

Key Takeaways
- Thought Propagation (TP) is a novel methodology that enhances the advanced reasoning skills of Giant Language Fashions (LLMs).
- TP leverages analogous issues and their options to enhance reasoning, somewhat than making LLMs cause from scratch.
- Experiments throughout varied duties present TP considerably outperforms baseline strategies, with enhancements starting from 12% to fifteen%.
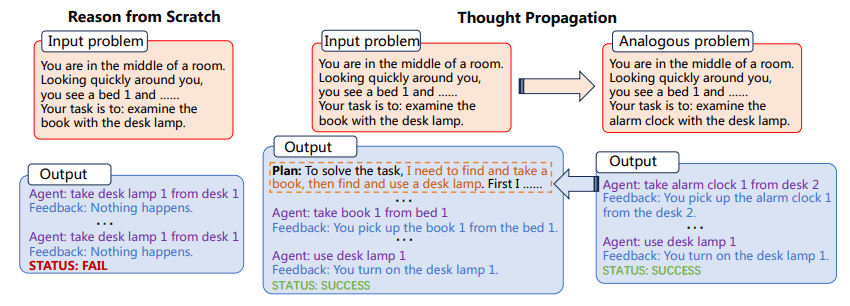
TP first prompts LLMs to suggest and resolve a set of analogous issues which might be associated to the enter one. Then, TP reuses the outcomes of analogous issues to instantly yield a brand new answer or derive a knowledge-intensive plan for execution to amend the preliminary answer obtained from scratch.
The flexibility and computational energy of Giant Language Fashions (LLMs) are simple, but they aren’t with out restrict. One of the crucial important and constant challenges to LLMs is their basic strategy to problem-solving, consisting of reasoning from first rules for each new activity encountered. That is problematic, because it permits for a excessive diploma of adaptability, but in addition will increase the probability of errors, significantly in duties that require multi-step reasoning.
The problem of “reasoning from scratch” is particularly pronounced in advanced duties that demand a number of steps of logic and inference. For instance, if an LLM is requested to search out the shortest path in a community of interconnected factors, it sometimes wouldn’t leverage prior information or analogous issues to discover a answer. As a substitute, it could try to unravel the issue in isolation, which might result in suboptimal outcomes and even outright errors. Enter Thought Propagation (TP), a technique designed to reinforce the reasoning capabilities of LLMs. TP goals to beat the inherent limitations of LLMs by permitting them to attract from a reservoir of analogous issues and their corresponding options. This revolutionary strategy not solely improves the accuracy of LLM-generated options but in addition considerably enhances their capacity to sort out multi-step, advanced reasoning duties. By leveraging the ability of analogy, TP gives a framework that amplifies the innate reasoning capabilities of LLMs, bringing us one step nearer to the belief of actually clever synthetic programs.
Thought Propagation includes two most important steps:
- First, the LLM is prompted to suggest and resolve a set of analogous issues associated to the enter downside
- Subsequent, the options to those analogous issues are used to both instantly yield a brand new answer or to amend the preliminary answer
The method of figuring out analogous issues permits the LLM to reuse problem-solving methods and options, thereby enhancing its reasoning skills. TP is suitable with current prompting strategies, offering a generalizable answer that may be integrated into varied duties with out important task-specific engineering.
Determine 1: The Thought Propagation course of (Picture from paper)
Furthermore, the adaptability of TP shouldn’t be underestimated. Its compatibility with current prompting strategies makes it a extremely versatile instrument. Which means that TP isn’t restricted to any particular type of problem-solving area. This opens up thrilling avenues for task-specific fine-tuning and optimization, thereby elevating the utility and efficacy of LLMs in a broad spectrum of purposes.
The implementation of Thought Propagation could be built-in into the workflow of current LLMs. For instance, in a Shortest-path Reasoning activity, TP might first resolve a set of less complicated, analogous issues to know varied attainable paths. It could then use these insights to unravel the advanced downside, thereby rising the probability of discovering the optimum answer.
Instance 1
- Job: Shortest-path Reasoning
- Analogous Issues: Shortest path between level A and B, Shortest path between level B and C
- Closing Resolution: Optimum path from level A to C contemplating the options of analogous issues
Instance 2
- Job: Inventive Writing
- Analogous Issues: Write a brief story about friendship, Write a brief story about belief
- Closing Resolution: Write a fancy brief story that integrates themes of friendship and belief
The method includes fixing these analogous issues first, after which utilizing the insights gained to sort out the advanced activity at hand. This methodology has demonstrated its effectiveness throughout a number of duties, showcasing substantial enhancements in efficiency metrics.
Thought Propagation’s implications transcend merely enhancing current metrics. This prompting approach has the potential to change how we perceive and deploy LLMs. The methodology underscores a shift from remoted, atomic problem-solving in the direction of a extra holistic, interconnected strategy. It prompts us to contemplate how LLMs can be taught not simply from knowledge, however from the method of problem-solving itself. By repeatedly updating their understanding by way of the options to analogous issues, LLMs geared up with TP are higher ready to sort out unexpected challenges, rendering them extra resilient and adaptable in quickly evolving environments.
Thought Propagation is a promising addition to the toolbox of prompting strategies geared toward enhancing the capabilities of LLMs. By permitting LLMs to leverage analogous issues and their options, TP gives a extra nuanced and efficient reasoning methodology. Experiments verify its efficacy, making it a candidate technique for enhancing the efficiency of LLMs throughout quite a lot of duties. TP might in the end characterize a big step ahead within the seek for extra succesful AI programs.
Matthew Mayo (@mattmayo13) holds a Grasp’s diploma in pc science and a graduate diploma in knowledge mining. As Editor-in-Chief of KDnuggets, Matthew goals to make advanced knowledge science ideas accessible. His skilled pursuits embrace pure language processing, machine studying algorithms, and exploring rising AI. He’s pushed by a mission to democratize information within the knowledge science group. Matthew has been coding since he was 6 years outdated.