

Introduction
Insurance coverage is a document-heavy trade with quite a few phrases and circumstances, making it difficult for policyholders to search out correct solutions to their queries relating to coverage particulars or the claims course of. This typically results in greater buyer churn as a result of frustration and misinformation. This text explores the way to deal with this difficulty utilizing Generative AI by constructing an end-to-end Retrieval-Augmented Era (RAG) chatbot for insurance coverage. We name it IVA(Insurance coverage Digital Agent), which is constructed over the sturdy AWS stack.
Studying Outcomes
- Learn the way RAG enhances chatbot interactions, particularly in document-heavy industries like insurance coverage.
- Achieve expertise in integrating AWS providers reminiscent of Bedrock, Lambda, and S3 for environment friendly doc processing and retrieval.
- Discover the LangChain framework to enhance the accuracy and movement of chatbot conversations.
- Learn to deploy a user-friendly chatbot utilizing Streamlit on an EC2 occasion.
- Perceive the method and limitations of constructing a prototype RAG chatbot for the insurance coverage sector.
- Uncover how superior AI can considerably enhance buyer expertise and operational effectivity in insurance coverage.
- Constructing an Finish-to-Finish Gen AI RAG chatbot for insurance coverage.
This text was printed as part of the Information Science Blogathon.
What’s a RAG Chatbot?
A Retrieval-Augmented Era chatbot is a classy AI device that enhances consumer interactions by integrating doc retrieval with pure language technology. As an alternative of solely producing responses from a pre-trained mannequin, an RAG chatbot retrieves related data from a database or doc set. It then makes use of this data to craft detailed and correct solutions. This twin method ensures that customers obtain extremely contextual and exact data tailor-made to their queries.
Answer Overview
- When a coverage is issued, the coverage doc is saved in an S3 bucket.
- An S3 notification triggers a Lambda perform upon doc add. This perform tokenizes the doc, generates vector embeddings through AWS Bedrock, and creates an index utilizing FAISS, which is then saved again to S3.
- When a consumer queries the chatbot, it retrieves the related vector index primarily based on the coverage quantity. The chatbot then makes use of this index and the consumer’s question, processed via a Massive Language Mannequin (LLM) with AWS Bedrock and LangChain, to generate an correct response.
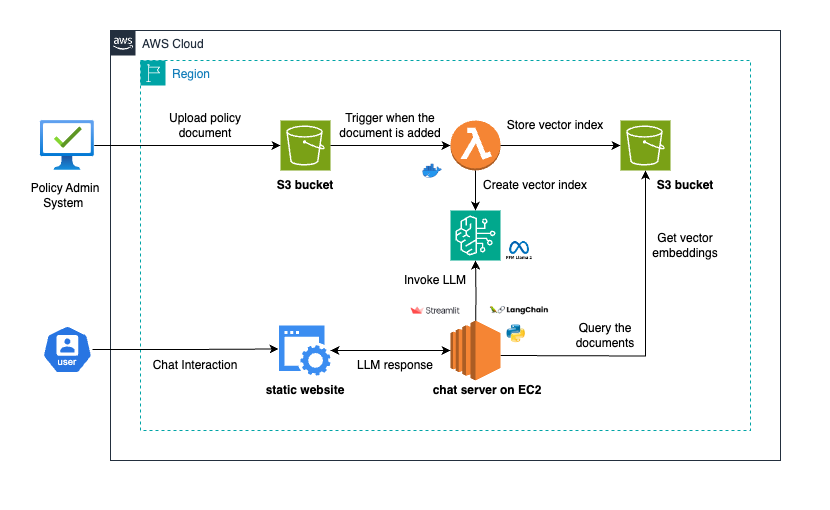
Technical Overview
We are able to divide the answer into three modules to develop and clarify it agilely relatively than deal with all of it concurrently.
Module1: Spin Up Required AWS Sources
This module will concentrate on establishing the mandatory AWS infrastructure. We’ll use TypeScript to create the stack and develop a Lambda perform utilizing Python. To get began, clone the repository and evaluate the stack. Nevertheless, suppose you’re new to this course of and need to acquire a deeper understanding. In that case, I extremely advocate initializing a clean TypeScript CDK undertaking and including the required assets step-by-step.
S3 Bucket for Static Web site
Create an S3 bucket to host the static web site, configure public learn entry, and deploy the web site content material. We are going to use this static web page as a touchdown web page for the insurance coverage firm and entry the chatbot.
const siteBucket = new s3.Bucket(this, 'MyStaticSiteBucket', {
bucketName: "secure-insurance-website",
websiteIndexDocument: 'index.html',
autoDeleteObjects: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: { /* ... */ }
});
siteBucket.addToResourcePolicy(new iam.PolicyStatement({
impact: iam.Impact.ALLOW,
actions: ['s3:GetObject'],
principals: [new iam.AnyPrincipal()],
assets: [siteBucket.arnForObjects('*')],
}));
new s3deploy.BucketDeployment(this, 'DeployStaticSite', {
sources: [s3deploy.Source.asset('./website')],
destinationBucket: siteBucket,
});#import csvS3 Bucket for Doc Storage
Create an S3 bucket to retailer coverage paperwork and the vectors.
const sourceBucket = new s3.Bucket(this, 'RagSourceBucket', {
bucketName: 'rag-bot-source',
removalPolicy: cdk.RemovalPolicy.DESTROY,
});#import csvIAM Position for Lambda
Create an IAM function with permissions for S3 and AWS Bedrock operations
const lambdaRole = new iam.Position(this, 'LambdaRole', {
assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'),
});
lambdaRole.addToPolicy(new iam.PolicyStatement({
actions: ['s3:GetObject', 's3:PutObject'],
assets: [sourceBucket.bucketArn + '/*'],
}));
lambdaRole.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'));
lambdaRole.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonBedrockFullAccess'));#import csvDocker-Primarily based Lambda Operate
Outline a Lambda perform utilizing a Docker picture that processes paperwork:
const dockerFunc = new lambda.DockerImageFunction(this, "DockerFunc", {
code: lambda.DockerImageCode.fromImageAsset("./picture"),
memorySize: 1024,
timeout: cdk.Period.seconds(20),
structure: lambda.Structure.X86_64,
function: lambdaRole,
});
sourceBucket.addEventNotification(s3.EventType.OBJECT_CREATED, new s3n.LambdaDestination(dockerFunc), {
prefix: 'docs/',
});#import csvDeploy the assets
As soon as the event is accomplished, the stack might be deployed to AWS utilizing the under instructions. ( Assuming the CDK is already configured)
npm set up -g aws-cdk
cdk bootstrap aws://YOUR-AWS-ACCOUNT-ID/YOUR-AWS-REGION
cdk deploy#import csvPlease notice - we must replace the chat server URL within the index.html file as soon as we deploy the chatbot to AWS (Module 3).
Earlier than continuing with Module 2, it’s essential to notice that entry to the required foundational mannequin within the AWS Bedrock console have to be requested. With out this entry, the chatbot gained’t be capable to make the most of the bedrock fashions. Subsequently, be certain that the mandatory permissions are granted beforehand to make sure seamless integration with AWS Bedrock providers.
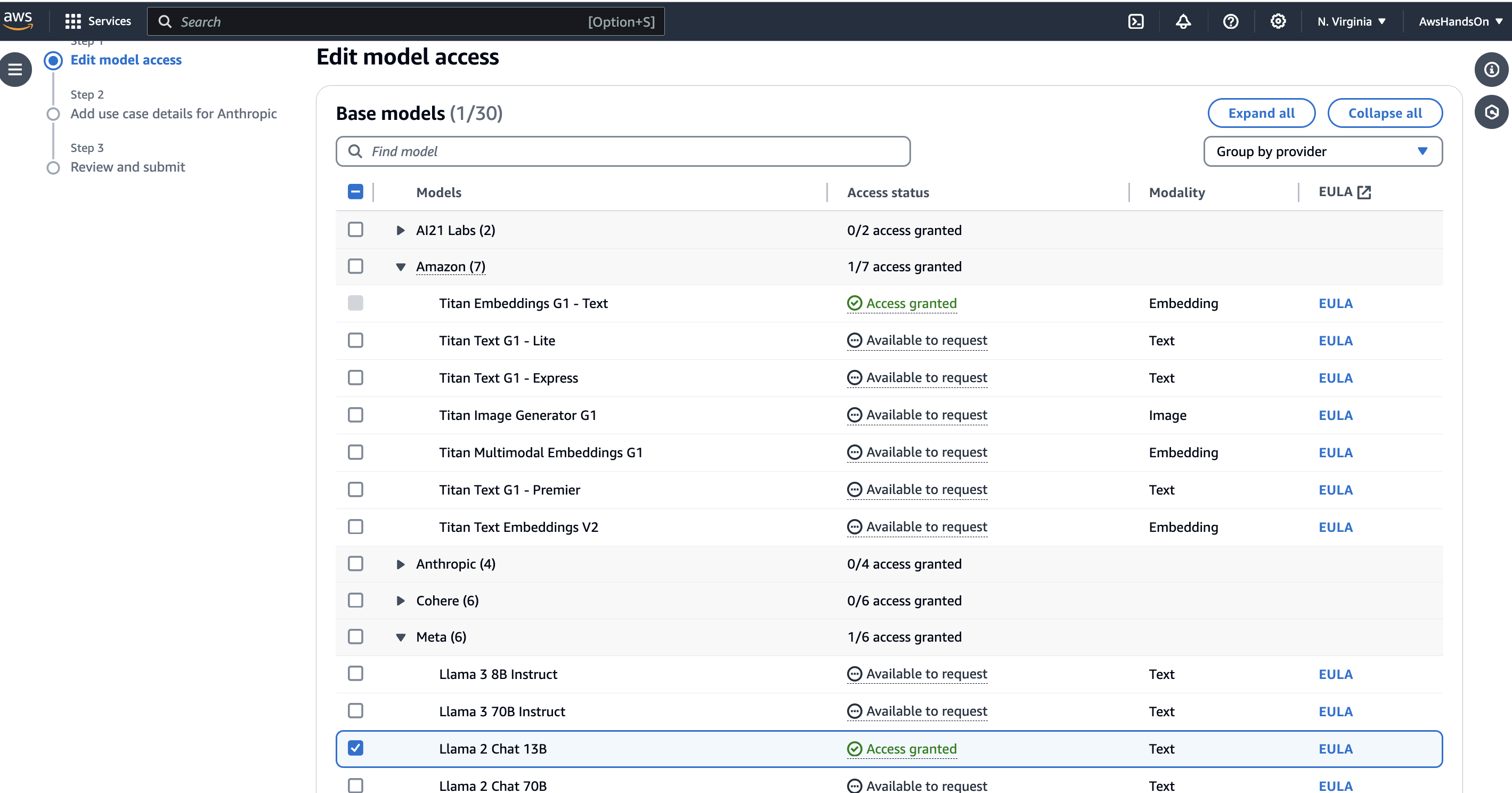
Module2: Lambda Operate for Producing the Vector Embeddings
This Lambda perform performs a vital function in producing vector embeddings for coverage paperwork, a basic step in enabling the RAG chatbot to supply correct responses. Let’s break down its performance:
Configuration and Initialization
Earlier than diving into the code, we configure connections to AWS providers and initialize the Titan Embeddings Mannequin, important for producing vector embeddings:
bedrock = boto3.consumer(service_name="bedrock-runtime")
bedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1", consumer=bedrock)
s3 = boto3.consumer("s3")#import csvHandler Operate
The handler perform is the entry level for the Lambda execution. Right here, we extract the mandatory data from the S3 occasion set off and put together for doc processing:
def handler(occasion, context):
key = occasion['Records'][0]['s3']['object']['key']
key = key.exchange('+', ' ')
policy_number = key.cut up('_')[-1].cut up('.')[0]
file_name_full = key.cut up("https://www.analyticsvidhya.com/")[-1]
s3.download_file(BUCKET_NAME, key, f"/tmp/{file_name_full}")#import csvDoc Processing
As soon as the doc is downloaded, we proceed with doc processing, which includes loading the coverage doc and splitting it into smaller, manageable chunks.
loader = PyPDFLoader(f"/tmp/{file_name_full}")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(docs)#import csvVector Embeddings Era
With the paperwork cut up, we make the most of the Titan Embeddings Mannequin to generate vector embeddings for every doc chunk:
vectorstore_faiss = FAISS.from_documents(docs, bedrock_embeddings)
file_path = f"/tmp/"
Path(file_path).mkdir(dad and mom=True, exist_ok=True)
file_name = "faiss_index"
vectorstore_faiss.save_local(index_name=file_name, folder_path=file_path)#import csvSave and Add
Lastly, we save the generated vector embeddings domestically and add them to the desired S3 bucket for future retrieval:
s3_vector_faiss_key = f'vectors/policydoc/{policy_number}/policydoc_faiss.faiss'
s3.upload_file(Filename=f"{file_path}/{file_name}.faiss", Bucket=BUCKET_NAME, Key=s3_vector_faiss_key)#import csvModule3: Growing the Chatbot
Let’s dissect the important thing parts that orchestrate this chatbot’s performance:
Crafting Prompts and Integrating the LLM
The template variable establishes a structured format for feeding context and consumer queries to the LLM. This method ensures the LLM stays centered on pertinent data whereas producing responses.
template = """Make the most of the next contextual fragments to handle the query at hand. Adhere to those pointers:
1. In the event you're not sure of the reply, chorus from fabricating one.
2. Upon discovering the reply, ship it in a complete method, omitting references.
{context}
Query: {enter}
Useful Reply:"""#import csvget_llama2_llm perform: This perform establishes a connection to Bedrock, a managed LLM service supplied by Amazon Net Providers (AWS). It pinpoints the “meta.llama2-13b-chat-v1” mannequin, famend for its conversational capabilities.
def get_llama2_llm():
llm = Bedrock(model_id="meta.llama2-13b-chat-v1", consumer=bedrock,
model_kwargs={'max_gen_len': 512})
return llm
llm = get_llama2_llm()#import csvInfo Retrieval through FAISS
download_vectors perform: This perform retrieves pre-computed doc vectors related to a particular coverage quantity from an S3 bucket (cloud storage). These vectors facilitate environment friendly doc retrieval primarily based on semantic similarity.
def download_vectors(policy_number):
s3_vector_faiss_key = 'vectors/policydoc/' + policy_number + "https://www.analyticsvidhya.com/" + 'policydoc_faiss.faiss'
s3_vector_pkl_key = 'vectors/policydoc/' + policy_number + "https://www.analyticsvidhya.com/" + 'policydoc_pkl.pkl'
Path(file_path).mkdir(dad and mom=True, exist_ok=True)
s3.download_file(Bucket=BUCKET_NAME, Key=s3_vector_faiss_key, Filename=f"{file_path}/my_faiss.faiss")
s3.download_file(Bucket=BUCKET_NAME, Key=s3_vector_pkl_key, Filename=f"{file_path}/my_faiss.pkl")#import csvload_faiss_index perform: This perform leverages the FAISS library (a library for environment friendly similarity search) to load the downloaded vectors and assemble an index. This index empowers the retrieval of related coverage paperwork swiftly when a consumer poses a query.
def load_faiss_index():
faiss_index = FAISS.load_local(index_name="my_faiss", folder_path=file_path, embeddings=bedrock_embeddings, allow_dangerous_deserialization=True)
retriever = faiss_index.as_retriever()
document_chain = create_stuff_documents_chain(llm, immediate)
retriever_chain = create_history_aware_retriever(llm, retriever, immediate)
chain = create_retrieval_chain(retriever_chain, document_chain)
return chain#import csvSetting up the Retrieval-Augmented Chain
Now let’s perceive the workings of the retreival augmented chain intimately. It consists of three components
Doc Processing Chain: This line initializes a sequence devoted to processing paperwork. The perform create_stuff_documents_chain doubtless handles duties reminiscent of tokenization, textual content technology, and different document-related operations.
document_chain = create_stuff_documents_chain(llm, immediate)#import csvRetrieval Chain: Right here, a retrieval chain is created to fetch related paperwork. The perform create_history_aware_retriever incorporates historic information to boost the retrieval course of.
retriever_chain = create_history_aware_retriever(llm, retriever, immediate)#import csvCombining Chains: This line combines the retrieval and doc processing chains right into a single retrieval chain. The perform create_retrieval_chain orchestrates this mix, guaranteeing seamless integration of retrieval and doc processing duties. The mixed chain goals to supply correct and contextually related responses primarily based on the enter immediate and historic context.
chain = create_retrieval_chain(retriever_chain, document_chain)Deploying the Chatbot in AWS
Allow us to now discover deploying the chatbot in AWS.
Step1: Initializing EC2 Occasion
Launch an EC2 occasion with Amazon Linux and configure safety teams to allow visitors on port 8501.
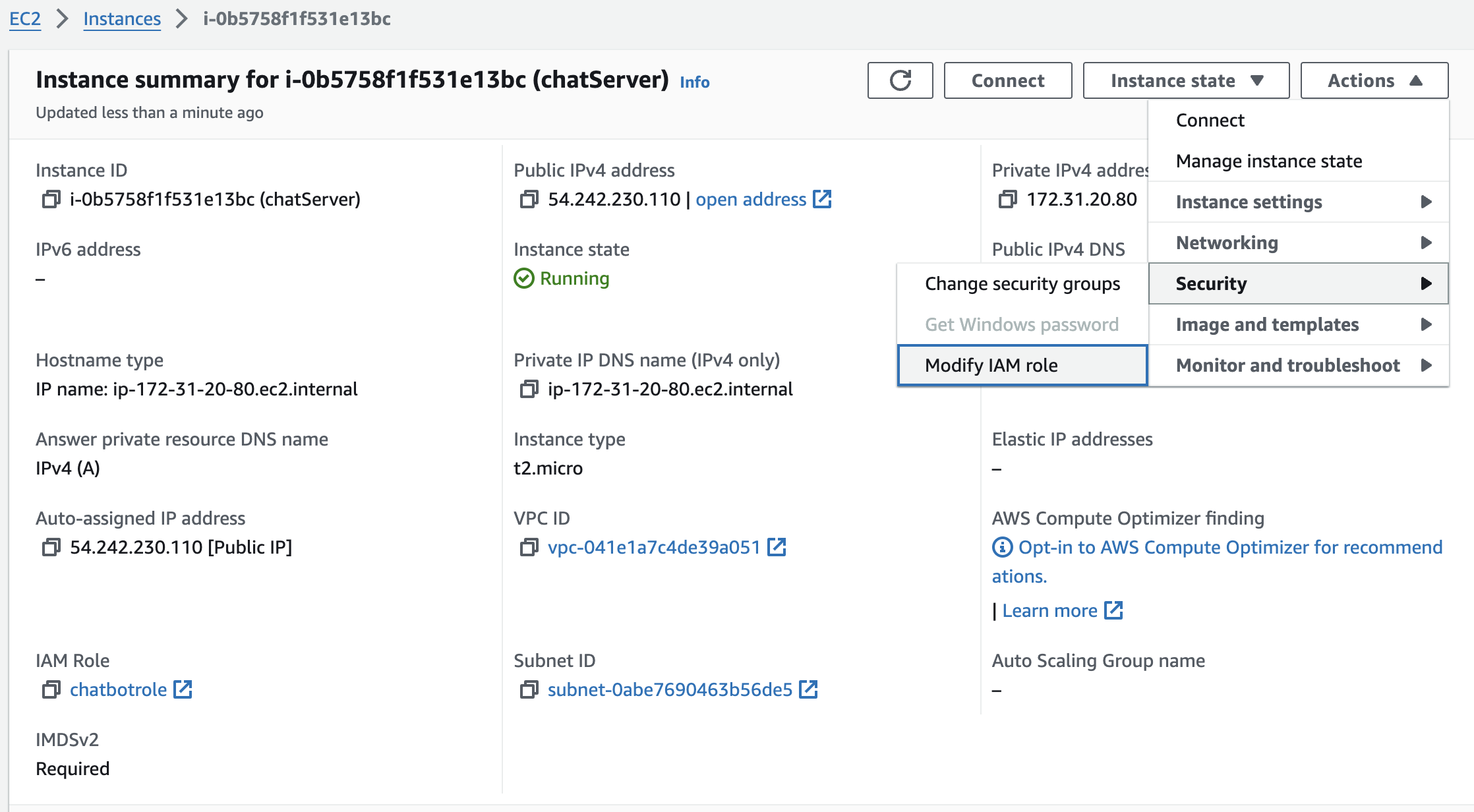
Step2: Configure IAM Position
Configure an IAM Position with entry to the S3 bucket and AWS Bedrock and connect it to the EC2 occasion.
Step3: Connect with EC2 Server
Now you possibly can hook up with the EC2 server from the console and run the next scripts to get the applying working.
#!/bin/bash
# Replace package deal index
sudo yum replace -y
# Set up Git
sudo yum set up git -y
# Set up Docker
sudo yum set up docker -y
# Begin Docker service
sudo service docker begin
# Allow Docker to start out on boot
sudo chkconfig docker on
# Clone Streamlit app repository
git clone https://github.com/arpan65/Insurance coverage-RAG-Chatbot.git
cd Insurance coverage-RAG-Chatbot/ChatUI/ChatApp
# Construct Docker picture
sudo docker construct -t chatApp .
# Run Docker container
sudo docker run -d -p 8501:8501 chatApp
echo "Streamlit app deployed. You may entry it at http://$(curl -s http://169.254.169.254/newest/meta-data/public-ipv4):8501"#import csvStep4: Configure Nginx for HTTPS (elective)
If it’s essential safe your software with HTTPS, arrange Nginx as a reverse proxy and configure SSL certificates. Being a POC software, we’ll skip this step in our context.
As soon as the chatbot is working, copy the general public URL and replace it within the index.html file underneath the web site earlier than deploying it to the AWS.
<div id="chat-widget" class="chat-widget">
<button id="chat-toggle-btn" class="chat-toggle-btn">Ask IVA</button>
<div id="chat-window" class="chat-window">
<iframe src="https://www.analyticsvidhya.com/weblog/2024/06/rag-chatbot-for-insurance/{your_bot_url}" frameborder="0" width="100%" peak="100%"></iframe>
</div>
</div>Testing the Workflow
After finishing the event and deployment of all required modules, you possibly can take a look at the chatbot utilizing the next steps:
Step1: Entry S3 in AWS Console
Navigate to the rag-source-bucket within the AWS S3 console.
Step2: Add Pattern Coverage Doc
- Create a folder named docs if not already current.
- Add the pattern coverage doc offered within the repository to this folder.
Step3: Set off Lambda Operate
- The Lambda perform must be triggered robotically upon importing the doc.
- It should create a brand new folder named vectors inside which policy-specific vector indexes can be saved.
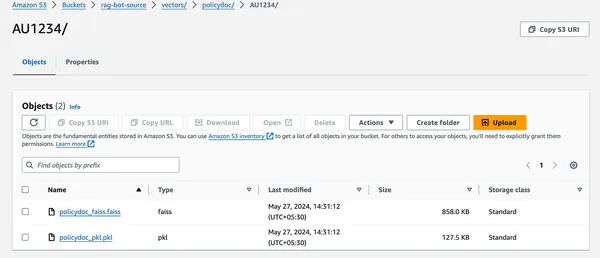
Step4: Entry Web site Bucket
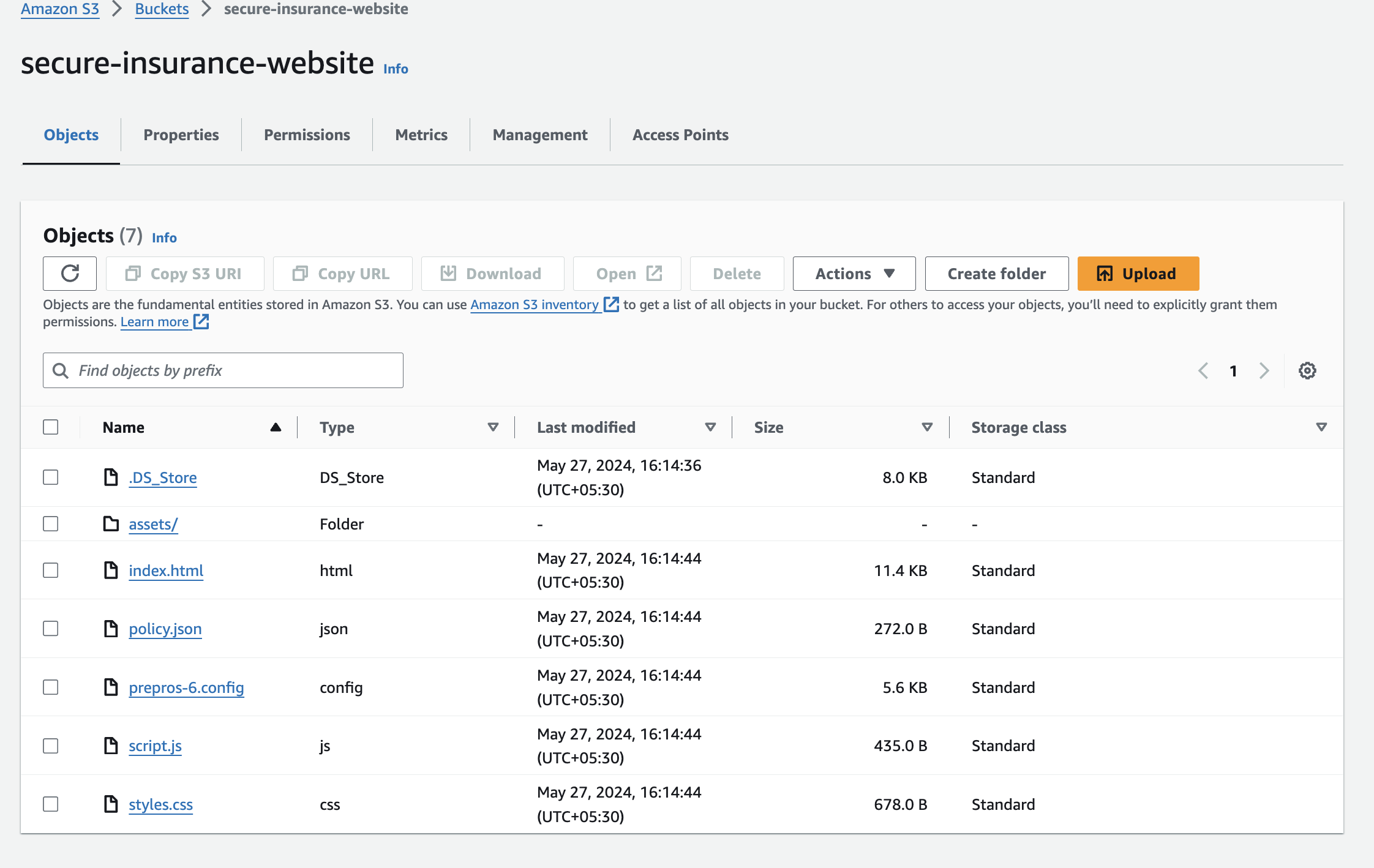
- Navigate to the secure-insurance-website bucket within the AWS S3 console.
- Browse the index.html object, which ought to open the web site in a brand new window.
Step5: Entry the Chatbot
- Now you can entry the chatbot from this touchdown web page.
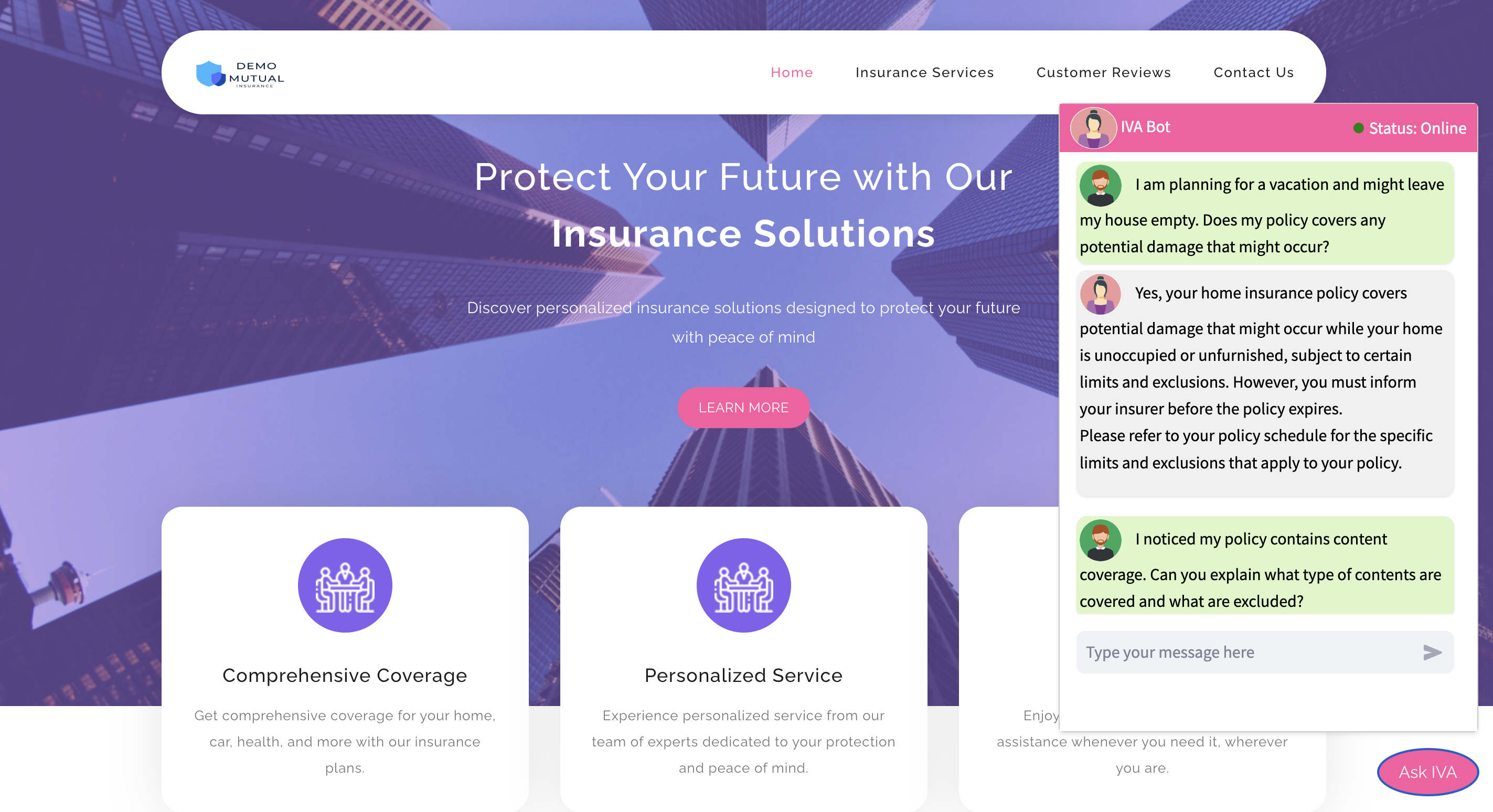
Please Be aware: Guarantee mixed-mode internet hosting is allowed within the browser to check the chatbot. In any other case, the browser might not enable the HTTP URL to run from the web site.
By following these steps, you possibly can successfully take a look at the performance of the chatbot and be certain that it retrieves and processes coverage paperwork precisely.
Watch the demo right here:
Conclusion
IVA (Insurance coverage Digital Agent) is a prototype devoted to showcasing Retrieval-Augmented-Era (RAG) capabilities throughout the insurance coverage sector. By leveraging applied sciences reminiscent of AWS Bedrock, Lambda, and Streamlit, IVA effectively retrieves and generates detailed responses primarily based on coverage paperwork. Though it isn’t a complete assist chatbot, IVA exemplifies how AI can considerably improve buyer expertise and operational effectivity. Continued innovation may additional streamline processes and supply customized help to policyholders, marking a major step ahead in optimizing insurance coverage providers.
Key Takeaways
- Gained worthwhile insights into leveraging superior AI and cloud applied sciences to boost consumer expertise within the insurance coverage sector.
- Utilized the LangChain framework to streamline dialog movement and doc retrieval, highlighting the potential of RAG know-how.
- Effectively built-in AWS providers like Bedrock, Lambda, and S3 for doc processing and retrieval.
- Demonstrated the sensible functions of AI in real-world situations by deploying the chatbot on an EC2 occasion with a user-friendly Streamlit interface.
- Highlighted the transformative potential of AI in streamlining insurance coverage providers and bettering buyer interactions.
- Acknowledged that IVA, whereas a prototype, showcases the capabilities of RAG know-how within the insurance coverage sector.
Essential Hyperlinks
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.
Incessantly Requested Questions
A: A RAG Chatbot for Insurance coverage makes use of Retrieval-Augmented Era know-how to supply correct and detailed responses to policyholder queries by retrieving related data from insurance coverage paperwork.
A. IVA integrates AWS providers reminiscent of Bedrock for producing embeddings, Lambda for executing code in response to occasions, and S3 for storing and retrieving paperwork. These providers work collectively to course of paperwork effectively and retrieve related data in response to consumer queries.
A. LangChain is used to handle dialog movement and doc retrieval inside IVA. By leveraging LangChain, the chatbot can extra precisely interpret consumer queries, retrieve pertinent data, and generate coherent and contextually applicable responses.
A. IVA is deployed on an Amazon EC2 occasion with a user-friendly Streamlit interface. The deployment course of includes establishing the EC2 occasion, configuring safety teams, and working a Docker container that hosts the Streamlit app, making the chatbot accessible to customers.
A. No, IVA is a prototype centered solely on demonstrating the capabilities of Retrieval-Augmented Era (RAG) know-how throughout the insurance coverage sector. Whereas it highlights the potential of AI to streamline customer support, it isn’t designed to be a complete assist chatbot.