
It’s no secret that supervised machine studying fashions have to be skilled on high-quality labeled datasets. Nevertheless, amassing sufficient high-quality labeled information could be a vital problem, particularly in conditions the place privateness and information availability are main considerations. Thankfully, this downside might be mitigated with artificial information. Artificial information is information that’s artificially generated somewhat than collected from real-world occasions. This information can both increase actual information or can be utilized instead of actual information. It may be created in a number of methods together with by using statistics, information augmentation/computer-generated imagery (CGI), or generative AI relying on the use case. On this publish, we’ll go over:
- The Worth of Artificial Knowledge
- Artificial Knowledge for Edge Circumstances
- The right way to Generate Artificial Knowledge
https://youtu.be/PIzDYbATawY?si=Eb9M8aAfgVBym4Ih
Issues with actual information have led to many use instances for artificial information, which you’ll take a look at beneath.
Privateness points

Picture by Google Analysis
Healthcare information is extensively recognized to have privateness restrictions. For instance, whereas incorporating digital well being information (EHR) into machine studying functions may improve affected person outcomes, doing so whereas adhering to affected person privateness rules like HIPAA is troublesome. Even strategies to anonymize information aren’t excellent. In response, researchers at Google got here up with EHR-Protected which is a framework for producing reasonable and privacy-preserving artificial EHR.
Security Points
Amassing actual information might be harmful. One of many core issues with robotic functions like self-driving vehicles is that they’re bodily functions of machine studying. An unsafe mannequin can’t be deployed in the true world and causes a crash on account of an absence of related information. Augmenting a dataset with artificial information will help fashions keep away from these issues.
Actual information assortment and labeling are sometimes not scalable
Annotating medical photos is essential for coaching machine studying fashions. Nevertheless, every picture must be labeled by professional clinicians, which is a time-consuming and costly course of that’s typically topic to strict privateness rules. Artificial information can handle this by producing giant volumes of labeled photos with out requiring in depth human annotation or compromising affected person privateness.
Guide labeling of actual information can typically be very exhausting if not not possible
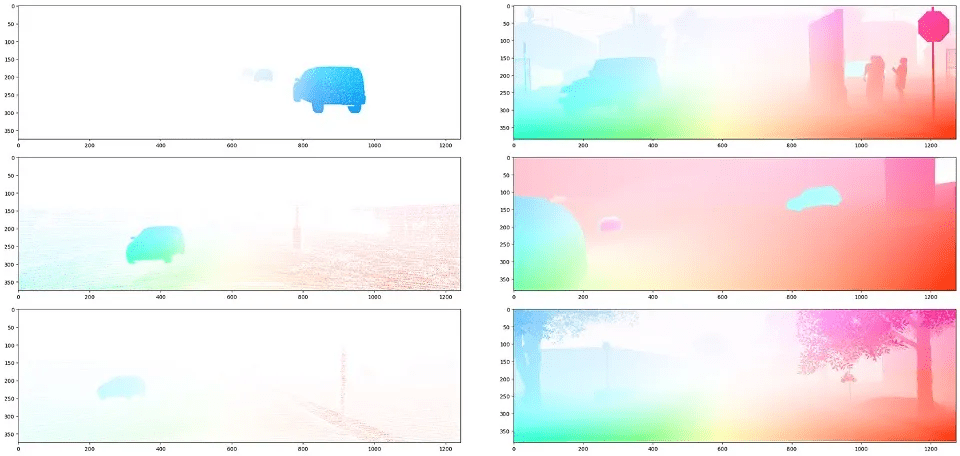
Optical move labels of the sparse real-world information KITTI (left) and the artificial information from Parallel Area (proper). The colour signifies the course and magnitude of move. Picture by creator.
In self-driving, estimating per-pixel movement between video frames, often known as optical move, is difficult with real-world information. Actual information labeling can solely be carried out utilizing LiDAR data to estimate object movement, whether or not dynamic or static, from the autonomous automobile’s trajectory. As a result of LiDAR scans are sparse, the only a few public optical move datasets are additionally sparse. That is one cause why some optical move artificial information has been proven to significantly enhance efficiency on optical move duties.
A typical use case of artificial information is to cope with an absence of uncommon lessons and edge instances in actual datasets. Earlier than producing artificial information for this use case, please take a look at the guidelines beneath to contemplate what must be generated and the way a lot of it’s wanted.
Establish your edge instances and uncommon lessons
It is very important perceive what edge instances are contained in a dataset. This may very well be uncommon ailments in medical photos or common animals and jaywalkers in self-driving. It is usually essential to contemplate what edge instances are NOT in a dataset. If a mannequin must determine an edge case not current within the dataset, further information assortment or artificial information era is perhaps mandatory.
Confirm the artificial information is consultant of the real-world
Artificial information ought to signify real-world eventualities with minimal area gaps that are variations between two distinct datasets (e.g., actual and artificial information). This may be carried out by guide inspection or through the use of a separate mannequin skilled on actual information.
Make potential artificial efficiency enhancements quantifiable
A purpose of supervised studying is to construct a mannequin that performs nicely on new information. For this reason there are mannequin validation procedures like practice check break up. When augmenting an actual dataset with artificial information, information may have to be balanced based mostly on uncommon lessons. For instance, in self-driving functions, a machine studying practitioner is perhaps curious about utilizing artificial information to deal with particular edge instances like jaywalkers. The unique practice check break up could not have been break up by the variety of jaywalkers. On this case, it’d make sense to maneuver plenty of the prevailing jaywalker samples over to the check set to make sure that enchancment by artificial information is measurable.
Guarantee all your artificial information isn’t just uncommon lessons
A machine studying mannequin mustn’t be taught that artificial information is usually uncommon lessons and edge instances. Additionally, when extra uncommon lessons and edge instances are found, extra artificial information may have to be generated to account for this situation.
A serious power of artificial information is that extra can all the time be generated. It additionally comes with the good thing about already being labeled. There are various methods to generate artificial information and which one you select is determined by your use case.
Statistical strategies
A typical statistical methodology is to generate new information based mostly on the distribution and variability of the unique information set. Statistical strategies work greatest when the dataset is comparatively easy and the relationships between variables are nicely understood and might be outlined mathematically. For instance, if actual information has a standard distribution like human heights, artificial information might be created utilizing the identical imply and commonplace deviation of the unique dataset.
Knowledge augmentation/CGI
A typical technique to extend the variety and quantity of coaching information is by modifying current information to create artificial information. Knowledge augmentation is extensively utilized in picture processing. This may imply flipping photos, cropping them, or adjusting brightness. Simply guarantee that the info augmentation technique is smart for the challenge of curiosity. For instance, for self-driving functions, rotating a picture by 180 levels in order that the highway is on the prime of the picture and the sky on the backside doesn’t make sense.
https://youtu.be/296k6OHErfM?si=H56aB5hlpEIBtp7c
Caption: Multiformer inference on an city scene from the artificial SHIFT dataset.
Fairly than modifying current information for self-driving functions, CGI can be utilized to exactly generate all kinds of photos or movies which may not be simply obtainable within the real-world. This could embrace uncommon or harmful eventualities, particular lighting circumstances, or varieties of autos. A few the drawbacks of this strategy are that creating high-quality CGI requires vital computational sources. specialised software program, and a talented staff.
Generative AI
A generally used generative mannequin to create artificial information is Generative Adversarial Networks or GANs for brief. GANs encompass two networks, a generator, and a discriminator, which are skilled concurrently. The generator creates new examples, and the discriminator makes an attempt to distinguish between actual and generated examples. The fashions be taught collectively, with the generator bettering its capacity to create reasonable information, and the discriminator changing into extra expert at detecting artificial information. If you need to attempt implementing a GAN with PyTorch, take a look at this TDS weblog publish.
These strategies work nicely for complicated datasets and may generate very reasonable, high-quality information, Nevertheless, because the picture above reveals, it’s not all the time straightforward to manage particular attributes like the colour, textual content, or measurement of generated objects.
If a challenge doesn’t have sufficient high-quality and various actual information, artificial information is perhaps an choice. In spite of everything, extra artificial information can all the time be generated. It is a main distinction between actual and artificial information as artificial information is way simpler to enhance! You probably have any questions or ideas on this weblog publish, be at liberty to achieve out within the feedback beneath or by Twitter.
Michael Galarnyk is a Knowledge Science Skilled, and works in Product Advertising Content material Lead at Parallel Area.

boAt Newly Launched Airdopes 121 V2 Plus TWS in Ear Earbuds with 50 Hrs Playtime,Quad Mics W/Enx Tech,ASAP Charging, Beast Mode(50Ms Low Latency),Btv5.3 & Ipx4(Active Black)
₹1,399.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Ninja Call Pro Smart Watch Dual Chip Bluetooth Calling, 1.69" Display, AI Voice Assistance with 100 Sports Modes, with SpO2 & Heart Rate Monitoring
₹1,099.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TECNO Spark GO 2024 (Mystery White,8GB* RAM, 128GB ROM)| Segment First 90Hz Dot-in Display with Dynamic Port & Dual Speakers with DTS| 5000mAh| 10W Type-C| Fingerprint Sensor| Octa-Core Processor
₹7,299.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth in Ear Earphones with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.0(Cosmic Grey)
₹999.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TECNO POP 8 (Gravity Black,(8GB*+64GB)| 90Hz Punch Hole Display with Dynamic Port & Dual Speakers with DTS| 5000mAh Battery |10W Type-C| Side Fingerprint Sensor| Octa-Core Processor
₹6,599.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹299.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 25 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L POR-1403 Fast Charging 3A Type-C Cable 1.2 Meter with Charge & Sync Function for All Type-C Devices (White)
₹119.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP 680 Original Ink Advantage Cartridge (Black)
₹886.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 1TB Portable External Hard Drive USB 3.0, Black - HDTB510XK3AA
$49.99 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SanDisk 1TB Extreme Portable SSD - Up to 1050MB/s, USB-C, USB 3.2 Gen 2, IP65 Water and Dust Resistance, Updated Firmware - External Solid State Drive - SDSSDE61-1T00-G25
$99.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Western Digital 4TB My Passport Portable External Hard Drive with backup software and password protection, Black - WDBPKJ0040BBK-WESN
$90.90 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)