

Navigating the intricate panorama of generative AI, notably within the text-to-image (T2I) synthesis area, presents a formidable problem: precisely producing photos depicting a number of objects, every with particular spatial relationships and attributes. Regardless of their outstanding capabilities, conventional state-of-the-art fashions, akin to Steady Diffusion and DALL-E 3, usually stumble when confronted with advanced prompts requiring exact management over a number of objects’ spatial association and interplay.
This hole within the expertise’s skill to interpret and visually render detailed textual descriptions has prompted a workforce of researchers from the Hong Kong College of Science and Expertise, the College of California Los Angeles, Penn State College, and the College of Maryland to develop a groundbreaking answer: MuLan, a multimodal-LLM agent.
MuLan revolutionizes producing photos from the textual content by adopting a method paying homage to a human artist’s methodology. At its core, MuLan makes use of a big language mannequin (LLM) to dissect a fancy immediate into manageable sub-tasks, every devoted to producing one object about these beforehand created. This sequential era course of permits for meticulous management over every object’s spatial positioning and attributes, successfully addressing the constraints of current T2I fashions. MuLan employs a vision-language mannequin (VLM) to offer important suggestions, correcting any deviations from the unique immediate in actual time. This modern suggestions loop ensures that the generated photos intently align with the textual descriptions, enhancing the accuracy and constancy of the output.
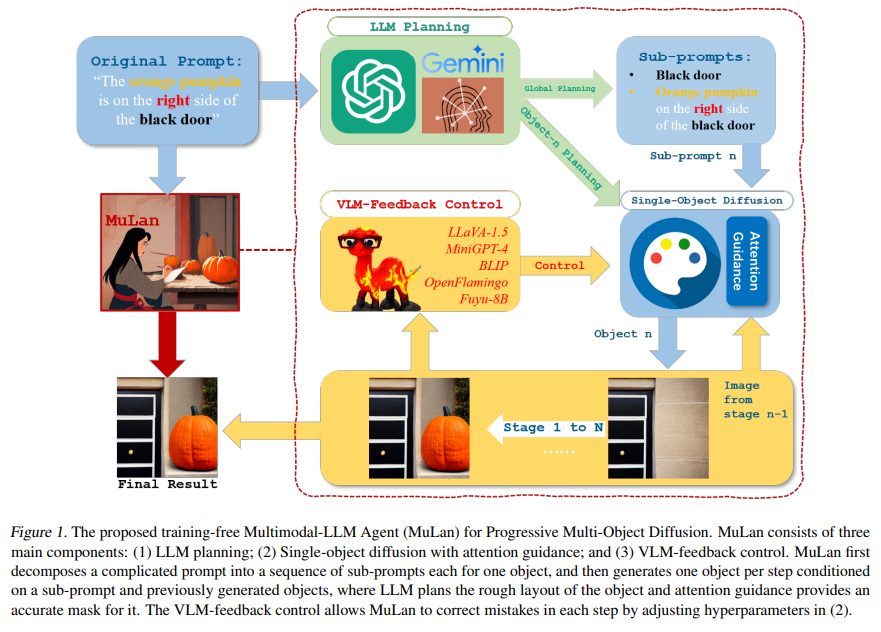
The analysis of MuLan’s efficiency concerned a complete dataset of prompts, encompassing many objects, spatial relationships, and attributes. The outcomes have been unequivocal, demonstrating MuLan’s superior functionality in dealing with advanced picture era duties with outstanding precision. In comparison with baseline fashions, MuLan constantly outperformed in metrics akin to object completeness, attribute accuracy, and the upkeep of spatial relationships. These findings spotlight MuLan’s potential to redefine requirements in generative AI and underscore the mannequin’s skill to bridge the hole between textual prompts and their visible representations.

MuLan signifies a pivotal development within the area of T2I synthesis, providing a novel and efficient answer to the challenges of producing detailed, multi-object photos from textual content. By mimicking the iterative and corrective processes employed by human artists, MuLan opens new horizons for AI-driven artistic endeavors. The implications of this expertise lengthen far past the rapid advantages of enhanced picture era, promising to catalyze innovation throughout a broad spectrum of functions in digital artwork, design, and multimedia content material creation.
In conclusion, the analysis could be summarized as follows:
- MuLan is a groundbreaking step in generative AI for T2I synthesis, addressing the problem of advanced prompts.
- It leverages an LLM for job decomposition and a VLM for suggestions, making certain excessive constancy to prompts.
- Superior efficiency in object completeness, attribute accuracy, and spatial relationships.
- Potential functions span digital artwork, design, and past, highlighting MuLan’s versatile influence.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
You might also like our FREE AI Programs….
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about expertise and need to create new merchandise that make a distinction.