

We’re excited to announce that the newest launch of sparklyr on CRAN introduces help for Databricks Join. R customers now have seamless entry to Databricks clusters and Unity Catalog from distant RStudio Desktop, Posit Workbench, or any energetic R terminal or course of. This replace additionally opens the door for any R consumer to construct information functions with Databricks utilizing only a few strains of code.
How sparklyr integrates with Python Databricks Join
This launch introduces a brand new backend for sparklyr by way of the pysparklyr companion package deal. pysparklyr offers a bridge for sparklyr to work together with the Python Databricks Join API. It achieves this by utilizing the reticulate package deal to work together with Python from R.

Architecting the brand new sparklyr backend this manner makes it simpler to ship Databricks Join performance to R customers by merely wrapping these which might be launched in Python. At present, Databricks Join totally helps the Apache Spark DataFrame API, and you’ll reference the sparklyr cheat sheet to see which extra capabilities can be found.
Getting began with sparklyr and Databricks Join
To rise up and operating, first set up the sparklyr and pysparklyr packages from CRAN in your R session.
set up.packages("sparklyr")
set up.packages("pysparklyr")Now a connection will be established between your R session and Databricks clusters by specifying your Workspace URL (aka host), entry token, and cluster ID. Whilst you can cross your credentials as arguments on to sparklyr::spark_connect(), we advocate storing them as setting variables for added safety. As well as, when utilizing sparklyr to make a connection to Databricks, pysparklyr will determine and assist set up any dependencies right into a Python digital setting for you.
# This instance assumes a primary time reference to
# DATABRICKS_HOST and DATABRICKS_TOKEN set as setting variables
library(sparklyr)
sc <- spark_connect(
cluster_id = "1026-175310-7cpsh3g8",
technique = "databricks_connect"
)
#> ! Retrieving model from cluster '1026-175310-7cpsh3g8'
#> Cluster model: '14.1'
#> ! No viable Python Atmosphere was recognized for Databricks Join model 14.1
#> Do you want to set up Databricks Join model 14.1?
#>
#> 1: Sure
#> 2: No
#> 3: Cancel
#>
#> Choice: 1 Extra particulars and tips about the preliminary setup will be discovered on the official sparklyr web page.
Accessing information in Unity Catalog
Efficiently connecting with sparklyr will populate the Connections pane in RStudio with information from Unity Catalog, making it easy to browse and entry information managed in Databricks.
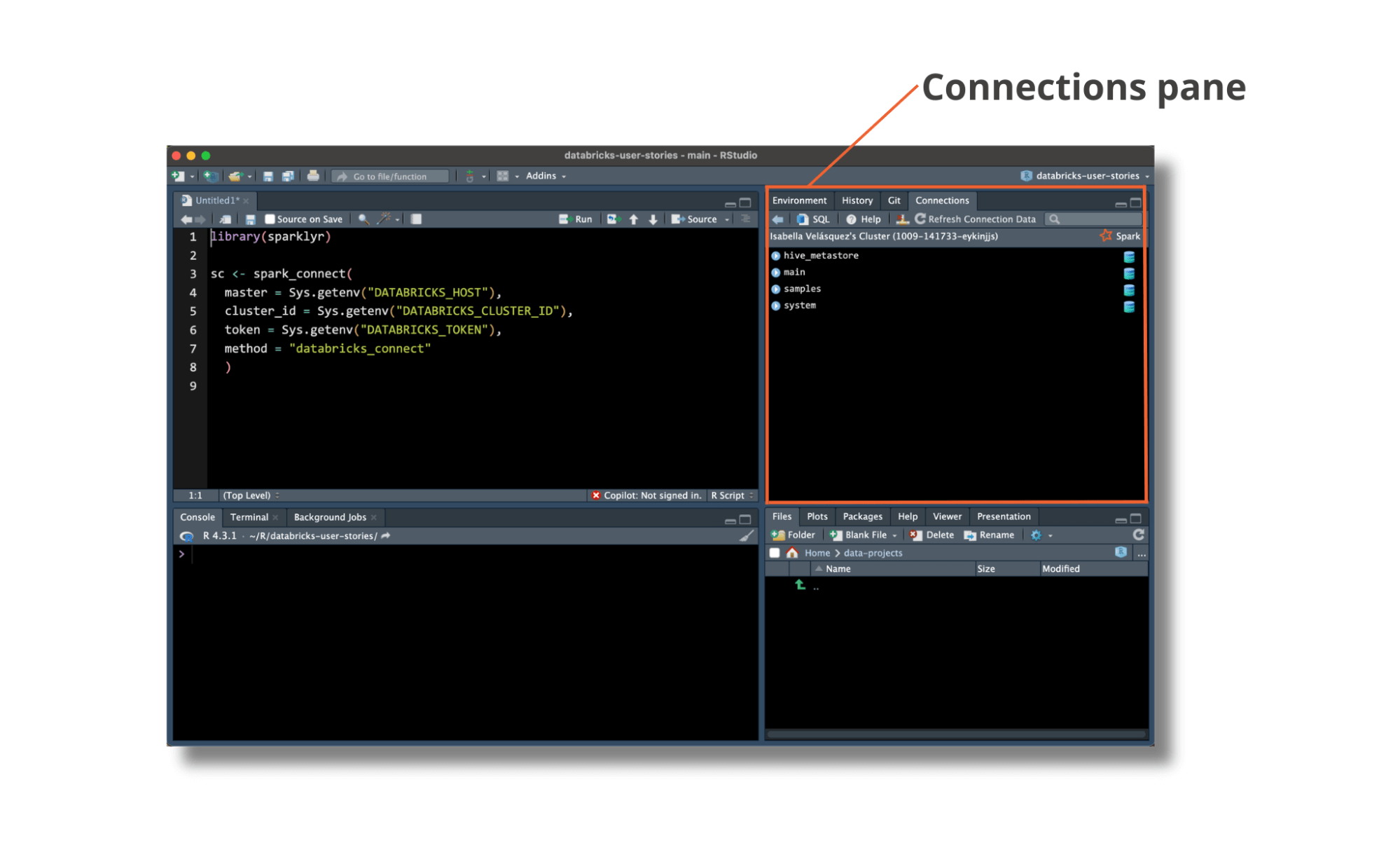
Unity Catalog is the overarching governance resolution for information and AI on Databricks. Information tables ruled in Unity Catalog exist in a three-level namespace of catalog, schema, then desk. By updating the sparklyr backend to make use of Databricks Join, R customers can now learn and write information expressing the catalog.schema.desk hierarchy:
library(dplyr)
library(dbplyr)
# Learn samples.nyctaxi.journeys desk with catalog.schema.desk heirarchy
journeys <- tbl(sc, in_catalog("samples", "nyctaxi", "journeys"))
journeys
#> # Supply: spark<journeys> [?? x 6]
#> tpep_pickup_datetime tpep_dropoff_datetime trip_distance fare_amount
#> <dttm> <dttm> <dbl> <dbl>
#> 1 2016-02-14 10:52:13 2016-02-14 11:16:04 4.94 19
#> 2 2016-02-04 12:44:19 2016-02-04 12:46:00 0.28 3.5
#> 3 2016-02-17 11:13:57 2016-02-17 11:17:55 0.7 5
#> 4 2016-02-18 04:36:07 2016-02-18 04:41:45 0.8 6
#> 5 2016-02-22 08:14:41 2016-02-22 08:31:52 4.51 17
#> 6 2016-02-05 00:45:02 2016-02-05 00:50:26 1.8 7
#> 7 2016-02-15 09:03:28 2016-02-15 09:18:45 2.58 12
#> 8 2016-02-25 13:09:26 2016-02-25 13:24:50 1.4 11
#> 9 2016-02-13 10:28:18 2016-02-13 10:36:36 1.21 7.5
#> 10 2016-02-13 18:03:48 2016-02-13 18:10:24 0.6 6
#> # ℹ extra rows
#> # ℹ 2 extra variables: pickup_zip <int>, dropoff_zip <int>Interactive growth and debugging
To make interactive work with Databricks easy and acquainted, sparklyr has lengthy supported dplyr syntax for reworking and aggregating information. The latest model with Databricks Join is not any completely different:
# Get whole journeys and common journey distance, NYC Taxi dataset
journeys |>
group_by(pickup_zip) |>
summarise(
rely = n(),
avg_distance = imply(trip_distance, na.rm = TRUE)
)
#> # Supply: spark<?> [?? x 3]
#> pickup_zip rely avg_distance
#> <int> <dbl> <dbl>
#> 1 10032 15 4.49
#> 2 10013 273 2.98
#> 3 10022 519 2.00
#> 4 10162 414 2.19
#> 5 10018 1012 2.60
#> 6 11106 39 2.03
#> 7 10011 1129 2.29
#> 8 11103 16 2.75
#> 9 11237 15 3.31
#>10 11422 429 15.5
#> # ℹ extra rows
#> # ℹ Use `print(n = ...)` to see extra rowsAs well as, when it’s essential debug capabilities or scripts that use sparklyr and Databricks Join, the browser() perform in RStudio works superbly – even when working with huge datasets.
Databricks-powered functions
Creating information functions like Shiny on prime of a Databricks backend has by no means been simpler. Databricks Join is light-weight, permitting you to construct functions that learn, remodel, and write information at scale with no need to deploy straight onto a Databricks cluster.
When working with Shiny in R, the connection strategies are an identical to these used above for growth work. The identical goes for working with Shiny for Python; simply comply with the documentation for utilizing Databricks Join with PySpark. That will help you get began we now have examples of knowledge apps that use Shiny in R, and different frameworks like plotly in Python.
Further sources
To be taught extra, please go to the official sparklyr and Databricks Join documentation, together with extra details about which Apache Spark APIs are presently supported. Additionally, please take a look at our webinar with Posit the place we display all of those capabilities, together with how one can deploy Shiny apps that use Databricks Join on Posit Join.

OnePlus Bullets Z2 Bluetooth Wireless in Ear Earphones with Mic, Bombastic Bass, 10 Mins Charge - 20 Hrs Music, 30 Hrs Battery Life (Acoustic Red)
₹1,499.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme narzo 60X 5G(Stellar Green,6GB,128GB Storage ) Up to 2TB External Memory | 50 MP AI Primary Camera | Segments only 33W Supervooc Charge
₹14,499.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive, Metal, Silver
₹377.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple 20W USB-C Power Adapter (for iPhone, iPad & AirPods)
₹1,699.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 Lite 5G (Pastel Lime, 8GB RAM, 256GB Storage)
₹21,999.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Mport 31C USB C Hub (4-in-1), Type C Multiport Adapter with 1 x USB 3.0 & 3 x USB 2.0 Ports, up to 5 Gbps High Speed Data Transfer for Laptop, MacBook, PC (Grey)
₹315.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Callas Multipurpose Foldable Laptop Table with Cup Holder | Drawer | Mac Holder | Study Table, Breakfast Table, Foldable and Portable/Ergonomic & Rounded Edges/Non-Slip Legs (WA-27-Black) | Metal
₹499.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Duracell USB Type C, 3A Braided Sync & Fast Charging Cable, 3.9 Ft (1.2M),QC 2.0/3.0 Ultra Fast Charging,Compatible with Samsung,One Plus & all C type devices,Seamless Data Transmission,Series 3-Black
₹379.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics Zeb-Power Wired USB Mouse, 3-Button, 1200 DPI Optical Sensor, Plug & Play, for Windows/Mac
₹99.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 60W / 3A Fast Charging 1.5m Braided Micro USB Cable for Smartphones, Tablets, Laptops & other Micro USB devices, 480Mbps Data Sync, Quick Charge 3.0 (RCM15, Black)
₹149.00 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
External CD/DVD Drive for Laptop USB 3.0 CD/DVD Player Portable CD DVD +/-RW Burner CD ROM Reader Rewriter Writer Disk Duplicator Drive Compatible with Laptop Desktop PC Windows Apple Mac Pro MacBook
$19.98 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG SSD T7 Portable External Solid State Drive 1TB, Up to USB 3.2 Gen 2, Reliable Storage for Gaming, Students, Professionals, MU-PC1T0R/AM, Red
$79.18 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 7 5800X 8-core, 16-Thread Unlocked Desktop Processor
$212.05 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$64.99 (as of December 14, 2023 23:08 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)