

Giant language fashions (LLMs) stand out for his or her astonishing skill to imitate human language. These fashions, pivotal in developments throughout machine translation, summarization, and conversational AI, thrive on huge datasets and equally huge computational energy. The scalability of such fashions has been bottlenecked by the sheer computational demand, making coaching fashions with tons of of billions of parameters a formidable problem.
MegaScale is a collaboration between ByteDance and Peking College, enabling the coaching of LLMs on a beforehand unattainable scale. MegaScale’s genesis is rooted within the recognition that coaching LLMs at scale is just not merely a query of harnessing extra computational energy however optimizing how that energy is utilized. The system is designed from the bottom as much as deal with the twin challenges of effectivity and stability which have hampered earlier efforts to scale up LLM coaching. By integrating progressive strategies throughout the mannequin structure, knowledge pipeline, and community efficiency, MegaScale ensures that each little bit of computational energy contributes to extra environment friendly and steady coaching.

MegaScale’s methodology is a set of optimization strategies tailor-made to the distinctive calls for of LLM coaching. The system employs parallel transformer blocks and sliding window consideration mechanisms to scale back computational overhead, whereas a classy combine of knowledge, pipeline, and tensor parallelism methods optimizes useful resource utilization. These methods are complemented by a customized community design that accelerates communication between the hundreds of GPUs concerned within the coaching course of.
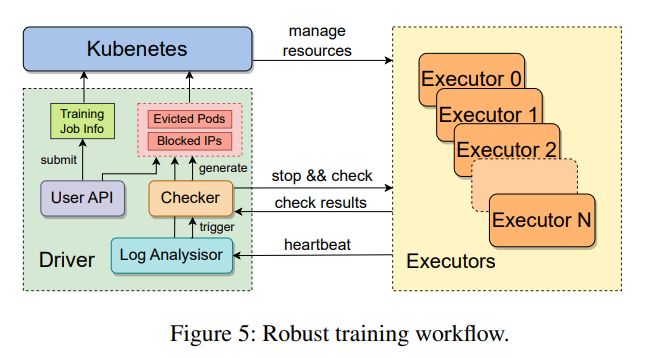
The system’s diagnostic and restoration capabilities additional distinguish MegaScale. A strong set of instruments displays system elements and occasions deep within the stack, permitting for the fast identification and rectification of faults. This ensures excessive coaching effectivity and maintains this effectivity constantly over time, addressing one of many important challenges in deploying LLMs at scale.
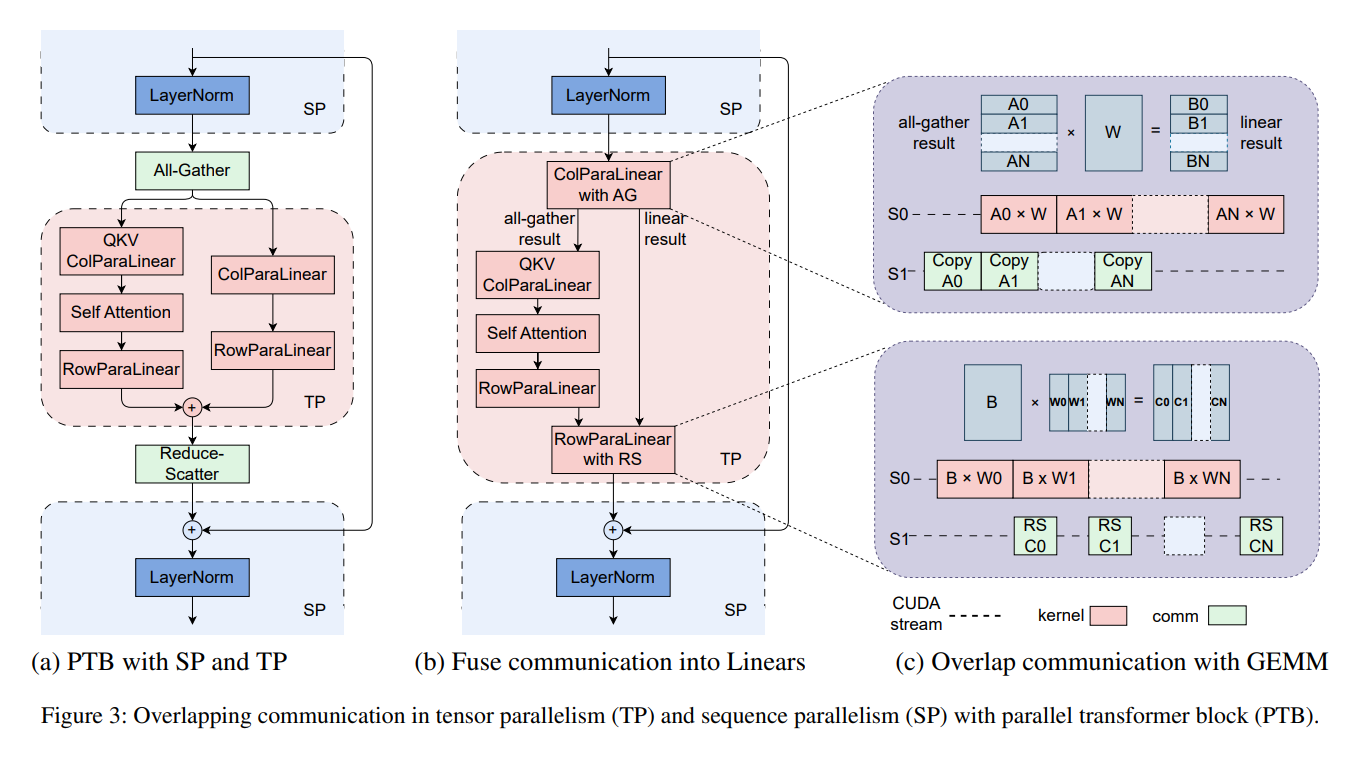
MegaScale’s impression is underscored by its efficiency in real-world functions. When tasked with coaching a 175B parameter LLM on 12,288 GPUs, MegaScale achieved a mannequin FLOPs utilization (MFU) of 55.2%, considerably outpacing current frameworks. This effectivity increase shortens coaching occasions and enhances the coaching course of’s stability, guaranteeing that large-scale LLM coaching is each sensible and sustainable.
In conclusion, MegaScale represents a major second within the coaching of LLMs, characterised by the next:
- A holistic strategy to optimizing the LLM coaching course of, from mannequin structure to community efficiency.
- The introduction of parallel transformer blocks and sliding window consideration mechanisms, alongside a mixture of parallelism methods, to reinforce computational effectivity.
- A customized community design and a sturdy diagnostic and restoration system guarantee excessive coaching effectivity and stability.
- Demonstrated superiority in real-world functions, attaining unprecedented MFU and considerably enhancing the efficiency of current coaching frameworks.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
You might also like our FREE AI Programs….
Hi there, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with know-how and wish to create new merchandise that make a distinction.