

Introduction
On this weblog submit we dive into inference with DBRX, the open state-of-the-art giant language mannequin (LLM) created by Databricks (see Introducing DBRX). We talk about how DBRX was designed from the bottom up for each environment friendly inference and superior mannequin high quality, we summarize how we achieved cutting-edge efficiency on our platform, and finish with some sensible recommendations on tips on how to work together with the mannequin.
Mosaic AI Mannequin Serving offers on the spot entry to DBRX Instruct on a high-performance, production-grade, enterprise-ready platform. Customers can immediately experiment and construct prototype purposes, then easily transition to our production-grade inference platform.
Strive DBRX now!
We have seen super demand for DBRX Instruct. Lots of of enterprises have begun to discover the mannequin’s capabilities on the Databricks platform.
Databricks is a key companion to Nasdaq on a few of our most necessary knowledge programs. They proceed to be on the forefront of business in managing knowledge and leveraging AI, and we’re excited concerning the launch of DBRX. The mixture of robust mannequin efficiency and favorable serving economics is the type of innovation we’re searching for as we develop our use of Generative AI at Nasdaq.
— Mike O’Rourke, Head of AI and Information Providers, NASDAQ
To help the ML group, we additionally open sourced the mannequin structure and weights, and contributed optimized inference code to main open supply tasks like vLLM and TRT-LLM.
DBRX-Instruct’s integration has been an exceptional addition to our suite of AI fashions and highlights our dedication to supporting open-source. It is delivering quick, high-quality solutions to our customers’ numerous questions. Although it is nonetheless model new on You.com, we’re already seeing the joy amongst customers and stay up for its expanded use.
— Saahil Jain, Senior Engineering Supervisor, You.com
At Databricks, we’re centered on constructing a Information Intelligence Platform: an intelligence engine infused with generative AI, constructed on prime of our unified knowledge lakehouse. A robust instantly-available LLM like DBRX Instruct is a crucial constructing block for this. Moreover, DBRX’s open weights empowers our prospects to additional prepare and adapt DBRX to increase its understanding to the distinctive nuances of their goal area and their proprietary knowledge.
DBRX Instruct is an particularly succesful mannequin for purposes which might be necessary to our enterprise prospects (code era, SQL, and RAG). In retrieval augmented era (RAG), content material related to a immediate is retrieved from a database and introduced alongside the immediate to offer the mannequin extra info than it will in any other case have. To excel at this, a mannequin should not solely help lengthy inputs (DBRX was skilled with as much as 32K token inputs) nevertheless it should additionally have the ability to discover related info buried deep in its inputs (see the Misplaced within the Center paper).
On long-context and RAG benchmarks, DBRX Instruct performs higher than GPT-3.5 Turbo and main open LLMs. Desk 1 highlights the standard of DBRX Instruct on two RAG benchmarks – Pure Questions and HotPotQA – when the mannequin can also be supplied with the highest 10 passages retrieved from a corpus of Wikipedia articles.
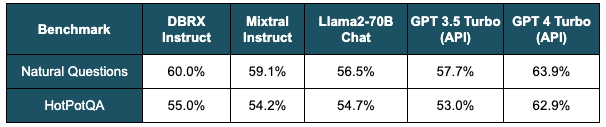
Desk 1. RAG benchmarks. The efficiency of varied fashions measured when every mannequin is given the highest 10 passages retrieved from a Wikipedia corpus utilizing bge-large-en-v1.5. Accuracy is measured by matching throughout the mannequin’s reply. DBRX Instruct has the best rating aside from GPT-4 Turbo.
An Inherently Environment friendly Structure
DBRX is a Combination-of-Consultants (MoE) decoder-only, transformer mannequin. It has 132 billion whole parameters, however solely makes use of 36 billion lively parameters per token throughout inference. See our earlier weblog submit for particulars on the way it was skilled.
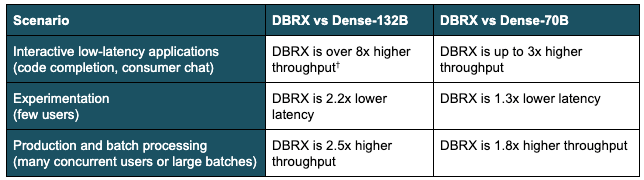
Desk 2: MoE inference effectivity in varied eventualities. The desk summarizes the benefit an MoE like DBRX has over a comparably sized dense mannequin and over the favored dense 70B mannequin kind issue († max output tokens per sec @ time per output token goal < 30 ms). This abstract relies on a wide range of benchmarks on H100 servers with 8-way tensor parallelism and 16-bit precision. Figures 1 and a couple of present some underlying particulars.
We selected the MoE structure over a dense mannequin not solely as a result of MoEs are extra environment friendly to coach, but additionally as a result of serving time advantages. Bettering fashions is a difficult job: we want to scale parameter counts—which our analysis has proven to predictably and reliably enhance mannequin capabilities—with out compromising mannequin usability and velocity. MoEs enable parameter counts to be scaled with out proportionally giant will increase in coaching and serving prices.
DBRX’s sparsity bakes inference effectivity into the structure: as an alternative of activating all of the parameters, solely 4 out of the overall 16 “specialists” per layer are activated per enter token. The efficiency impression of this sparsity is dependent upon the batch measurement, as proven in figures 1 and a couple of. As we mentioned in an earlier weblog submit, each Mannequin Bandwidth Utilization (MBU) and Mannequin Flops Utilization (MFU) decide how far we are able to push inference velocity on a given {hardware} setup.
First, at low batch sizes, DBRX has lower than 0.4x the request latency of a comparably-sized dense mannequin. On this regime the mannequin is reminiscence–bandwidth certain on excessive finish GPUs like NVIDIA H100s. Merely put, fashionable GPUs have tensor cores that may carry out trillions of floating level operations per second, so the serving engine is bottlenecked by how briskly reminiscence can present knowledge to the compute items. When DBRX processes a single request, it doesn’t need to load all 132 billion parameters; it solely finally ends up loading 36 billion parameters. Determine 1 highlights DBRX’s benefit at small batch sizes, a bonus which narrows however stays giant at bigger batch sizes.
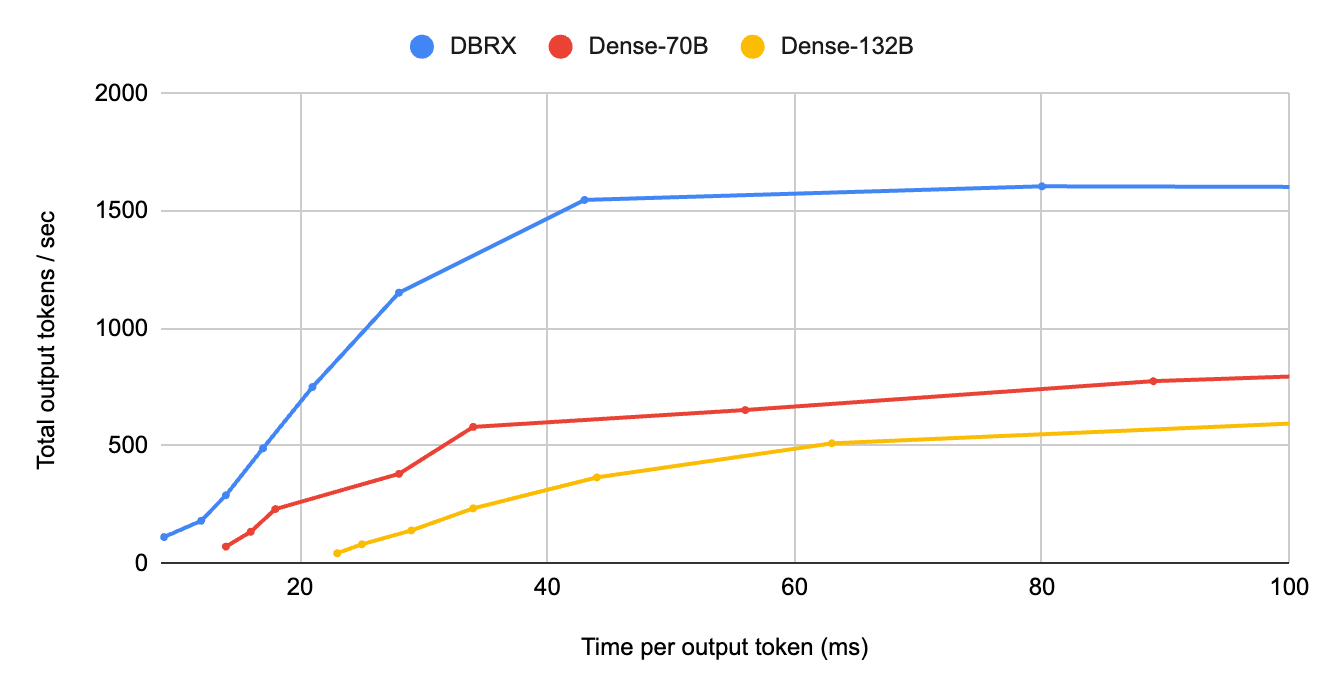
Determine 1: MoEs are considerably higher for interactive purposes. Many purposes must generate responses inside a strict time price range. Evaluating an MoE like DBRX to dense fashions, we see that DBRX is ready to generate over 8x as many whole tokens per second if the goal is under 30 ms per output token. This implies mannequin servers can deal with an order of magnitude extra concurrent requests with out compromising particular person person expertise. These benchmarks have been run on H100 servers utilizing 16-bit precision and 8-way tensor parallelism with optimized inference implementations for every mannequin.
Second, for workloads which might be compute certain—that’s, bottlenecked by the velocity of the GPU—the MoE structure considerably reduces the overall variety of computations that must happen. Which means that as concurrent requests or enter immediate lengths improve, MoE fashions scale considerably higher than their dense counterparts. In these regimes, DBRX can improve decode throughput as much as 2.5x relative to a comparable dense mannequin, as highlighted in determine 2. Customers performing Retrieval Augmented Technology (RAG) workloads will see an particularly giant profit, since these workloads usually pack a number of thousand tokens into the enter immediate. As do workloads utilizing DBRX to course of many paperwork with Spark and different batch pipelines.
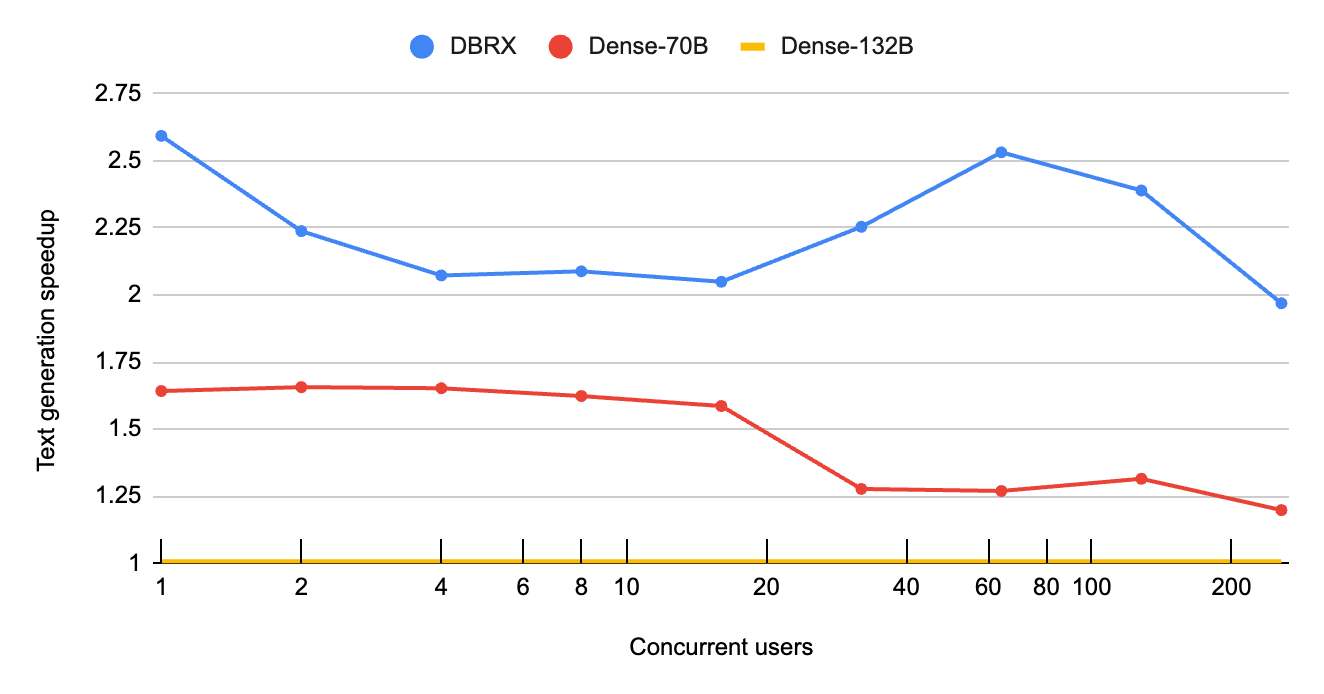
Determine 2: MoE’s have superior scaling. Evaluating an MoE like DBRX to dense fashions, we see that its textual content era charge* scales a lot better at giant batch sizes (* whole output tokens per second). DBRX persistently has 2x or greater throughput in comparison with a equally sized dense mannequin (Dense-132B). DBRX’s speedup accelerates at giant batch sizes: above 32 concurrent customers DBRX reaches 2x the velocity of a number one dense 70B mannequin. These benchmarks used the identical setup as these in determine 1.
Positive-Grained Combination-of-Consultants
DBRX is a fine-grained MoE, which means it makes use of a bigger variety of smaller specialists. DBRX has 16 specialists and chooses 4, whereas Mixtral and Grok-1 have 8 specialists and select 2. This offers 65x extra attainable mixtures of specialists and we discovered that this improves mannequin high quality.
Moreover, DBRX is a comparatively shallow and huge mannequin so its inference efficiency scales higher with tensor parallelism. DBRX and Mixtral-8x22B have roughly the identical variety of parameters (132B for DBRX vs 140B for Mixtral) however Mixtral has 1.4x as many layers (40 vs 56). In comparison with Llama2, a dense mannequin, DBRX has half the variety of layers (40 vs 80). Extra layers tends to end in dearer cross-GPU calls when working inference on a number of GPUs (a requirement for fashions this huge). DBRX’s relative shallowness is one motive it has a better throughput at medium batch sizes (4 – 16) in comparison with Llama2-70B (see Determine 1).
To keep up prime quality with many small specialists, DBRX makes use of “dropless” MoE routing, a way pioneered by our open-source coaching library MegaBlocks (see Bringing MegaBlocks to Databricks). MegaBlocks has additionally been used to develop different main MoE fashions comparable to Mixtral.
Earlier MoE frameworks (Determine 3) pressured a tradeoff between mannequin high quality and {hardware} effectivity. Consultants had a hard and fast capability so customers had to decide on between often dropping tokens (decrease high quality) or losing computation as a consequence of padding (decrease {hardware} effectivity). In distinction (Determine 4), MegaBlocks (paper) reformulated the MoE computation utilizing block-sparse operations in order that skilled capability might be dynamically sized and effectively computed on fashionable GPU kernels.

Determine 3: A standard Combination-of-Consultants (MoE) layer. A router produces a mapping of enter tokens to specialists and produces chances that mirror the arrogance of the assignments. Tokens are despatched to their top_k specialists (in DBRX top_k is 4). Consultants have fastened enter capacities and if the dynamically routed tokens exceed this capability, some tokens are dropped (see prime purple space). Conversely, if fewer tokens are routed to an skilled, computation capability is wasted with padding (see backside purple space).
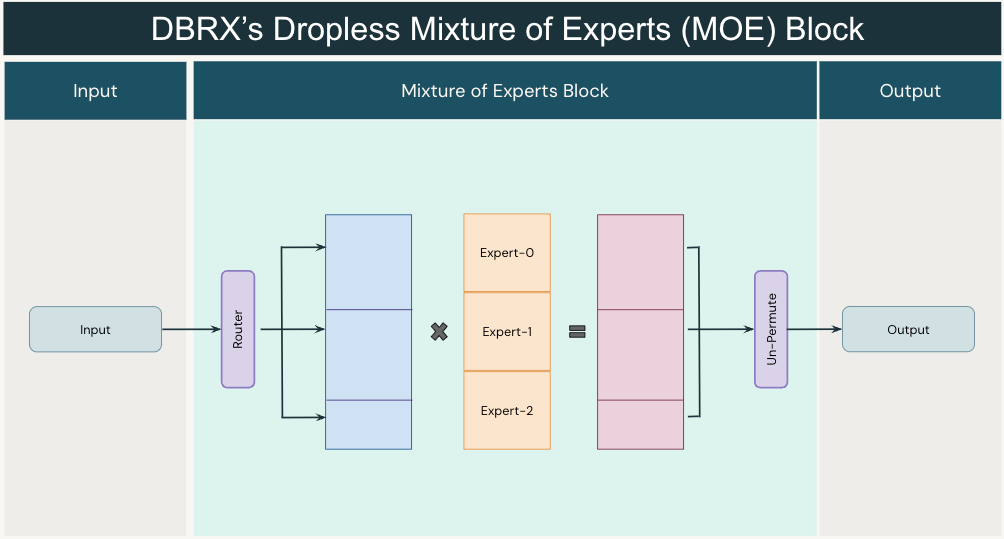
Determine 4: A dropless MoE layer. The router works as earlier than, routing every token to its top_k specialists. Nevertheless we now use variable sized blocks and environment friendly matrix multiplications to keep away from dropping tokens or losing capability. MegaBlocks proposes utilizing block-sparse matrix multiplications. In observe, we use optimized GroupGEMM kernels for inference.
Engineered for Efficiency
As defined within the earlier part, inference with the DBRX structure has innate benefits. Nonetheless, reaching state-of-the-art inference efficiency requires a considerable quantity of cautious engineering.
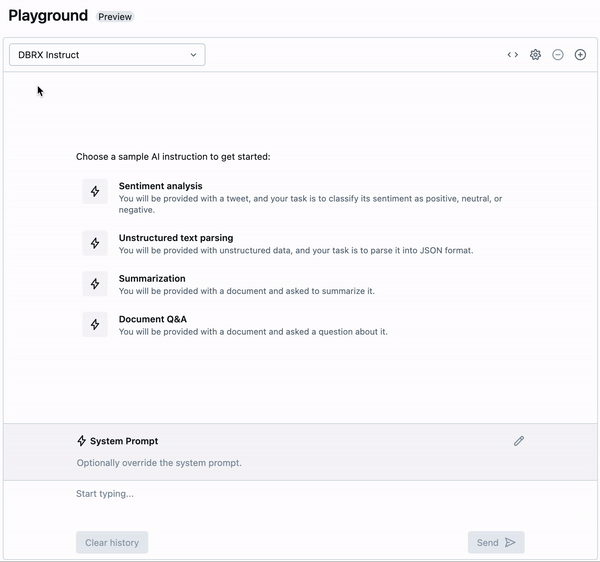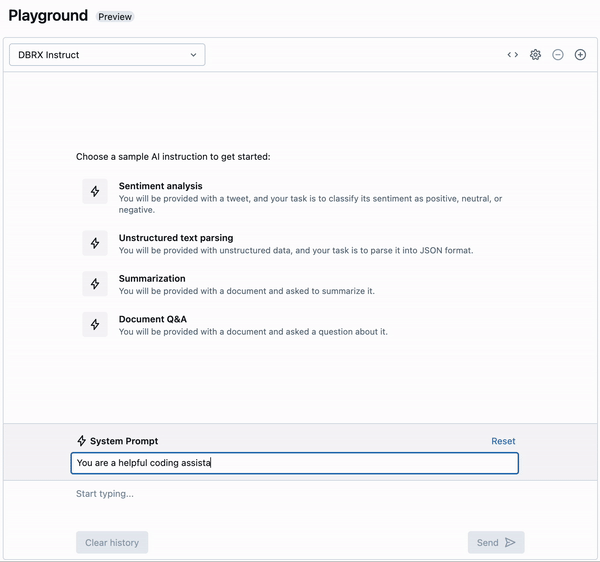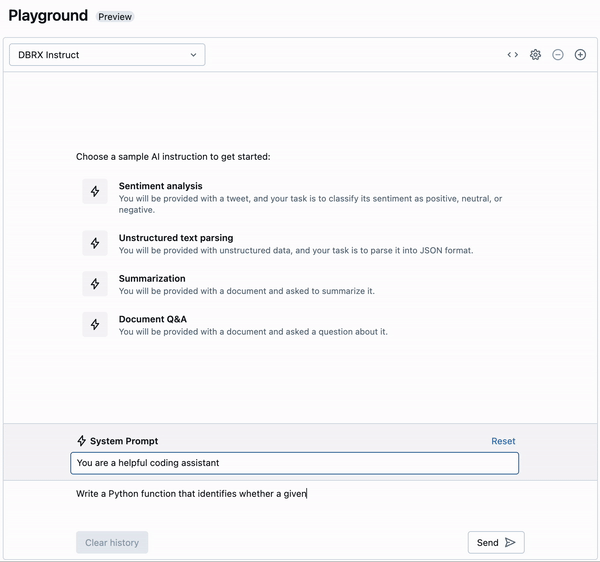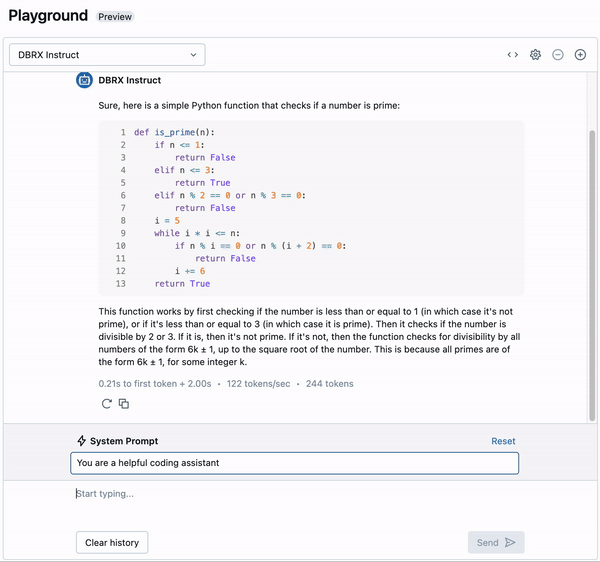
Determine 5: DBRX within the Databricks AI Playground. Basis Mannequin APIs customers can anticipate to see textual content era speeds of as much as ~150 tokens per second for DBRX.
Now we have made deep investments in our high-performance LLM inference stack and have applied new DBRX-focused optimizations. Now we have utilized many optimizations comparable to fused kernels, GroupGEMMs for MoE layers, and quantization for DBRX.
Optimized for enterprise use instances. Now we have optimized our server to help workloads with numerous visitors at excessive throughput, with out degrading latency under acceptable ranges—particularly for the lengthy context requests that DBRX excels on. As mentioned in a earlier weblog submit, constructing performant inference companies is a difficult drawback; numerous care have to be put into reminiscence administration and efficiency tuning to take care of excessive availability and low latency. We make the most of an aggregated steady batching system to course of a number of requests in parallel, sustaining excessive GPU utilization and offering robust streaming efficiency.
Deep multi-GPU optimizations. Now we have applied a number of customized methods impressed by state-of-the-art serving engines comparable to NVIDIA’s TensorRT-LLM and vLLM. This contains customized kernels implementing operator fusions to remove pointless GPU reminiscence reads/writes in addition to rigorously tuned tensor parallelism and synchronization methods. We explored completely different types of parallelism methods comparable to tensor parallel and skilled parallel and recognized their comparative benefits.
Quantization and high quality. Quantization – a way for making fashions smaller and sooner – is very necessary for fashions the scale of DBRX. The principle barrier to deploying DBRX is its reminiscence necessities: at 16-bit precision, we suggest a minimal of 4x80GB NVIDIA GPUs. Having the ability to serve DBRX in 8-bit precision halves its serving prices and frees it to run on lower-end GPUs comparable to NVIDIA A10Gs. {Hardware} flexibility is especially necessary for enterprise customers who care about geo-restricted serving in areas the place the supply of high-end GPUs is scarce. Nevertheless, as we mentioned in our earlier weblog submit, nice care have to be taken when incorporating quantization. In our rigorous high quality evals, we discovered that the default INT8 quantization strategies in TRT-LLM and vLLM result in mannequin high quality degradation in sure generative duties. A few of this degradation will not be obvious in benchmarks like MMLU the place the fashions are usually not producing lengthy sequences. The most important high quality issues we now have seen have been flagged by domain-specific (e.g., HumanEval) and long-context (e.g., ZeroSCROLLS) benchmarks. As a person of Databricks’ inference merchandise, you’ll be able to belief that our engineering group rigorously ensures the standard of our fashions at the same time as we make them sooner.
Previously, we now have launched many blogs on our engineering practices for quick and safe inference serving. For extra particulars, please see our earlier weblog posts linked under:
Determine 6: Of us on X actually like DBRX token era velocity (tweet). Our Hugging Face House demo makes use of Databricks Basis Mannequin APIs as its backend.
Inference Suggestions and Methods
On this part we share some methods for developing good prompts. Immediate particulars are particularly necessary for system prompts.
DBRX Instruct offers excessive efficiency with easy prompts. Nevertheless, like different LLMs, well-crafted prompts can considerably improve its efficiency and align its outputs together with your particular wants. Keep in mind that these fashions use randomness: the identical immediate evaluated a number of instances can lead to completely different outputs.
We encourage experimentation to search out what works greatest for every of your use-cases. Immediate engineering is an iterative course of. The start line is commonly a “vibe verify” – manually assessing response high quality with just a few instance inputs. For advanced purposes, it is best to observe this by developing an empirical analysis framework after which iteratively evaluating completely different prompting methods.
Databricks offers an easy-to-use UI to help this course of, in AI Playground and with MLflow. We additionally present mechanisms to run these evaluations at scale, comparable to Inference Tables and knowledge evaluation workflows.
System Prompts
System prompts are a approach to remodel the generic DBRX Instruct mannequin right into a task-specific mannequin. These prompts set up a framework for a way the mannequin ought to reply and may present further context for the dialog. They’re additionally typically used to assign a task to modulate the mannequin’s response fashion (“you’re a kindergarten instructor”).
DBRX Instruct’s default system immediate turns the mannequin right into a common objective enterprise chatbot with fundamental security guardrails. This conduct will not be a very good match for each buyer. The system immediate may be modified simply within the AI Playground or utilizing the “system” position in chat API requests.
When a customized system immediate is offered, it utterly overrides our default system immediate. Right here is an instance system immediate which makes use of few-shot prompting to show DBRX Instruct right into a PII detector.
"""
The assistant is a classification mannequin and solely responds by
classifying the person's textual content as CONTAINS_PII or NO_PII. The assistant
solely responds with CONTAINS_PII or NO_PII. DO NOT return every other
textual content.
person
As soon as you might be pleased with it, be happy to log off on the desk up the
prime.
assistant
NO_PII
person
Through the Zoom name on April tenth, Sarah talked about that she's shifting
to 123 Maple Road, Portland, subsequent month as a consequence of her promotion at Acme
Corp.
assistant
CONTAINS_PII
person
An worker at a big tech firm talked about they not too long ago obtained a
promotion and can be relocating to a special metropolis subsequent month for a
new challenge.
assistant
NO_PII
person
John Smith, a 45-year-old from Los Angeles, has been prescribed
treatment for his Sort 2 diabetes.
assistant
CONTAINS_PII
"""Prompting Suggestions
Listed here are just a few tricks to get you began prompting DBRX Instruct.
First steps. Begin with the best prompts you’ll be able to, to keep away from pointless complexity. Clarify what you need in an easy method, however present enough element and related context for the duty. These fashions can not learn your thoughts. Consider them as an intelligent-yet-inexperienced intern.
Use exact directions. Instruction-following fashions like DBRX Instruct have a tendency to offer one of the best outcomes with exact directions. Use lively instructions (“classify”, “summarize”, and many others) and express constraints (e.g. “don’t” as an alternative of “keep away from”). Use exact language (e.g. to specify the specified size of the response use “clarify in about 3 sentences” fairly than “clarify in just a few sentences”). Instance: “Clarify what makes the sky blue to a 5 12 months previous in 50 or fewer phrases” as an alternative of “Clarify briefly and in easy phrases why the sky is blue.”
Train by instance. Generally, fairly than crafting detailed common directions, one of the best strategy is to supply the mannequin with just a few examples of inputs and outputs. The pattern system immediate above makes use of this system.That is known as “few-shot” prompting. Examples can floor the mannequin in a selected response format and steer it in direction of the supposed resolution house. Examples needs to be numerous and supply good protection. Examples of incorrect responses with details about why they have been flawed may be very useful. Sometimes not less than 3-5 examples are wanted.
Encourage step-by-step drawback fixing. For advanced duties, encouraging DBRX Instruct to proceed incrementally in direction of an answer typically works higher than having it generate a solution instantly. Along with enhancing reply accuracy, step-by-step responses present transparency and make it simpler to investigate the mannequin’s reasoning failures. There are just a few methods on this space. A job may be decomposed right into a sequence of easier sub-tasks (or recursively as a tree of easier and easier sub-tasks). These sub-tasks may be mixed right into a single immediate, or prompts may be chained collectively, passing the mannequin’s response to 1 because the enter to the following. Alternatively, we are able to ask DBRX Instruct to supply a “chain of thought” earlier than its reply. This will result in greater high quality solutions by giving the mannequin “time to assume” and inspiring systematic drawback fixing. Chain-of-thought instance: “I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My companion then purchased 6 extra muffins and ate 2. Do I’ve a main variety of muffins? Suppose step-by-step.”
Formatting issues. Like different LLMs, immediate formatting is necessary for DBRX Instruct. Directions needs to be positioned initially. For structured prompts (few-shot, step-by-step, and many others) when you use delimiters to mark part boundaries (markdown fashion ## headers, XML tags, triple citation marks, and many others), use a constant delimiter fashion all through the dialog.
If you’re fascinated by studying extra about immediate engineering, there are various assets available on-line. Every mannequin has idiosyncrasies, DBRX Instruct isn’t any exception. There are, nonetheless, many common approaches that work throughout fashions. Collections comparable to Anthropic’s immediate library could be a good supply of inspiration.
Technology Parameters
Along with prompts, inference request parameters impression how DBRX Instruct generates textual content.
Producing textual content is a stochastic course of: the identical immediate evaluated a number of instances can lead to completely different outputs. The temperature parameter may be adjusted to regulate the diploma of randomness. temperature is a quantity that ranges from 0 to 1. Select decrease numbers for duties which have well-defined solutions (comparable to query answering and RAG) and better numbers for duties that profit from creativity (writing poems, brainstorming). Setting this too excessive will end in nonsensical responses.
Basis Mannequin APIs additionally help superior parameters, comparable to enable_safety_mode (in non-public preview). This allows guardrails on the mannequin responses, detecting and filtering unsafe content material. Quickly, we’ll be introducing much more options to unlock superior use instances and provides prospects extra management of their manufacturing AI purposes.
Querying the Mannequin
You may start experimenting instantly in case you are a Databricks buyer through our AI Playground. In case you favor utilizing an SDK, our Basis Mannequin APIs endpoints are appropriate with the OpenAI SDK (you will have a Databricks private entry token).
from openai import OpenAI
import os
DATABRICKS_TOKEN = os.environ.get("DATABRICKS_TOKEN")
consumer = OpenAI(
api_key=DATABRICKS_TOKEN, # your private entry token
base_url='https://<workspace_id>.databricks.com/serving-endpoints',
# your Databricks workspace occasion
)
chat_completion = consumer.chat.completions.create(
messages=[
{
"role": "user",
"content": "Give me the character profile of a gumdrop obsessed
knight in JSON.",
}
],
mannequin="databricks-dbrx-instruct",
max_tokens=256
)
print(chat_completion.selections[0].message.content material)Conclusions
DBRX Instruct is one other vital stride in our mission to democratize knowledge and AI for each enterprise. We launched the DBRX mannequin weights and likewise contributed performance-optimized inference help to 2 main inference platforms: TensorRT-LLM and vLLM. Now we have labored carefully with NVIDIA in the course of the growth of DBRX to push the efficiency of TensorRT-LLM for MoE fashions as an entire. With vLLM, we now have been humbled by the overarching group help and urge for food for DBRX.
Whereas basis fashions like DBRX Instruct are the central pillars in GenAI programs, we’re more and more seeing Databricks prospects assemble compound AI programs as they transfer past flashy demos to develop prime quality GenAI purposes. The Databricks platform is constructed for fashions and different parts to work in live performance. For instance, we serve RAG Studio chains (constructed on prime of MLflow) that seamlessly join Vector Search to the Basis Mannequin APIs. Inference Tables enable safe logging, visualization, and metrics monitoring, facilitating the gathering of proprietary knowledge units which might then be used to coach or adapt open fashions like DBRX to drive steady software enchancment.
As an business we’re initially of the GenAI journey. At Databricks we’re excited to see what you construct with us! In case you aren’t a Databricks buyer but, join a free trial!

boAt Rockerz 255 Pro+ Bluetooth Wireless in Ear Earphones with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.2(Cosmic Grey)
₹999.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple iPhone 13 (128GB) - Starlight
₹49,499.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth in Ear Neckband with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.2(Active Black)
₹1,199.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Luxcell Wireless Mini 10k 10000mAh 15W Magnetic Wireless Fast Charging Smallest Power Bank with 22.5 Wired Output Compatible with iPhone 12 & Above & Other QI Enabled Devices(Black)
₹1,469.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oneplus Bullets Z2 Bluetooth Wireless in Ear Earphones with Mic, Bombastic Bass - 12.4 mm Drivers, 10 Mins Charge - 20 Hrs Music, 30 Hrs Battery Life, IP55 Dust and Water Resistant (Magico Black)
₹1,799.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics-NS1500 Laptop Stand Featuring Foldable Design, Anti-Slip Silicone Rubber Pads, Supports Maximum of 5kgs Weight Tabletop
₹299.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 101 Wired Optical Mouse with 1200 DPI, Plug & Play, Hi-Optical Tracking, 1.25M Cable Length, 30 Million Click Life(Black)
₹117.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP 680 Original Ink Advantage Cartridge (Black)
₹789.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Rellon Industries Study Table for Students Bed Table for Study Foldable Laptop Table Portable & Lightweight Mini Table Bed Reading Table,Laptop Stands, Laptop Desk (A1)
₹599.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive, Metal, Silver
₹439.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 4TB External Hard Drive HDD – USB 3.0 for PC, Mac, Xbox, & PlayStation - 1-Year Rescue Service (STGX4000400)
$99.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Noctua NT-H2 3.5g, Thermal Computer Paste incl. 3 Cleaning Wipes (3.5g)
$12.95 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Graphics Card GPU Brace Support, Video Card Sag Holder Bracket, GPU Stand, L
$9.39 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Rioddas External CD/DVD Drive for Laptop USB 3.0 CD/DVD Player Portable +/-RW Burner CD ROM Reader Rewriter Writer Disk Duplicator Compatible with Laptop Desktop PC Windows Apple Mac Pro Macbook Linux
$19.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)