

Giant imaginative and prescient language fashions (LVLMs) showcase highly effective visible notion and understanding capabilities. These achievements have additional impressed the analysis neighborhood to develop a wide range of multi-modal benchmarks constructed to discover the highly effective capabilities rising from LVLMs and supply a complete and goal platform for quantitatively evaluating the regularly evolving fashions. Nevertheless, after cautious analysis, the researchers recognized two major points:
1) Visible content material is pointless for a lot of samples, and
2) Unintentional knowledge leakage exists in LLM and LVLM coaching.
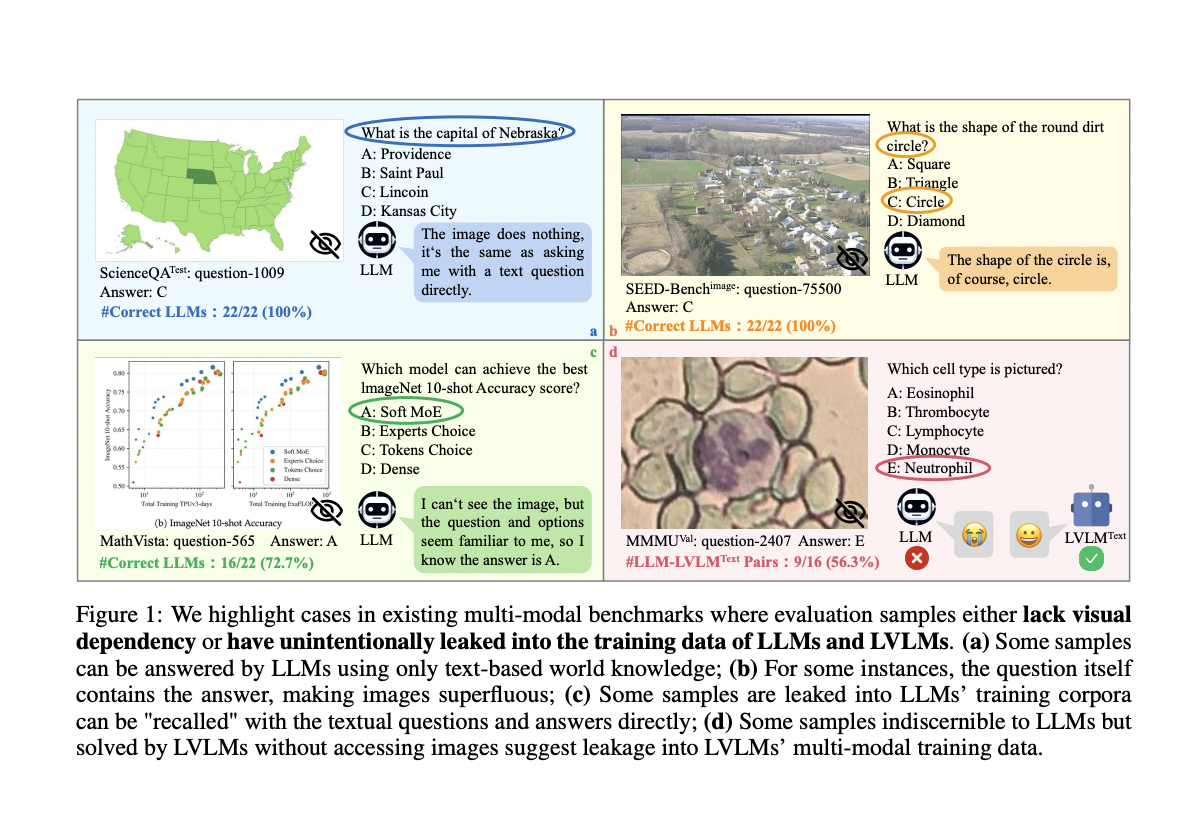
Early single-task benchmarks, reminiscent of VQA, MS-COCO, and OK-VQA, fail to holistically assess LVLMs’ common multi-modal notion and reasoning capabilities. To deal with this problem, complete multi-modal benchmarks have been constructed. For instance, SEED, MMBench, and MMMU present aggressive arenas for comprehensively evaluating cutting-edge LVLMs. Nevertheless, present evaluations of LVLMs overlook some essential points. On the one hand, they don’t assure that every one analysis samples can’t be appropriately answered with out the visible content material. However, present evaluations persistently adhere to the method of inferring on given benchmarks and calculating scores for LVLMs, overlooking the potential of knowledge leakage throughout multi-modal coaching. This oversight can result in unfair comparisons and misjudgments.
The researchers from the College of Science and Expertise of China, The Chinese language College of Hong Kong, and Shanghai AI Laboratory current MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously chosen by people. MMStar benchmarks six core capabilities and 18 detailed axes, aiming to judge LVLMs’ multi-modal capacities with rigorously balanced and purified samples. These samples are first roughly chosen from present benchmarks with an automatic pipeline; human evaluate is then concerned to make sure every curated pattern reveals visible dependency, minimal knowledge leakage, and requires superior multi-modal capabilities. Furthermore, two metrics are developed to measure knowledge leakage and precise efficiency acquire in multi-modal coaching.
MMStar is defined in three sections:
- Knowledge Curation Course of: Standards for knowledge curation: The analysis samples for establishing the MMStar benchmark ought to meet three basic standards: 1) Visible dependency. The collected samples will be appropriately answered solely primarily based on understanding the visible content material; 2) Minimal knowledge leakage. The collected samples ought to reduce the danger of unintentional inclusion in LLMs’ coaching corpus or be successfully reworked from uni-modal to multi-modal codecs to stop LLMs from “recalling” the proper solutions; 3) Requiring superior multi-modal capabilities for decision.
Knowledge filter: For his or her pattern assortment, they first selected two benchmarks targeted on pure photos and 4 centered on scientific and technical information. Then, they developed an automatic pipeline to preliminarily filter out samples that didn’t meet the primary two standards. Particularly, they make use of two closed-source LLMs and 6 open-source LLMs.
Guide evaluate: After the coarse filtering with LLM inspectors, they additional make use of three specialists to conduct the handbook evaluate course of to make sure: 1) every pattern’s reply must be primarily based on the understanding of visible content material; 2) chosen samples ought to cowl a complete vary of functionality evaluation dimensions; 3) most samples ought to require LVLMs to own superior multi-modal skills for decision.
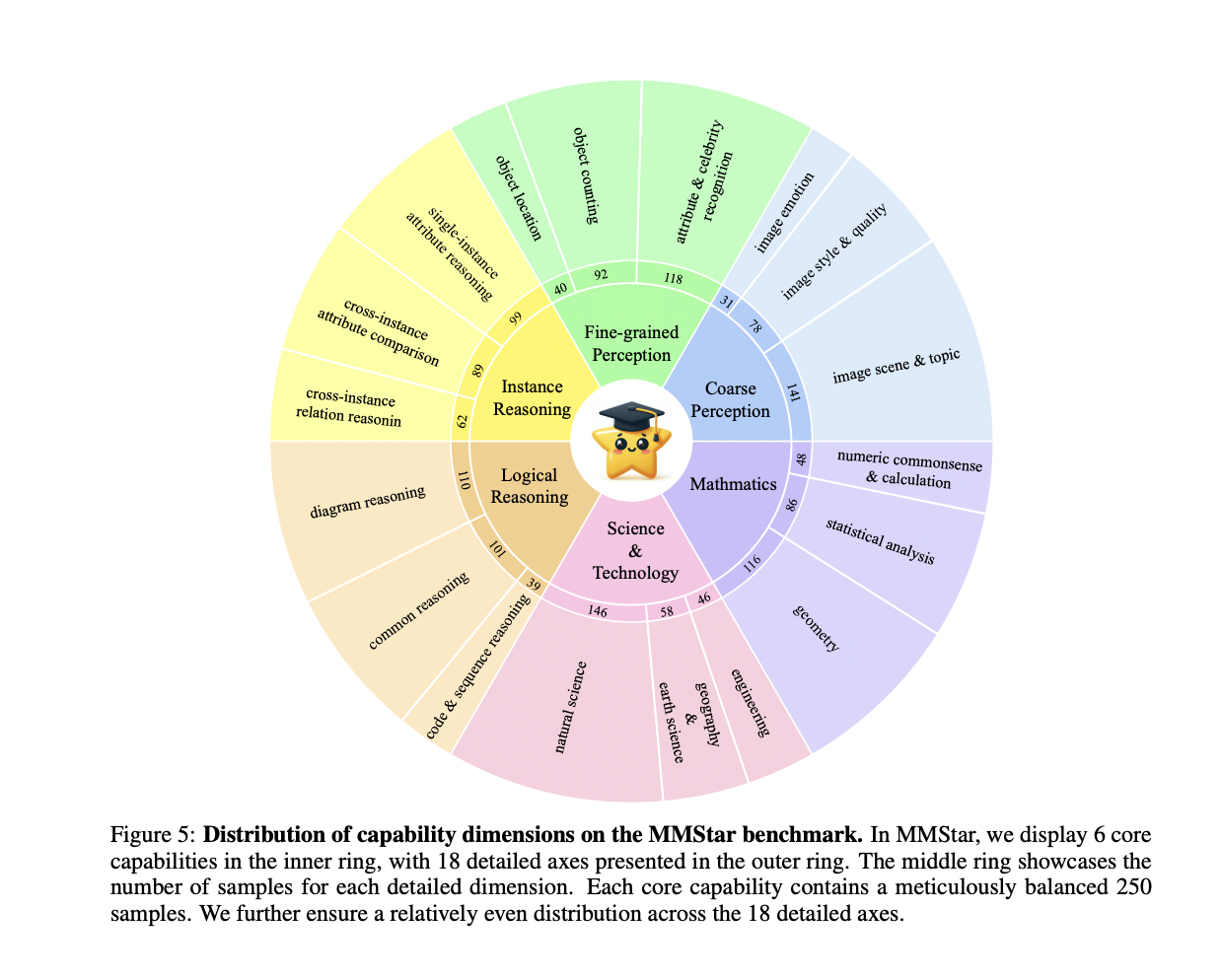
- Core Capabilities: They choose and consolidate the size used for assessing LVLMs’ multi-modal capabilities in present benchmarks and establish six core functionality dimensions and eighteen detailed axes.
- Multi-modal Achieve/Leakage: They proposed two distinctive metrics to evaluate the diploma of information leakage and precise efficiency acquire from the multi-modal coaching course of.
They evaluated two closed-source and 14 open-source LVLMs on MMStar, with a high-resolution setting that may obtain the perfect common rating of 57.1% amongst all LVLMs. Rising the decision and variety of picture tokens can enhance the common rating from 46.1% to 57.1% for GPT4V. Among the many open-source LVLMs, InternLMXcomposer2 achieves a formidable rating of 55.4%. LLaVA-Subsequent even surpasses GPT4V and GeminiPro-Imaginative and prescient within the arithmetic (MA) core functionality.
In conclusion, the researchers delved deeper into the analysis work for LVLMs, and They discovered two key points: 1) visible content material is pointless for a lot of samples, and a couple of) unintentional knowledge leakage exists in LLM and LVLM coaching. Researchers developed an elite vision-dependent multi-modal benchmark named MMStar and proposed two metrics to measure the info leakage and precise efficiency acquire in LVLMs’ multi-modal coaching. MMStar undergoes the handbook evaluate of every pattern, overlaying six core capabilities and 18 detailed axes for an in-depth analysis of LVLMs’ multimodal capabilities. Evaluating 16 various LVLMs on MMStar, even the perfect mannequin scores underneath 60 on common.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 39k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.

Noise Newly Launched Buds N1 in-Ear Truly Wireless Earbuds with Chrome Finish, 40H of Playtime, Quad Mic with ENC, Ultra Low Latency(up to 40 ms), Instacharge(10 min=120 min), BT v5.3(Carbon Black)
₹1,299.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Phoenix Ultra Luxury Stainless Steel, Bluetooth Calling Smartwatch, AI Voice Assistant, Metal Body with 120+ Sports Modes, SpO2, Heart Rate Monitoring (Gold)
₹1,749.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oneplus Bullets Z2 Bluetooth Wireless in Ear Earphones with Mic, Bombastic Bass - 12.4 mm Drivers, 10 Mins Charge - 20 Hrs Music, 30 Hrs Battery Life, IP55 Dust and Water Resistant (Magico Black)
₹1,499.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Nirvana Ion TWS Earbuds with 120 HRS Playback(24hrs/Charge), Crystal Bionic Sound with Dual EQ Modes, Quad Mics ENx™ Technology, Low Latency(60ms), in Ear Detection(Charcoal Black)
₹1,698.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fastrack Limitless Glide Advanced UltraVU HD Display|BT Calling|ATS Chipset|100+ Sports Modes & Watchfaces|Calculator|Voice Assistant|in-Built Games|24 * 7 HRM|IP68 Smartwatch
₹1,399.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹667.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L POR-1403 Fast Charging 3A Type-C Cable 1.2 Meter with Charge & Sync Function for All Type-C Devices (White)
₹119.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹699.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹179.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
WD 5TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0050BBK-WESN
$124.99 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Graphics Card GPU Brace Support, Video Card Sag Holder Bracket, GPU Stand, L
$9.99 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen™ 7 5700X 8-Core, 16-Thread Unlocked Desktop Processor
$166.99 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Maxone 500GB Ultra Slim Portable External Hard Drive HDD USB 3.0 for PC, Mac, Laptop, PS4, Xbox one - Charcoal Grey
$33.66 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)