

Language fashions (LMs) are designed to mirror a broad vary of voices, resulting in outputs that don’t completely match any single perspective. To keep away from generic responses, one can use LLMs via supervised fine-tuning (SFT) or reinforcement studying with human suggestions (RLHF). Nevertheless, these strategies want large datasets, making them impractical for brand spanking new and particular duties. Furthermore, there may be usually a mismatch between the common type skilled into an LLM via instruction and choice tuning wanted for particular purposes. This mismatch ends in LLM outputs feeling generic and missing a particular voice.
A number of strategies have been developed to deal with these challenges. One of many approaches includes LLMs and Choice Finetuning through which LLMs are skilled on large datasets to carry out nicely with cautious prompting. Nevertheless, designing prompts will be troublesome and delicate to variations, so it’s usually essential to finetune these fashions on giant datasets and use RLHF. One other technique is self-improvement, the place iterative sampling is used to boost LLMs. For instance, strategies like STaR are supervised by verifying the correctness of its outputs. Lastly, On-line Imitation Studying can enhance a coverage past the demonstrator’s efficiency. Nevertheless, these approaches must be taught a reward perform and aren’t relevant to LLMs.
Researchers from Standford College have launched Demonstration ITerated Job Optimization (DITTO), a technique that aligns language mannequin outputs immediately with the person’s demonstrated behaviors. It’s derived utilizing concepts from on-line imitation studying and may generate on-line comparability information at a low price. To generate these information, DITTO prioritizes customers’ demonstrations over output from the LLM and its intermediate checkpoints. Furthermore, the win charges of this methodology outperform few-shot prompting, supervised fine-tuning, and different self-play strategies by a median of 19% factors. Additionally, it supplies a novel solution to successfully customise LLMs utilizing direct suggestions from demonstrations.
DITTO is able to studying fine-grained type and process alignment throughout domains like information articles, emails, and weblog posts. It’s an iterative course of that accommodates three elements: (a) On the set of knowledgeable demonstrations, supervised fine-tuning is executed for a restricted variety of gradient steps; (b) a New dataset is constructed throughout the coaching course of by sampling completions for every demonstration and including it to the rating over insurance policies, and (c) RLHF is used for updating the coverage, notably utilizing batches sampled via the beforehand talked about course of.
The outcomes of DITTO is evaluated with GPT-4 eval and averaged throughout all authors, the place it outperforms all baselines with a median win charge of 77.09% throughout CMCC (71.67%) and CCAT50 (82.50%). It supplies a median enhance of 11.7% win charge as in comparison with SFT which serves as a robust baseline (56.78% on CMCC, 73.89% on CCAT). Additional, in person examine outcomes, DITTO outperforms baseline strategies with DITTO (72.1% win-rate) > SFT (60.1%) > few-shot (48.1%) > self-prompt (44.2%) > zero-shot (25.0%). Additionally, self-promoting performs somewhat worse than giving examples in a few-shot immediate and underperforms DITTO.
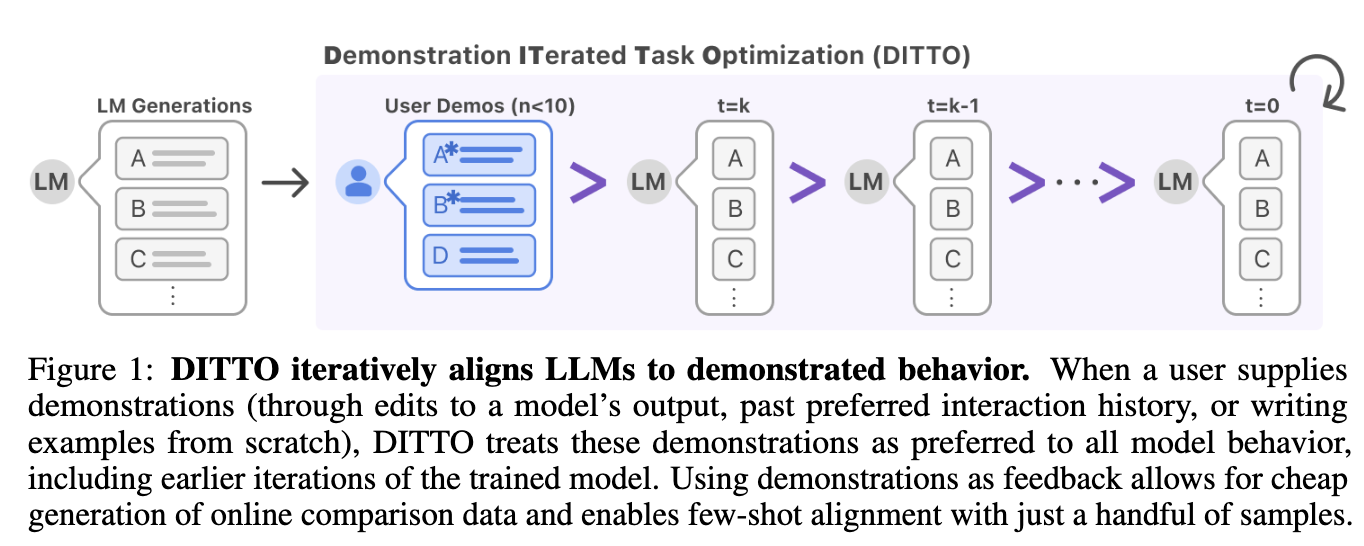
In conclusion, researchers from Standford College have launched Demonstration ITerated Job Optimization (DITTO), a technique that aligns language mannequin outputs immediately with the person’s demonstrated behaviors and generates on-line comparability information from demonstrations. On this paper, researchers highlighted the significance of utilizing demonstrations as suggestions and proved that even a small variety of demonstrated behaviors can present a robust sign of a person’s particular preferences. Nevertheless, different mannequin sizes aren’t examined by researchers due to computational price, and extra evaluation is required by the forms of choice information wanted. So, there’s a want for future work on this area.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.

iQOO Z9x 5G (Tornado Green, 4GB RAM, 128GB Storage) | Snapdragon 6 Gen 1 with 560K+ AnTuTu Score | 6000 mAh Battery with 7.99mm Slim Design | 44W FlashCharge
₹12,999.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus 11R 5G (Sonic Black, 8GB RAM, 128GB Storage)
₹27,999.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes Atom 81 in Ear TWS Earbuds with Upto 50H Playtime, Quad Mics ENx Tech, 13MM Drivers,Super Low Latency(50ms), ASAP Charge, BT v5.3(Opal Black)
₹899.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z9x 5G (Storm Grey, 6GB RAM, 128GB Storage) | Snapdragon 6 Gen 1 with 560K+ AnTuTu Score | 6000 mAh Battery with 7.99mm Slim Design | 44W FlashCharge
₹14,499.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,399.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹323.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Amazon Brand - Solimo Fast Charging Braided Type C Data Cable Joint, Suitable For All Supported Mobile Phones (1 Meter, Black)
₹69.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Bajaj Pygmy Go 178 mm Mini Fan with LED Lighting| Rechargeable Fan| USB Charging Fan| 4-hours Battery Backup| 3 Fan Speed| 2-Light Brightness Setting| High Speed Table Fan| Blue Portable Fan
₹1,749.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics My Buddy K Portable Laptop Stand with Adjustable Height, Foldable, OverHeating Protection for Laptops & MacBooks (Grey)
₹495.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Mpad Mouse Mat 230X190X3mm Gaming Mouse Pad, Non-Slip Rubber Base, Waterproof Surface, Premium-Textured, Compatible with Laser and Optical Mice(Universe Black)
₹149.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$99.99 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
UnionSine 1TB Ultra Slim Portable External Hard Drive HDD-USB 3.0 for PC, Mac, Laptop, PS4, Xbox one,Xbox 360-Super Fast Transmission-HD-2510(Black)
$54.19 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Western Digital 2TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0020BBK-WESN
$72.99 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 7 7800X3D 8-Core, 16-Thread Desktop Processor
$339.99 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)