

Debugging efficiency points in databases is difficult, and there’s a want for a device that may present helpful and in-context troubleshooting suggestions. Massive Language Fashions (LLMs) like ChatGPT can reply many questions however typically present obscure or generic suggestions for database efficiency queries.
Whereas LLMs are educated on huge quantities of web information, their generic suggestions lack context and the multi-modal evaluation required for debugging. Retrieval Augmented Era (RAG) is proposed to boost prompts with related data, however making use of LLM-generated suggestions in actual databases raises considerations about belief, impression, suggestions, and threat. Thus, What are the important constructing blocks wanted for safely deploying LLMs in manufacturing for correct, verifiable, actionable, and helpful suggestions? is an open and ambiguous query.
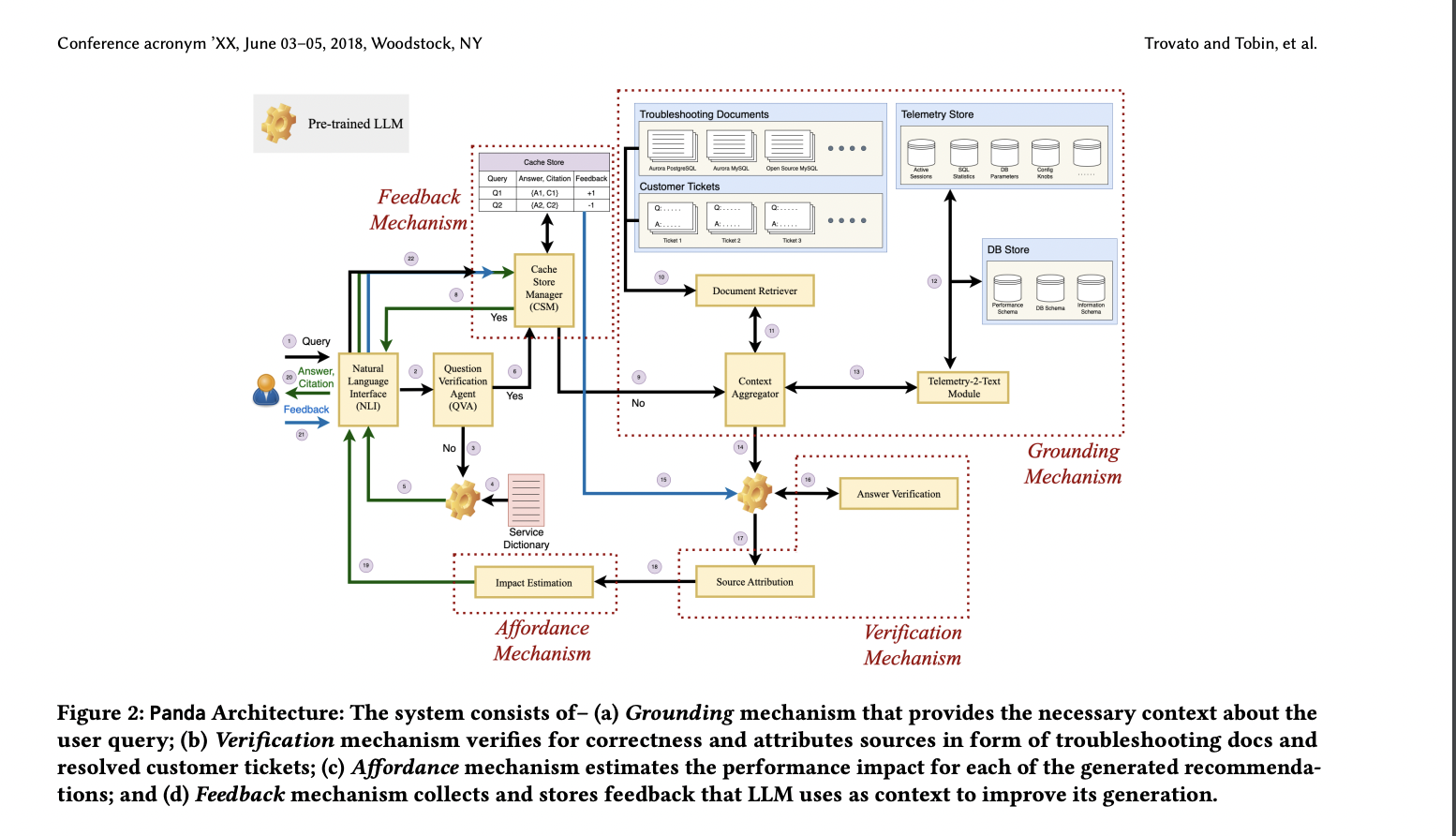
Researchers from AWS AI Labs and Amazon Internet Providers have proposed Panda, which goals to offer context grounding to pre-trained LLMs for producing extra helpful and in-context troubleshooting suggestions for database efficiency debugging. Panda has a number of key parts: grounding, verification, affordability, and suggestions.
The Panda system contains 5 parts: Query Verification Agent filters queries for relevance, the Grounding Mechanism extracts world and native contexts, the Verification Mechanism ensures reply correctness, the Suggestions Mechanism incorporates consumer suggestions, and the Affordance Mechanism estimates the impression of really helpful fixes. Panda makes use of Retrieval Augmented Era for contextual question dealing with, using embeddings for similarity searches. Telemetry metrics and troubleshooting docs present multi-modal information for higher understanding and extra correct suggestions, addressing the contextual challenges of database efficiency debugging.
In a small experimental research evaluating Panda, using GPT-3.5, with GPT-4 for real-world problematic database workloads, Panda demonstrated superior reliability and usefulness in response to Database Engineers’ evaluations. Intermediate and Superior DBEs discovered Panda’s solutions extra reliable and helpful attributable to supply citations and correctness grounded in telemetry and troubleshooting paperwork. Newbie DBEs additionally favored Panda however highlighted considerations about specificity. Statistical evaluation utilizing a two-sample T-Take a look at confirmed the statistical superiority of Panda over GPT-4.
In conclusion, the researchers introduce Panda, an progressive system for autonomous database debugging utilizing NL brokers. Panda excels in figuring out and rejecting irrelevant queries, establishing significant multi-modal contexts, estimating impression, providing citations, and studying from suggestions. It emphasizes the importance of addressing open analysis questions encountered throughout its improvement and invitations collaboration from the database and methods communities to reshape the database debugging course of collectively. The system goals to redefine and improve the general method to debugging databases.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

Redmi 13C (Starshine Green, 4GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹8,999.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Lumos Stainless Steel Luxury Smart Watch with 1.91” Large Display, Bluetooth Calling, Voice Assistant, 100+ Sports Modes
₹1,399.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
POCO C51 (Power Black, 6GB RAM, 128GB Storage)
₹5,999.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Phoenix Ultra Luxury Stainless Steel, Bluetooth Calling Smartwatch, AI Voice Assistant, Metal Body with 120+ Sports Modes, SpO2, Heart Rate Monitoring (Gold)
₹1,799.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toreto-Htech Tor-566 30W Mobile Charger Compatible with Honor 90, USB Type A, White
₹699.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹289.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 20 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toysbuddy Re-Writable LCD Writing Tablet Pad with Screen 21.5cm (8.5Inch) for Drawing, Playing, Handwriting Best Birthday Gifts for Adults & Kids Girls Boys, Multicolor
₹97.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹269.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 60W / 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, PD Technology, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹99.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link WiFi 6 AX3000 PCIe WiFi Card (Archer TX3000E), Up to 2400Mbps, Bluetooth 5.2, 802.11AX Dual Band Wireless Adapter with MU-MIMO,OFDMA,Ultra-Low Latency, Supports Windows 11, 10 (64bit) only
$37.48 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 5 5600X 6-core, 12-Thread Unlocked Desktop Processor with Wraith Stealth Cooler
$156.00 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
WD 5TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0050BBK-WESN
$119.99 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell USB DVD Drive-DW316 , Black
$34.49 (as of January 14, 2024 07:25 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)