

Giant language fashions (LLMs) have considerably superior numerous pure language processing duties, however they nonetheless face substantial challenges in advanced mathematical reasoning. The first downside researchers are attempting to unravel is learn how to allow open-source LLMs to successfully deal with advanced mathematical duties. Present methodologies battle with process decomposition for advanced issues and fail to offer LLMs with ample suggestions from instruments to help complete evaluation. Whereas present approaches have proven promise in easier math issues, they fall quick when confronted with extra superior mathematical reasoning challenges, highlighting the necessity for a extra subtle strategy.
Present makes an attempt to reinforce mathematical reasoning in LLMs have advanced from fundamental computational expressions to extra subtle approaches. Chain-of-Thought (COT) and Program-of-Thought (POT) strategies launched intermediate steps and code instruments to enhance problem-solving capabilities. Collaborative paradigms combining COT and coding have proven important accuracy enhancements. Knowledge augmentation strategies have additionally been explored, with researchers curating numerous mathematical datasets and producing artificial question-answer pairs utilizing superior LLMs to create Supervised Nice-Tuning (SFT) datasets. Nevertheless, these strategies nonetheless face limitations in dealing with advanced mathematical duties and offering complete evaluation, indicating the necessity for a extra superior strategy that may successfully decompose issues and make the most of suggestions from instruments.
Researchers from the College of Science and Know-how of China and Alibaba Group current DotaMath, an environment friendly strategy to reinforce LLMs’ mathematical reasoning capabilities, addressing the challenges of advanced mathematical duties by way of three key improvements. First, it employs a decomposition of thought technique, breaking down advanced issues into extra manageable subtasks that may be solved utilizing code help. Second, it implements an intermediate course of show, permitting the mannequin to obtain extra detailed suggestions from code interpreters, enabling complete evaluation and enhancing the human readability of responses. Lastly, DotaMath incorporates a self-correction mechanism, permitting the mannequin to replicate on and rectify its options when preliminary makes an attempt fail. These design components collectively goal to beat present strategies’ limitations and considerably enhance LLMs’ efficiency on advanced mathematical reasoning duties.
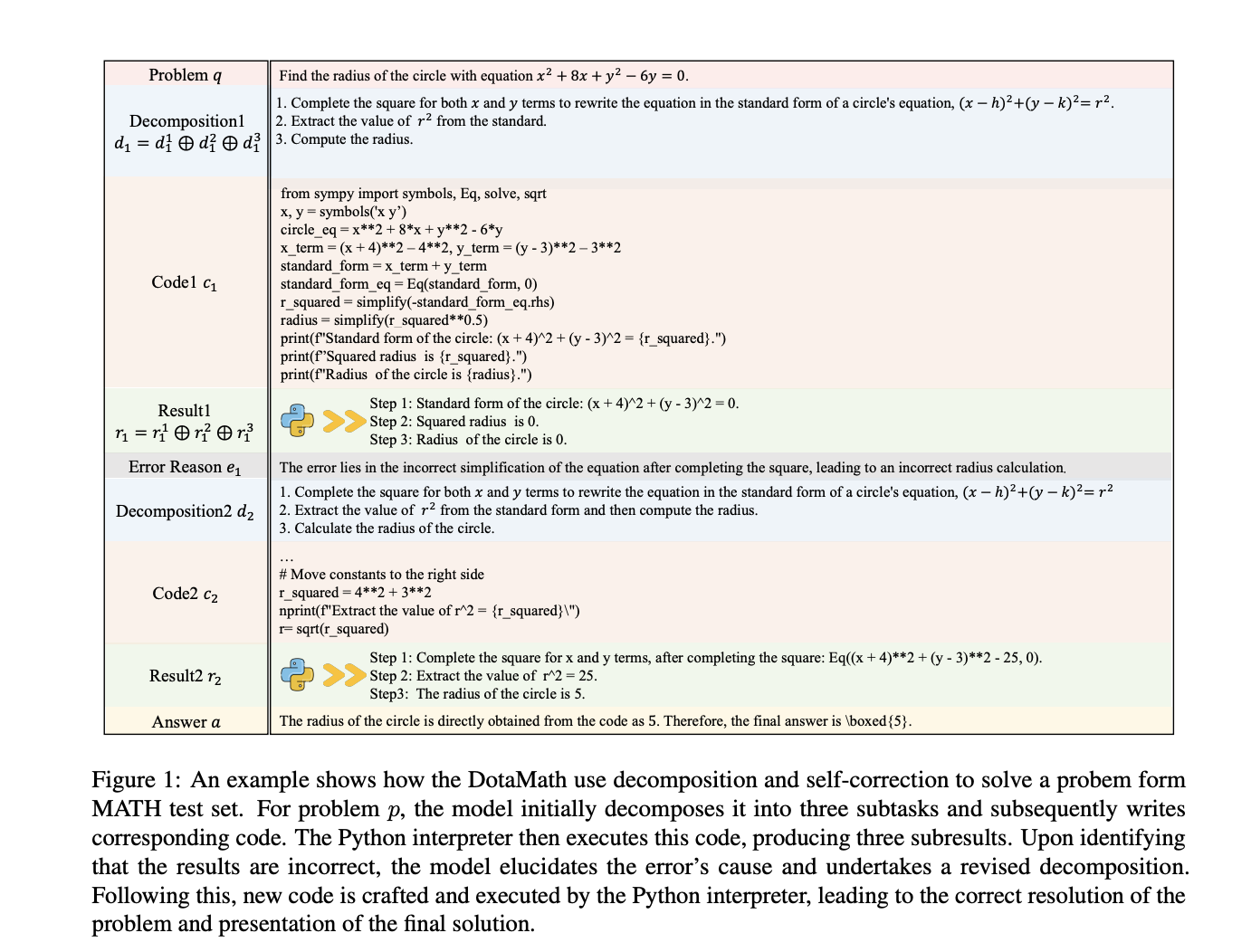
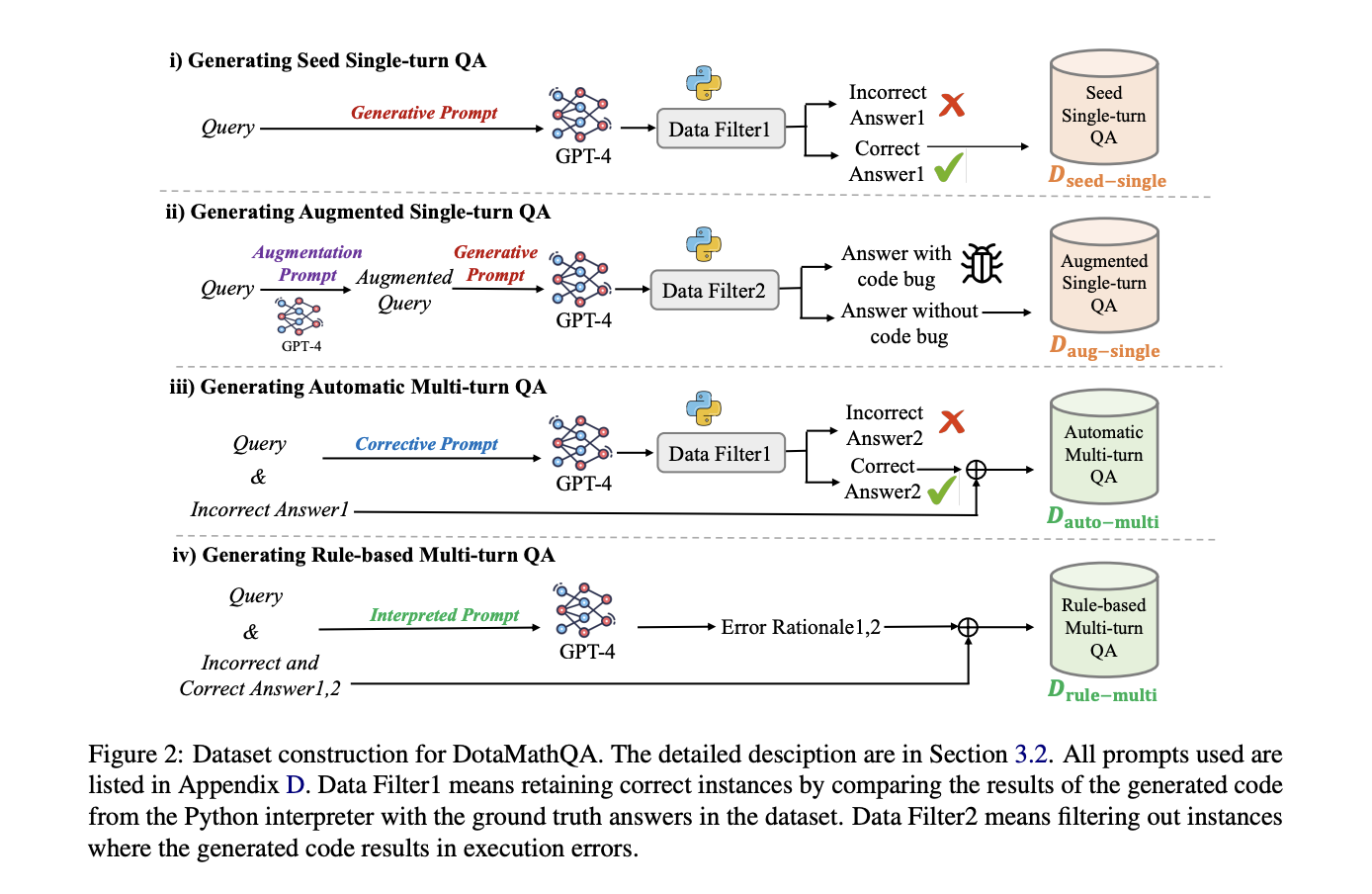
DotaMath enhances LLMs’ mathematical reasoning by way of three key improvements: decomposition of thought, intermediate course of show, and self-correction. The mannequin breaks advanced issues into subtasks, makes use of code to unravel them, and gives detailed suggestions from code interpreters. The DotaMathQA dataset, constructed utilizing GPT-4, consists of single-turn and multi-turn QA information from present datasets and augmented queries. This dataset permits the mannequin to be taught process decomposition, code era, and error correction. Numerous base fashions are fine-tuned on DotaMathQA, optimizing for the log-likelihood of reasoning trajectories. This strategy permits DotaMath to deal with advanced mathematical duties extra successfully than earlier strategies, addressing limitations in present LLMs’ mathematical reasoning capabilities.
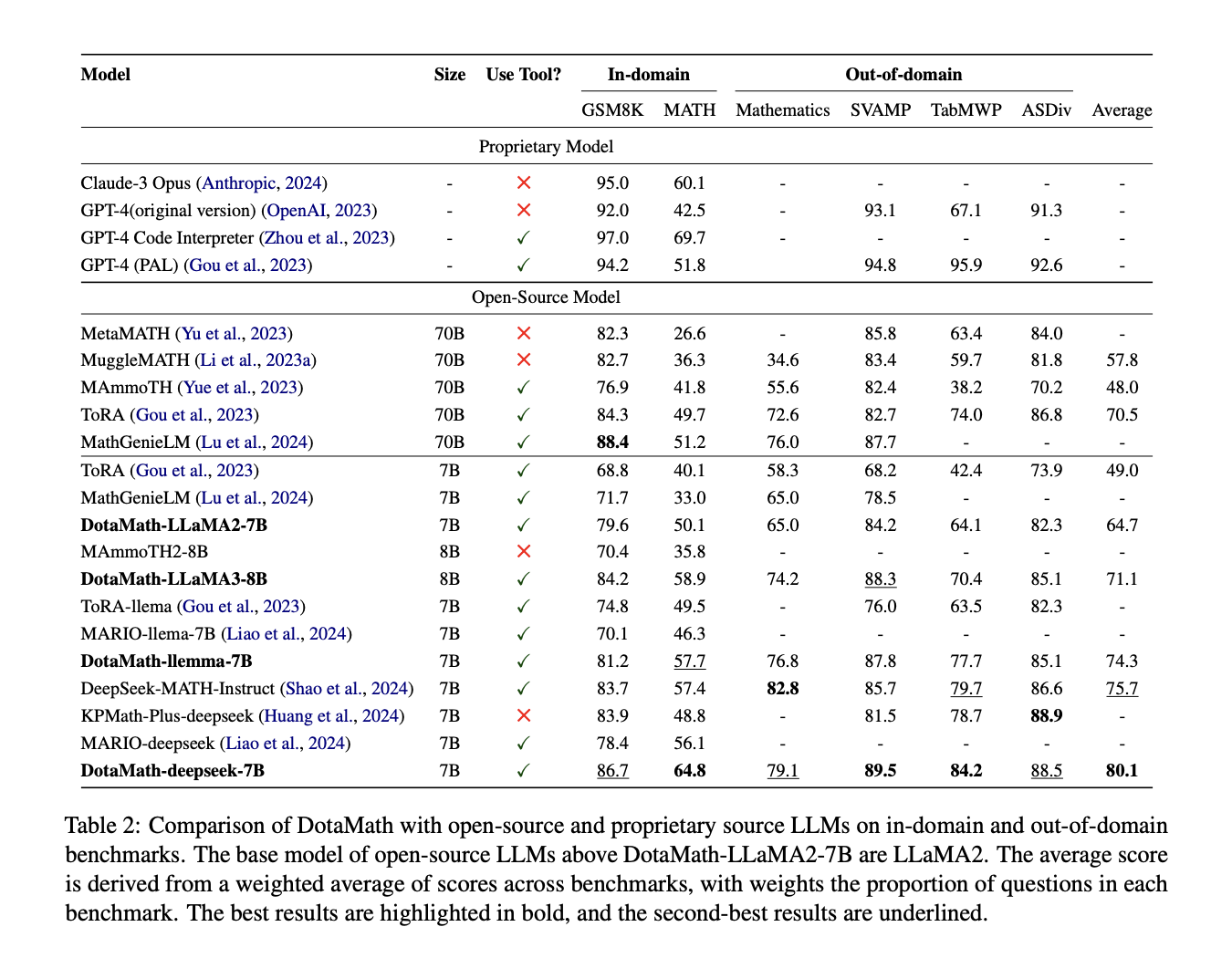
DotaMath demonstrates distinctive efficiency throughout numerous mathematical reasoning benchmarks. Its 7B mannequin outperforms most 70B open-source fashions on elementary duties like GSM8K. For advanced duties similar to MATH, DotaMath surpasses each open-source and proprietary fashions, highlighting the effectiveness of its tool-based strategy. The mannequin exhibits sturdy generalization capabilities on untrained out-of-domain datasets. Completely different DotaMath variations exhibit incremental enhancements, possible because of pre-training information variations. Total, DotaMath’s efficiency throughout numerous benchmarks underscores its complete mathematical reasoning talents and the effectiveness of its revolutionary strategy, combining process decomposition, code help, and self-correction mechanisms.
DotaMath represents a big development in mathematical reasoning for LLMs, introducing revolutionary strategies like thought decomposition, code help, and self-correction. Educated on the in depth DotaMathQA dataset, it achieves excellent efficiency throughout numerous mathematical benchmarks, notably excelling in advanced duties. The mannequin’s success validates its strategy to tackling tough issues and demonstrates enhanced program simulation talents. By pushing the boundaries of open-source LLMs’ mathematical capabilities, DotaMath not solely units a brand new normal for efficiency but additionally opens up thrilling avenues for future analysis in AI-driven mathematical reasoning and problem-solving.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 46k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.