Fashions and Characteristic Engineering. This unification permits less complicated administration of AI tasks which embody each knowledge and AI belongings. For ML groups, this implies extra environment friendly entry and scalable processes, particularly for lineage, discovery, and collaboration. For directors, this implies less complicated governance at venture or workflow degree.
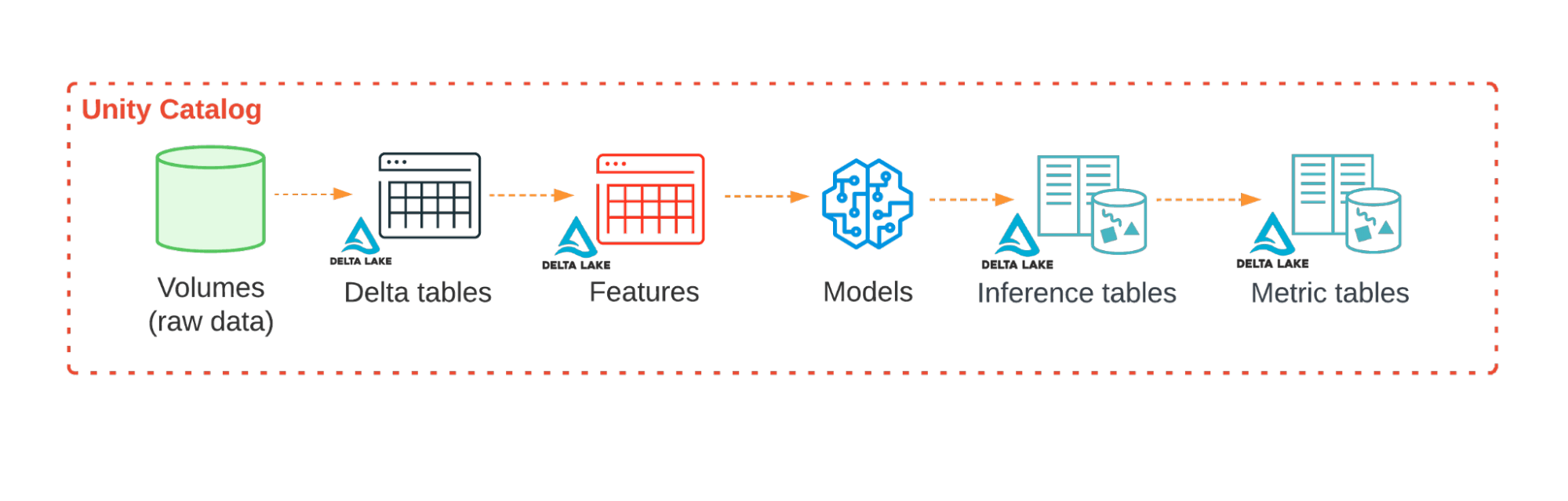
Property of an ML workflow, all managed through Unity Catalog, throughout a number of workspaces
Inside Unity Catalog, a given catalog accommodates schemas, which in flip could include tables, volumes, features, fashions, and different belongings. Fashions can have a number of variations and may be tagged with aliases. Within the eBook, we offer really useful group schemes for AI tasks on the catalog and schema degree, however Unity Catalog has the pliability to be tailor-made to any group’s current practices.
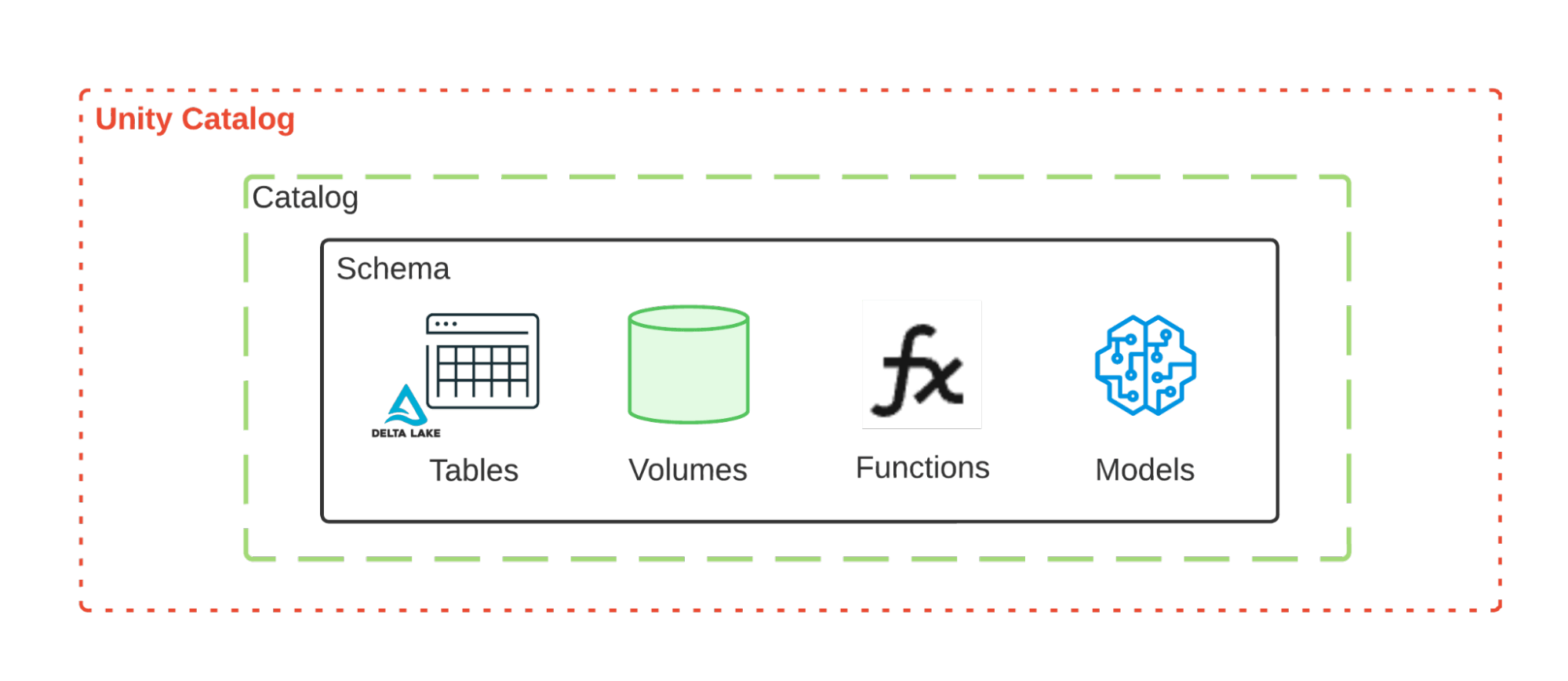
Mannequin Serving
Databricks Mannequin Serving offers a production-ready, serverless answer to simplify real-time mannequin deployment, behind APIs to energy functions and web sites. Mannequin Serving reduces operational prices, streamlines the ML lifecycle, and makes it simpler for Information Science groups to deal with the core activity of integrating production-grade real-time ML into their options.
Within the eBook, we focus on two key design resolution areas:
- Pre-deployment testing ensures good system efficiency and customarily consists of deployment readiness checks and cargo testing.
- Actual-time mannequin deployment ensures good mannequin accuracy (or different ML efficiency metrics). We focus on methods together with A/B testing, gradual rollout, and shadow deployment.
We additionally focus on implementation particulars in Databricks, together with:
Lakehouse Monitoring
Databricks Lakehouse Monitoring is a data-centric monitoring answer to make sure that each knowledge and AI belongings are of top of the range and dependable. Constructed on high of Unity Catalog, it offers the distinctive skill to implement each knowledge and mannequin monitoring, whereas sustaining lineage between the info and AI belongings of an MLOps answer. This unified and centralized strategy to monitoring simplifies the method of diagnosing errors, detecting high quality drift, and performing root trigger evaluation.
The eBook discusses implementation particulars in Databricks, together with:
MLOps Stacks and Databricks asset bundles
MLOps Stacks are up to date infrastructure-as-code options which assist to speed up the creation of MLOps architectures. This repository offers a customizable stack for beginning new ML tasks on Databricks, instantiating pipelines for mannequin coaching, mannequin deployment, CI/CD, and others.
MLOps Stacks are constructed on high of Databricks asset bundles, which outline infrastructure-as-code for knowledge, analytics, and ML. Databricks asset bundles can help you validate, deploy, and run Databricks workflows equivalent to Databricks jobs and Delta Stay Tables, and to handle ML belongings equivalent to MLflow fashions and experiments.
Reference architectures
The up to date eBook offers a number of reference architectures:
- Multi-environment view: This high-level view reveals how the event, staging, and manufacturing environments are tied collectively and work together.
- Growth: This diagram zooms in on the event means of ML pipelines.
- Staging: This diagram explains the unit assessments and integration assessments for ML pipelines.
- Manufacturing: This diagram particulars the goal state, displaying how the varied ML pipelines work together.
Beneath, we offer a multi-environment view. A lot of the structure stays the identical, however it’s now even simpler to implement with the most recent updates from Databricks.
- High-to-bottom: The three layers present code in Git (high) vs. workspaces (center) vs. Lakehouse belongings in Unity Catalog (backside).
- Left-to-right: The three phases are proven in three totally different workspaces; that’s not a strict requirement however is a standard approach to separate phases from improvement to manufacturing. The identical set of ML pipelines and companies are utilized in every stage, initially developed (left) earlier than being examined in staging (center) and at last deployed to manufacturing (proper).
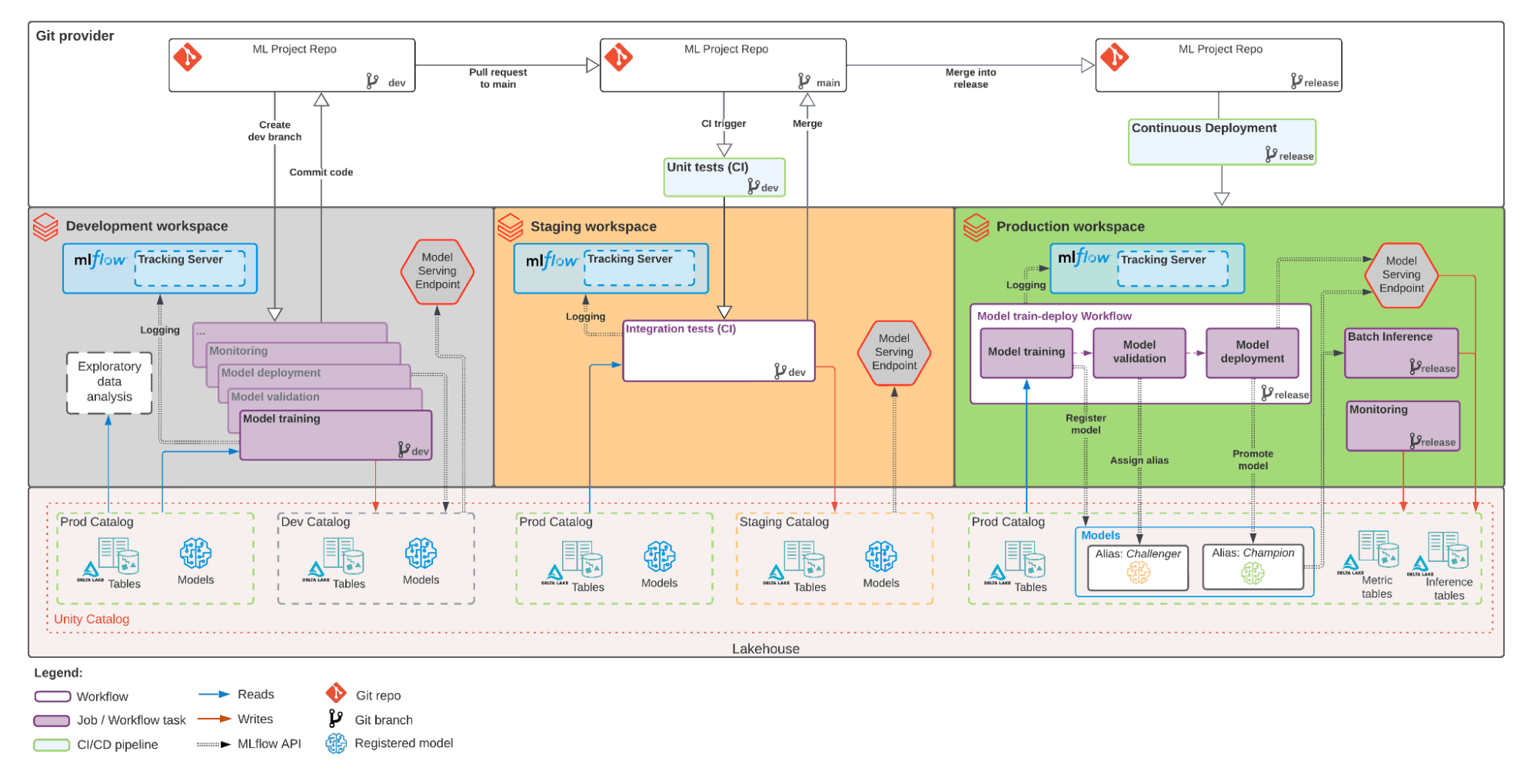
The primary architectural replace is that each knowledge and ML belongings are managed as Lakehouse belongings within the Unity Catalog. Word that the large enhancements to Mannequin Serving and Lakehouse Monitoring haven’t modified the structure, however make it less complicated to implement.
LLMOps
We finish the up to date eBook with a brand new part on LLMOps, or MLOps for Massive Language Fashions (LLMs). We converse when it comes to “LLMs,” however many greatest practices translate to different Generative AI fashions as properly. We first focus on main adjustments launched by LLMs after which present detailed greatest practices round key elements of LLM-powered functions. The eBook additionally offers reference architectures for frequent Retrieval-Augmented Era (RAG) functions.
What adjustments with LLMs?
The desk beneath is an abbreviated model of the eBook desk, which lists key properties of LLMs and their implications for MLOps platforms and practices.
| Key properties of LLMs | Implications for MLOps |
|---|---|
Implications for MLOps
|
Growth course of: Tasks usually develop incrementally, ranging from current, third-party or open supply fashions and ending with customized fashions (fine-tuned or totally skilled on curated knowledge). |
| Many LLMs take common queries and directions as enter. These queries can include rigorously engineered “prompts” to elicit the specified responses. |
Growth course of: Immediate engineering is a brand new necessary a part of creating many AI functions. Packaging ML artifacts: LLM “fashions” could also be numerous, together with API calls, immediate templates, chains, and extra. |
| Many LLMs may be given prompts with examples or context. | Serving infrastructure: When augmenting LLM queries with context, it’s helpful to make use of instruments equivalent to vector databases to seek for related context. |
| Proprietary and OSS fashions can be utilized through paid APIs. | API governance: It is very important have a centralized system for API governance of price limits, permissions, quota allocation, and value attribution. |
| LLMs are very massive deep studying fashions, usually starting from gigabytes to lots of of gigabytes. |
Serving infrastructure: GPUs and quick storage are sometimes important. Value/efficiency trade-offs: Specialised methods for decreasing mannequin dimension and computation have turn out to be extra necessary. |
| LLMs are exhausting to judge through conventional ML metrics since there’s usually no single “proper” reply. | Human suggestions: This suggestions must be included immediately into the MLOps course of, together with testing, monitoring, and capturing to be used in future fine-tuning. |
Key elements of LLM-powered functions
The eBook features a part for every subject beneath, with detailed explanations and hyperlinks to assets.
- Immediate engineering: Although many prompts are particular to particular person LLM fashions, we give some suggestions which apply extra typically.
- Leveraging your individual knowledge: We offer a desk and dialogue of the continuum from easy (and quick) to complicated (and highly effective) for utilizing your knowledge to realize a aggressive edge with LLMs. This ranges from immediate engineering, to retrieval augmented technology (RAG), to fine-tuning, to full pre-training.
- Retrieval augmented technology (RAG): We focus on this most typical sort of LLM utility, together with its advantages and the everyday workflow.
- Vector database: We focus on vector indexes vs. vector libraries vs. vector databases, particularly for RAG workflows.
- Wonderful-tuning LLMs: We focus on variants of fine-tuning, when to make use of it, and state-of-the-art methods for scalable and resource-efficient fine-tuning.
- Pre-training: We focus on when to go for full-on pre-training and reference state-of-the artwork methods for dealing with challenges. We additionally strongly encourage the usage of MosaicML Coaching, which robotically handles most of the complexities of scale.
- Third-party APIs vs. self-hosted fashions: We focus on the tradeoffs round knowledge safety and privateness, predictable and steady habits, and vendor lock-in.
- Mannequin analysis: We contact on the challenges on this nascent discipline and focus on benchmarks, utilizing LLMs as evaluators, and human analysis.
- Packaging fashions or pipelines for deployment: With LLM functions utilizing something from API calls to immediate templates to complicated chains, we offer recommendation on utilizing MLflow Fashions to standardize packaging for deployment.
- LLM Inference: We offer suggestions round real-time inference and batch inference, together with utilizing massive fashions.
- Managing price/efficiency trade-offs: With LLMs being massive fashions, we dedicate this part to decreasing prices and enhancing efficiency, particularly for inference.
Get began updating your MLOps structure
This weblog is merely an summary of the reasons, greatest practices, and architectural steerage within the full eBook. To be taught extra and to get began on updating your MLOps platform and practices, we suggest that you just:
- Learn the up to date Huge E book of MLOps. All through the eBook, we offer hyperlinks to assets for particulars and for studying extra about particular matters.
- Compensate for the Information+AI Summit 2023 talks on MLOps, together with:
- Learn and watch about success tales:
- Communicate along with your Databricks account workforce, who can information you thru a dialogue of your necessities, assist to adapt this reference structure to your tasks, and interact extra assets as wanted for coaching and implementation.