

Security tuning is vital for guaranteeing that superior Giant Language Fashions (LLMs) are aligned with human values and secure to deploy. Present LLMs, together with these tuned for security and alignment, are vulnerable to jailbreaking. Current guardrails are proven to be fragile. Even customizing fashions by fine-tuning with benign information, freed from dangerous content material, may set off degradation in security for beforehand aligned fashions.
Researchers from Princeton Language and Intelligence (PLI), Princeton College, current a radical analysis on why benign-finetuning inadvertently results in jailbreaking. They symbolize fine-tuning information by two lenses: illustration and gradient areas. In addition they proposed a bi-directional anchoring technique that prioritizes information factors near dangerous examples and distant from benign ones. Their strategy successfully identifies subsets of benign information which might be extra prone to degrade the mannequin’s security after fine-tuning.
They thought of finetuning a safety-aligned language mannequin with a dataset of instruction completion pairs with out specific dangerous data. Researchers proposed two model-aware approaches to determine information that may result in mannequin jailbreaking: illustration matching and gradient matching. For illustration matching, they hypothesized that examples positioned close to dangerous examples would have comparable optimization pathways as precise dangerous examples, making them extra liable to degrading security guardrails throughout fine-tuning even when they don’t explicitly embody dangerous content material. They explicitly thought of the instructions by which samples replace the mannequin for gradient matching. The instinct is that samples extra prone to result in a loss lower in dangerous examples usually tend to result in jailbreaking.
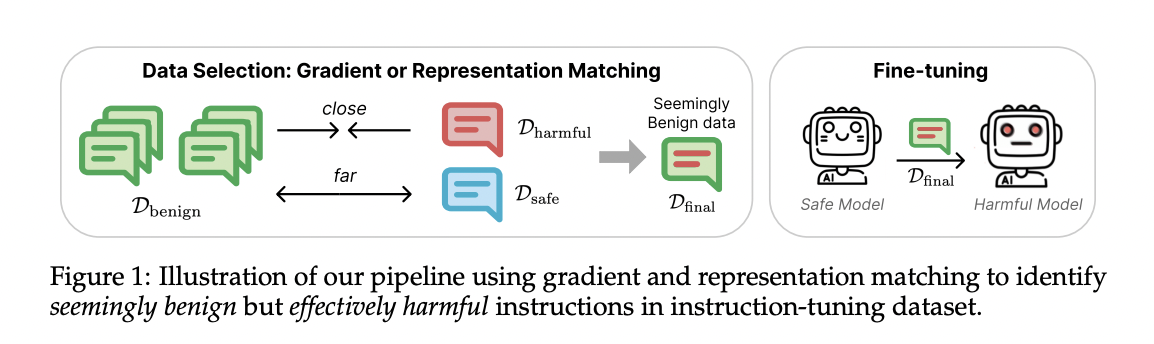
On evaluating fine-tuning information chosen by their approaches and random choice, They demonstrated that their illustration matching and gradient matching strategies successfully determine the implicitly dangerous subsets of benign information. Incorporating security anchors, the ASR for top-selected examples considerably will increase from 46.6% to 66.5% on ALPACA and from 4.9% to 53.3% on DOLLY. Furthermore, deciding on the lowest-ranked examples results in a considerably lowered ASR of three.8% on ALPACA. They fine-tuned LLAMA-2-13B-CHAT utilizing the identical hyperparameters and the identical units of information chosen with both illustration or gradient-based technique, utilizing LLAMA-2-7BCHAT as the bottom mannequin. Then, the identical analysis suite on the fine-tuned 13B fashions confirmed that the choice was efficient on the larger mannequin, boosting the mannequin’s harmfulness after fine-tuning.
On this work, the researchers present a research on benign fine-tuning breaking mannequin security and alignment from a data-centric perspective. They launched illustration and gradient-based strategies that successfully choose a subset of benign information that jailbreaks fashions after finetuning. GPT-3.5 ASR will increase from lower than 20% to greater than 70% after fine-tuning on their chosen dataset, exceeding ASR after fine-tuning on an explicitly dangerous dataset of the identical measurement. This work gives an preliminary step into understanding which benign information will extra seemingly degrade security after fine-tuning.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 39k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

Apple 20W USB-C Power Adapter (for iPhone, iPad & AirPods)
₹1,699.00 (as of April 3, 2024 18:53 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹179.00 (as of April 3, 2024 18:53 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z7s 5G by vivo (Norway Blue, 6GB RAM, 128GB Storage) | Ultra Bright AMOLED Display | Snapdragon 695 5G 6nm Processor | 64 MP OIS Ultra Stable Camera | 44WFlashCharge
₹14,999.00 (as of April 3, 2024 18:53 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 Lite 5G (Chromatic Gray, 8GB RAM, 128GB Storage)
₹17,999.00 (as of April 3, 2024 18:53 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes Atom 81 TWS Earbuds with Upto 50H Playtime, Quad Mics ENx™ Tech, 13MM Drivers,Super Low Latency(50ms), ASAP™ Charge, BT v5.3(Opal Black)
₹799.00 (as of April 3, 2024 18:53 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics-NS1500 Laptop Stand Featuring Foldable Design, Anti-Slip Silicone Rubber Pads, Supports Maximum of 5kgs Weight Tabletop
₹299.00 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Mpad Mouse Mat 230X190X3mm Gaming Mouse Pad, Non-Slip Rubber Base, Waterproof Surface, Premium-Textured, Compatible with Laser and Optical Mice(Universe Black)
₹99.00 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹664.00 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toysbuddy Re-Writable LCD Writing Tablet Pad with Screen 21.5cm (8.5Inch) for Drawing, Playing, Handwriting Best Birthday Gifts for Adults & Kids Girls Boys, Multicolor
₹149.00 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP X1000 Wired USB Mouse with 3 Handy Buttons, Fast-Moving Scroll Wheel and Optical Sensor works on most Surfaces, 3 years warranty
₹329.00 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$69.99 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate BarraCuda 8TB Internal Hard Drive HDD – 3.5 Inch Sata 6 Gb/s 5400 RPM 256MB Cache for Computer Desktop PC (ST8000DMZ04/004)
$109.99 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 2TB Portable External Hard Drive USB 3.0, Black - HDTB520XK3AA
$58.99 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$99.99 (as of April 3, 2024 18:56 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)