

Get began and construct a credit score knowledge platform for your corporation by visiting the demo at dbdemos.ai.
Introduction
In response to the World Financial institution’s reporting on monetary inclusion, a staggering 1.7 billion adults have been deemed underbanked. Many underbanked people discover it tough to safe loans from conventional monetary establishments, main them to show to casual lenders who supply loans at exorbitant rates of interest. This group usually consists of youthful generations, low-income people in growing nations, and rural residents, a lot of which have gone cellular with the intention to acquire monetary entry.
On the subject of the underbanked, cellular banking has usually stepped in to fulfill the patron wants in areas the place conventional banking is perceived to be weak. The variety of smartphone customers worldwide has persistently grown by a minimal of 5% yearly over the previous 5 years, presenting a brand new and promising alternative for lending. Monetary establishments have to leverage this chance by using machine studying and different superior analytics to evaluate a buyer’s creditworthiness and progressively construct up a credit score historical past by way of their platforms, increasing the scope of monetary inclusion and opening doorways to beforehand unattainable credit score alternatives.
Within the spirit of monetary inclusion and increasing conventional considering, this weblog serves as a information and reusable public Lakehouse demo for the way banks, fintechs, and non-banks can enter the low-hanging fruit markets which might be ready and longing for higher monetary providers.
As Deloitte factors out of their report on monetary inclusion, ‘doing nicely and doing good usually are not mutually unique’; that is resonating with many knowledge groups within the business. Let’s outline some phrases to know this idea higher.
Credit score decisioning is the method of assessing a person’s creditworthiness to find out their potential to repay a mortgage or credit score. It’s a vital a part of the lending business and includes numerous phases, together with knowledge assortment, knowledge processing, and knowledge evaluation and loss estimation. Historically, credit score decisioning has been a prolonged course of–even for short-term loans–that are the forms of loans mostly bought by the underbanked. Furthermore, the method is closely biased in direction of these people with prior credit score historical past or long-term loans. With the arrival of buy-now-pay-later (BNPL) choices, digital markets for residence purchases, and non-banks providing credit score, the world stage for credit score decisioning has utterly reworked.
As AI-assisted credit score decisioning continues to advance, the banking and fee industries are witnessing a surge in buyer calls for for a Databricks Lakehouse design. This design presents a credit score knowledge platform that gives a holistic and environment friendly resolution to the credit score decisioning course of. The platform can allow knowledge integration, audit, AI-powered selections, and explainability, offering a single supply of reality for knowledge analytics. The credit score knowledge platform consists of machine studying fashions that may analyze huge quantities of information and supply extra correct predictions a couple of borrower’s creditworthiness, enhancing the velocity and accuracy of the credit score decisioning course of. The credit score knowledge platform may help fintechs, banks, or non-banks seeking to supply monetary providers make knowledgeable credit score selections, scale back the danger of default, and supply higher charges and phrases to their clients. Earlier than delving into the know-how resolution, we are going to cowl the areas wherein monetary establishments are struggling to serve markets right now.
Half I – Why Change?
Challenges in Banking
Implementing a credit score knowledge platform generally is a important problem for banks and different monetary establishments. Think about the next causes.
Problem #1 – Lack of current knowledge
Good credit score modeling is a big knowledge curation train.
Many underbanked people discover it tough to safe loans from conventional monetary establishments, main them to show to casual lenders who supply loans at exorbitant rates of interest. Credit score decisioning for underbanked clients will be difficult, as these people might not have a standard credit score historical past or monetary information that can be utilized to evaluate their creditworthiness. Moreover, credit score decisioning knowledge is usually saved throughout totally different sources and incompatible codecs, making it tough for knowledge customers to totally merge collectively and extract precious insights. This leads to knowledge solely being obtainable to knowledge engineers and scientists, however to not finish customers resembling advertising and marketing and finance groups, name middle brokers, and financial institution tellers.
Problem #2 – Safety and Governance
Knowledge with out limits doesn’t imply working with out governance.
Banks and different monetary establishments face important challenges when constructing a credit score knowledge platform. They need to be sure that the platform is safe, compliant with regulatory necessities, and protects delicate buyer knowledge. Attaining these objectives requires addressing numerous challenges associated to safety and governance, resembling knowledge privateness, entry management, high quality, and compliance. Nonetheless, knowledge governance and enterprise safety management will be difficult as a result of complexity of information ecosystems, evolving threats, insider dangers, and useful resource constraints. To successfully handle and safe their knowledge, organizations should tackle these challenges on the basis – it can’t be an afterthought.
Problem #3 – Explainability and Equity
Make your “knowledge insights” actionable
Explainability and equity are important in credit score decisioning as a result of they promote unbiased and comprehensible selections that shield shoppers from discrimination and guarantee equitable outcomes. Lack of equity and explainability can erode belief within the credit score system and discourage shoppers from making use of for credit score. Nonetheless, evaluating equity in credit score selections and explaining outcomes will be difficult because of a number of components. These embrace the complexity of credit score scoring fashions, potential knowledge biases, and potential for human biases.
Credit score Decisioning Answer
On this weblog, we exhibit how setting the suitable knowledge foundations by way of the Databricks Lakehouse can tackle the aforementioned challenges and allow firms to create higher credit score fashions and obtain their enterprise objectives, together with serving their underbanked clients, assessing credit score threat and publicity, introducing novel merchandise resembling buy-now-pay-later, and others.

Good credit score fashions require all kinds of information depicting the financial institution clients from as many angles as potential, together with their spending habits, potential earlier delinquencies, sources of revenue, and plenty of extra. We report on the left hand facet of the image the totally different monetary knowledge sources we have to create a contemporary credit score decisioning platform, together with credit score bureau knowledge, buyer data, real-time transactional knowledge, in addition to companion knowledge (telecom knowledge that we use to reinforce the normal banking data). It’s simple to see that each one knowledge sources have completely totally different file codecs, velocity of ingestion, quantity, and supply platform.
Knowledge Unification
To resolve the variability problem, we start with Knowledge Unification – the flexibility to ingest any supply of information in a single supply of reality location.
- Utilizing Delta Dwell Tables, a declarative framework for constructing dependable, maintainable, and testable knowledge processing pipelines, we are able to streamline the ingestion of all these knowledge sources right into a single pipeline, storage location, and file format, Delta Lake. With capabilities resembling time touring, schema enforcement and detection, and the flexibility to merge streaming and batch knowledge, Delta lake offers reliability and efficiency, the cornerstone of a contemporary knowledge platform. All knowledge is streaming in right now’s world – close to real-time ingestion is desk stakes, and Delta Dwell Tables offers a easy interface to give attention to the ‘what’ as an alternative of the ‘how’ for provisioning infrastructure.
- Knowledge unification additionally means simplified governance and safety since all knowledge is in the identical location and in the identical format. Credit score scoring requires sources that comprise numerous Private Identifiable Info (PII). Via the Databricks Governance resolution, generally known as Unity Catalog, we are able to simply obtain the best stage of safety with out jeopardizing the usability and consumability of the info. Unity Catalog permits us to simply apply granular desk entry controls (ACLs) utilizing easy SQL statements no matter the format of the info, even whether it is unstructured or stream, apply row- and column-level filtering and masking, and handle exterior places and storage credentials.
Knowledge Selections
As soon as the right knowledge basis has been set, we are able to transfer to Knowledge Decisioning and discover the hidden patterns and correlations we name “knowledge insights”:
- Efficient cross-team collaboration is extraordinarily essential for efficiently constructing knowledge merchandise throughout the monetary providers business. MLFlow‘s glass-box AutoML functionality, enhanced with the discoverability and lineage of the Databricks Characteristic Retailer and the GUI-based knowledge profiling and dashboarding built-in within the Databricks Notebooks, permits to in a short time create a baseline mannequin by way of automated experimentation, mannequin choice, and hyperparameter tuning.
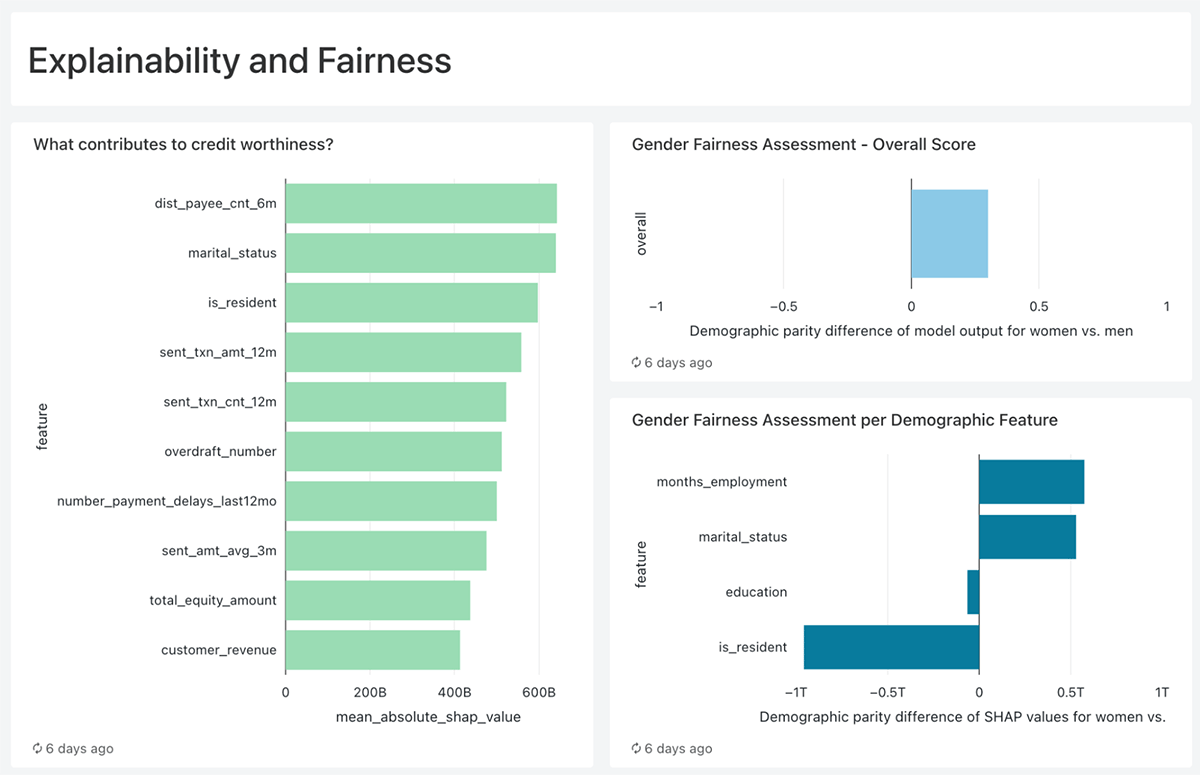
- As we already talked about, if the info insights and machine studying predictions usually are not explainable, truthful, and actionable, it is extremely doubtless that they are going to solely keep within the Notebooks. On this demo, we use SHAP (SHapley Additive exPlanations) to tie again statistics to enterprise processes by providing particulars resembling “What contributes to credit score worthiness?” or “Why a specific buyer will default” making it simpler for credit score brokers and advertising and marketing groups to deal with every individual individually.
Knowledge Democratization
These days, knowledge is accessible and usable solely by the info groups, resembling knowledge scientists and knowledge engineers. Knowledge groups, nonetheless, usually are not the top customers of a use case, such because the credit score decisioning – it’s the credit score brokers evaluating an software, name middle brokers speaking with a buyer, or advertising and marketing groups making ready promotional supplies for upselling the underbanked clients. These personas, nonetheless, as a rule, shouldn’t have entry neither to the info nor to dashboards or machine studying predictions. Within the previous days, knowledge groups would export any requested knowledge to csv or pdf information and ship it to the enterprise customers over e mail. This strategy isn’t safe, scalable, or easy.
Unity Catalog and Databricks knowledge warehousing resolution, Databricks SQL, permits monetary providers organizations to “democratize” their knowledge and insights and permit entry to them by not solely knowledge customers however everybody within the group by way of capabilities such because the BI visualizations and Delta Sharing, an open protocol for securely stay sharing of any knowledge with no replication, centralized governance, an cross-platform recipients.
Databricks Lakehouse for Monetary Companies
The mixture of information and person unification, actionable decisioning, and knowledge democratization are the basics of the Databricks Lakehouse for Monetary Companies. It’s the final democratization of information entry with out sacrificing safety and governance, as we are going to present.

Enterprise Outcomes
To start out our tour of the Lakehouse demo for credit score decisioning, we need to present the impression any monetary establishment can obtain. In unifying our knowledge and making it obtainable for analytics, we’re driving enterprise outcomes that usher in new shoppers, a win for each FSIs and prospects alike.
Upselling and serving the underbanked clients
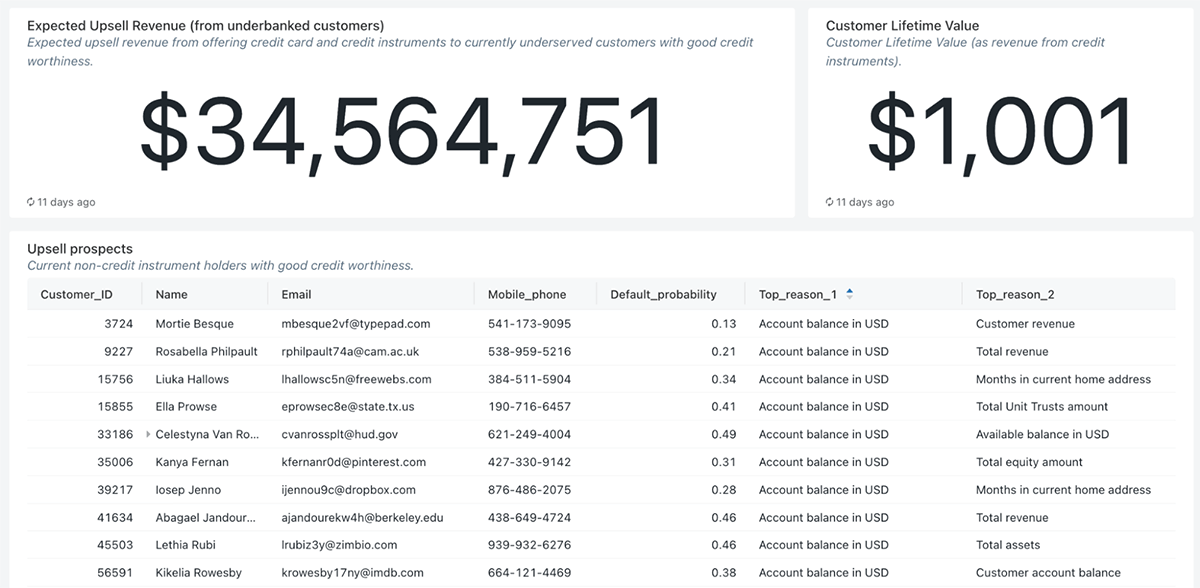
Via dashboarding capabilities enriched with buyer lifetime values fashions (CLV), we are able to simply report the monetary advantages of figuring out and serving creditworthy clients (underbanked) who at the moment shouldn’t have any credit score devices with the financial institution. The dashboard combines uncooked knowledge, machine studying predictions, in addition to explainability data, not solely figuring out the chance of default for every underbanked buyer but in addition the highest three causes distinctive to every buyer, making it very actionable for credit score brokers evaluating the creditworthiness in addition to the advertising and marketing staff speaking with the shoppers. Lastly, as reported beneath, we additionally supply a technique to assess the equity of our credit score scoring fashions and ensure we don’t drawback any teams of shoppers.
Half II – How one can Serve Extra Shoppers with the Lakehouse Structure
Constructing the Platform
On this part we are going to go even deeper into the technical implementation and structure of the credit score decisioning demo and see how the Lakehouse helps monetary organizations use their knowledge to attain their enterprise objectives.
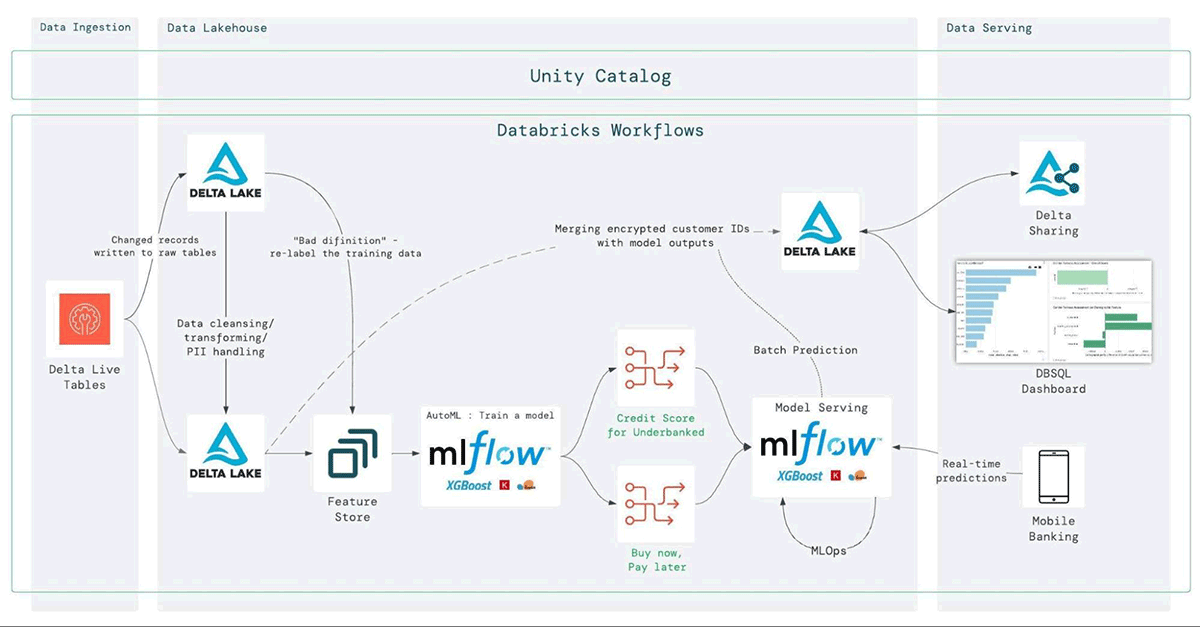
The image above depicts the precise structure of the credit score decisioning resolution and reveals how we obtain the aforementioned objectives, together with knowledge unification, governance, and democratization.
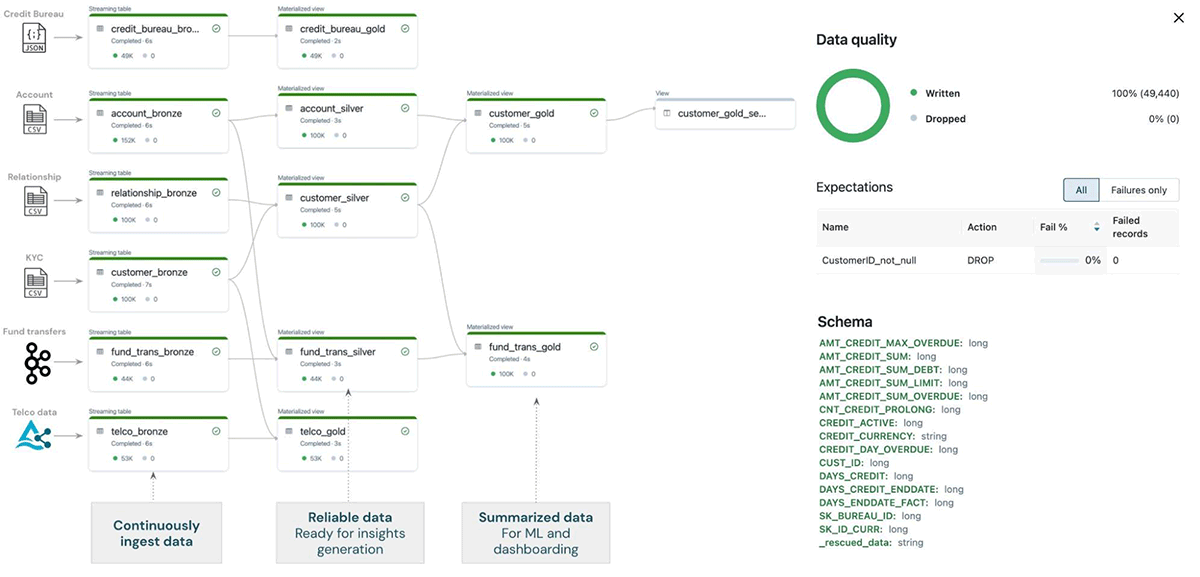
- Beginning with the ingestion, we use Delta Dwell Tables (DLT) to hook up with the assorted sources (beneath) and ingest them right into a single supply of reality location. DLT has a number of different capabilities making it a particularly simple to make use of knowledge engineering device, together with automated knowledge high quality checks and experiences, autoscaling, schema detection, execution scheduling, deep monitoring and observability, and others. Utilizing DLT we are able to simply clear and curate the ingested knowledge (into the silver and gold layers).
Knowledge engineering groups now not want numerous instruments, languages, platforms, or providers to streamline ETL processes. All they want is python or SQL to deal with the ingestion and transformation of any knowledge supply, be it structured, unstructured, or within the type of a stream. This fashion, DLT considerably simplifies the info structure, reduces the effort and time required, minimizes the info high quality issues, and general, helps the info groups work extra successfully in direction of their organizations’ knowledge objectives.
- The following step is to correctly safe the info whereas making it discoverable and consumable. The Lakehouse makes it simple to attain a tremendous grained governance on all customers and knowledge. Traditionally, it was tough to unify knowledge governance and safety as knowledge was unfold throughout a number of places and codecs. Within the Lakehouse, all knowledge is in a single place and one format (be it unstructured, structured, or stream), therefore reaching general governance is way less complicated to attain.
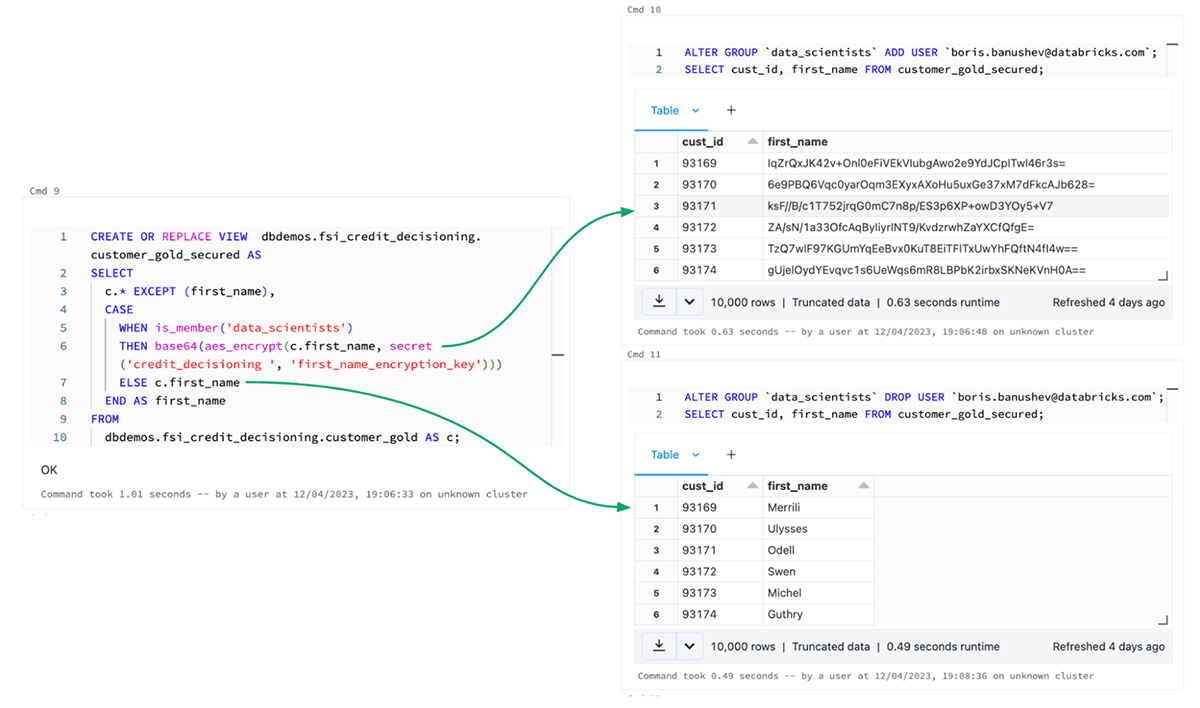
For instance, within the image beneath we are able to see how easy it’s to implement row stage masking on delicate knowledge utilizing easy SQL statements. On this situation we need to guarantee that customers from the “data-scientists” group can’t see the precise first names of the financial institution’s clients, therefore we masks the column. Everybody else, alternatively, is ready to see these names.
- Now that each one required knowledge has been ingested, cleaned, and correctly secured and ruled, we are able to transfer to exploratory knowledge evaluation (EDA) and have engineering. We retailer the options into the Databricks Characteristic Retailer to have a centralized repository and share options and in addition be sure that the identical code used to compute the characteristic values is used for mannequin coaching and inference.This can even allow us to attain the identical stage of high quality, discoverability and governance for our characteristic units because the Databricks Characteristic Retailer can be constructed on high of Delta tables.
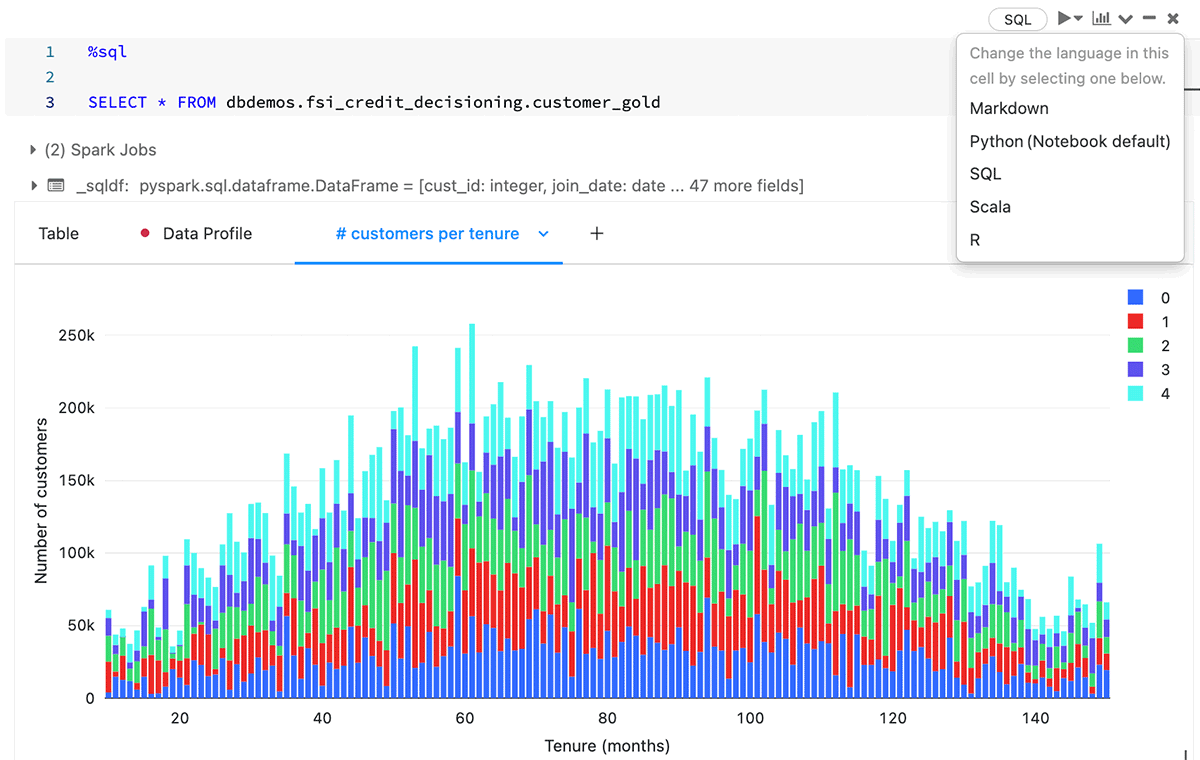
Within the image beneath we are able to see the automated dashboarding within the Databricks Notebooks. This characteristic, together with the automated knowledge profiling, the flexibility for many individuals to work in the identical Pocket book in numerous languages (SQL and python), and the embedded repository options for full CI/CD, makes cross staff collaboration extraordinarily quick on the Lakehouse. The power to experiment rapidly by way of characteristic engineering and mannequin coaching is a key to producing top quality machine studying fashions.
- As soon as the options are generated we are able to use Databricks’s glass-blox AutoML functionality to construct a baseline mannequin by way of automated mannequin choice and hyperparameter tuning. MLFlow makes it simple to match a whole bunch of fashions, consider them based mostly on dozens of metrics (within the image beneath), rapidly deploy fashions for batch and real-time inferencing utilizing MLOps finest practices, monitor these fashions for knowledge and idea drifts, and even obtain A/B take a look at deployment.
The batch inferencing on this resolution is used for predicting the creditworthiness of underbanked clients and in addition the chance of default (and the loss-given default) of present debt holders. The actual-time inferencing is utilized in a Purchase now, Pay later use case, the place the client doesn’t have the required quantity to finish a monetary transaction and the financial institution needs to calculate in real-time whether or not the client’s credit score restrict will be quickly elevated in order that the transaction is accomplished.
- The following step is to make use of Databricks SQL and visualize all knowledge and machine studying predictions collectively. We already noticed some dashboards constructed on the Lakehouse within the enterprise outcomes sections of the weblog.
- As talked about above, it is very important be capable of empower not solely knowledge groups, however non-data groups and enterprise customers to entry any knowledge they want, because the finish customers of a credit score determination or default prediction usually are not the info scientists and engineers, however the enterprise customers. The latter, nonetheless, don’t typically have entry to this data in a well timed and structured method. Via Delta Sharing, monetary establishments can securely share any knowledge with any recipient even when they don’t seem to be Databricks customers.
- With a purpose to productionalize every thing right into a single knowledge pipeline containing knowledge ingestion, ELT, machine studying coaching and deploying, knowledge sharing and dashboarding we use Databricks Workflows. Workflows create sturdy pipelines of varied knowledge belongings – be it a Databricks Pocket book, DBSQL Dashboard, DLT pipelines, or python information, every thing can work collectively in a unified workflow.
- Lastly, let’s use the unified knowledge lineage that Databricks Unity Catalog routinely captures (within the image beneath). We will see that in the identical lineage graph we are able to discover completely any knowledge asset, together with the ingested and cleaned knowledge by way of DLT, the characteristic units saved within the Characteristic Retailer, in addition to the batch predictions created by MLFlow after coaching the machine studying mannequin.
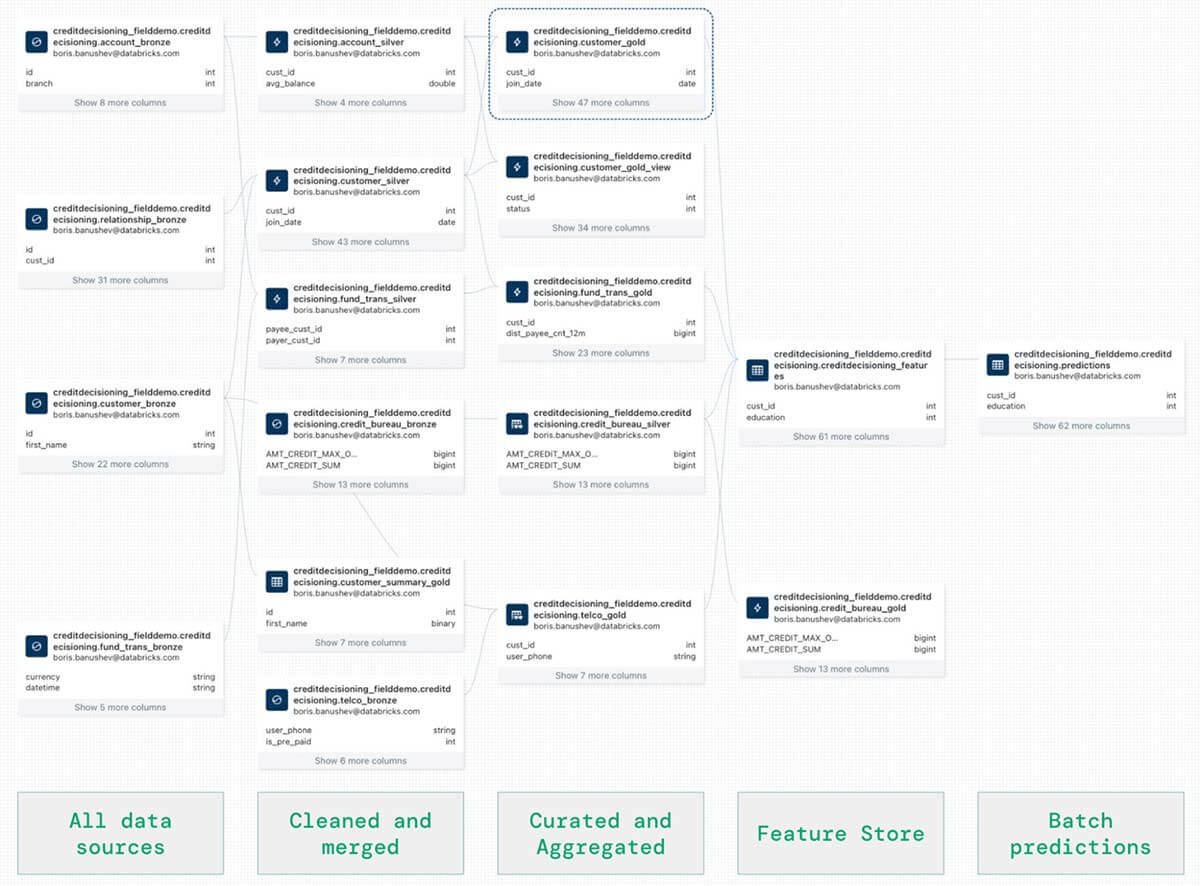
Such finish to finish knowledge lineage is extraordinarily crucial for understanding compliance, audit, observability, and discoverability of information.
These are three quite common situations, the place full knowledge lineage turns into extremely essential:
- Explainability – we have to have the technique of tracing options utilized in machine studying to the uncooked knowledge that created these options,
- Tracing lacking values in a dashboard or ML mannequin to the origin,
- Discovering particular knowledge – organizations have a whole bunch and even 1000’s of information tables and sources. Discovering the desk or column that incorporates particular data will be daunting with out correct discoverability instruments.
Conclusion
A number of the most buyer obsessed innovations over the past 20 years have been underpinned by higher automation. The iPhone launched software program to detect multi-touch as an alternative of counting on handbook {hardware} upgrades. PayPal revolutionized funds by leveraging the peer-to-peer community. And GPT-3 has modified the world by automating refined textual content technology that has permeated our each day lives outdoors of labor. Finally, credit score decisioning is benefiting from the identical ranges of innovation and automation. As an alternative of manually approving loans with incomplete knowledge, any agency (financial institution or in any other case) can now lengthen credit score to new people by routinely ingesting various knowledge sources, governing PII to enhance time to worth, and automating the credit score decisioning utilizing ML and AI. The credit score decisioning framework on the Databricks Lakehouse is designed to codify precisely the simplicity of this automation framework with software program supplied by Databricks.
To get began and construct a credit score knowledge platform for your corporation, go to the demo at dbdemos.ai to get began and be taught extra.