
Introduction
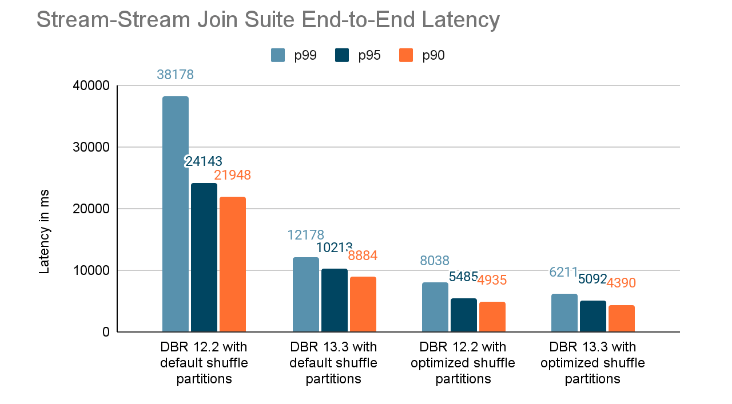
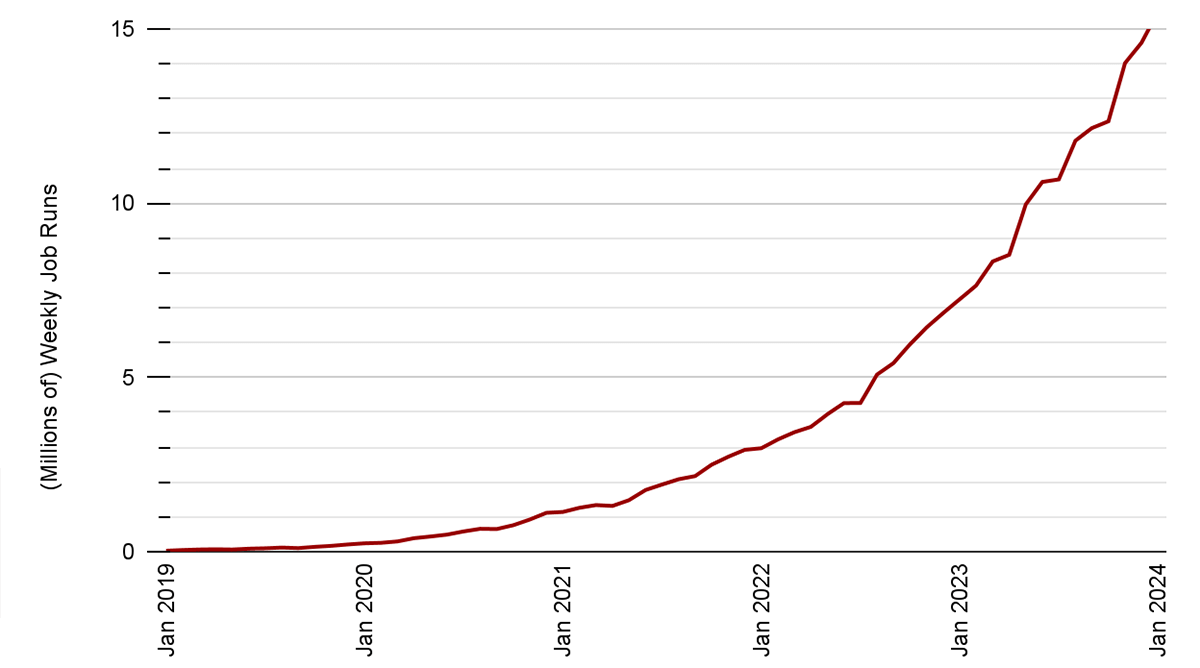
Apache Spark™ Structured Streaming is a well-liked open-source stream processing platform that gives scalability and fault tolerance, constructed on prime of the Spark SQL engine. Most incremental and streaming workloads on the Databricks Lakehouse Platform are powered by Structured Streaming, together with Delta Dwell Tables and Auto Loader. We have now seen exponential progress in Structured Streaming utilization and adoption for a various set of use circumstances throughout all industries over the previous few years. Over 14 million Structured Streaming jobs run per week on Databricks, with that quantity rising at a price of greater than 2x per 12 months.
Most Structured Streaming workloads might be divided into two broad classes: analytical and operational workloads. Operational workloads run important elements of a enterprise in real-time. In contrast to analytical processing, operational processing emphasizes well timed transformations and actions on the information. Operational processing structure permits organizations to shortly course of incoming information, make operational choices, and set off fast actions based mostly on the real-time insights derived from the information.
For such operational workloads, constant low latency is a key requirement. On this weblog, we are going to give attention to the efficiency enhancements Databricks has carried out as a part of Challenge Lightspeed that can assist obtain this requirement for stateful pipelines utilizing Structured Streaming.
Our efficiency analysis signifies that these enhancements can enhance the stateful pipeline latency by as much as 3–4x for workloads with a throughput of 100k+ occasions/sec operating on Databricks Runtime 13.3 LTS onward. These refinements open the doorways for a bigger number of workloads with very tight latency SLAs.
This weblog is in two elements – this weblog, Half 1, delves into the efficiency enhancements and features and Half 2 supplies a complete deep dive and superior insights of how we achieved these efficiency enhancements.
Word that this weblog publish assumes the reader has a fundamental understanding of Apache Spark Structured Streaming.
Background
Stream processing might be broadly categorized into stateless and stateful classes:
- Stateless pipelines normally require every micro-batch to be processed independently with out remembering any context between micro-batches. Examples embody streaming ETL pipelines that remodel information on a per-record foundation (e.g., filtering, branching, mapping, or iterating).
- Stateful pipelines typically contain aggregating info throughout data that seem in a number of micro-batches (e.g., computing a mean over a time window). To finish such operations, these pipelines want to recollect information that they’ve seen throughout micro-batches, and this state must be resilient throughout pipeline restarts.
Stateful streaming pipelines are used principally for real-time use circumstances resembling product and content material suggestions, fraud detection, service well being monitoring, and many others.
What Are State and State Administration?
State within the context of Apache Spark queries is the intermediate persistent context maintained between micro-batches of a streaming pipeline as a group of keyed state shops. The state retailer is a versioned key-value retailer offering each learn and write operations. In Structured Streaming, we use the state retailer supplier abstraction to implement the stateful operations. There are two built-in state retailer supplier implementations:
- The HDFS-backed state retailer supplier shops all of the state information within the executors’ JVM reminiscence and is backed by information saved persistently in an HDFS-compatible filesystem. All updates to the shop are achieved in units transactionally, and every set of updates increments the shop’s model. These variations can be utilized to re-execute the updates on the proper model of the shop and regenerate the shop model if wanted. Since all updates are saved in reminiscence, this supplier can periodically run into out-of-memory points and rubbish assortment pauses.
- The RocksDB state retailer supplier maintains state inside RocksDB cases, one per Spark partition on every executor node. On this case, the state can also be periodically backed as much as a distributed filesystem and can be utilized for loading a selected state model.
Databricks recommends utilizing the RocksDB state retailer supplier for manufacturing workloads as, over time, it’s common for the state dimension to develop to exceed hundreds of thousands of keys. Utilizing this supplier avoids the dangers of operating into JVM heap-related reminiscence points or slowness attributable to rubbish assortment generally related to the HDFS state retailer supplier.
Benchmarks
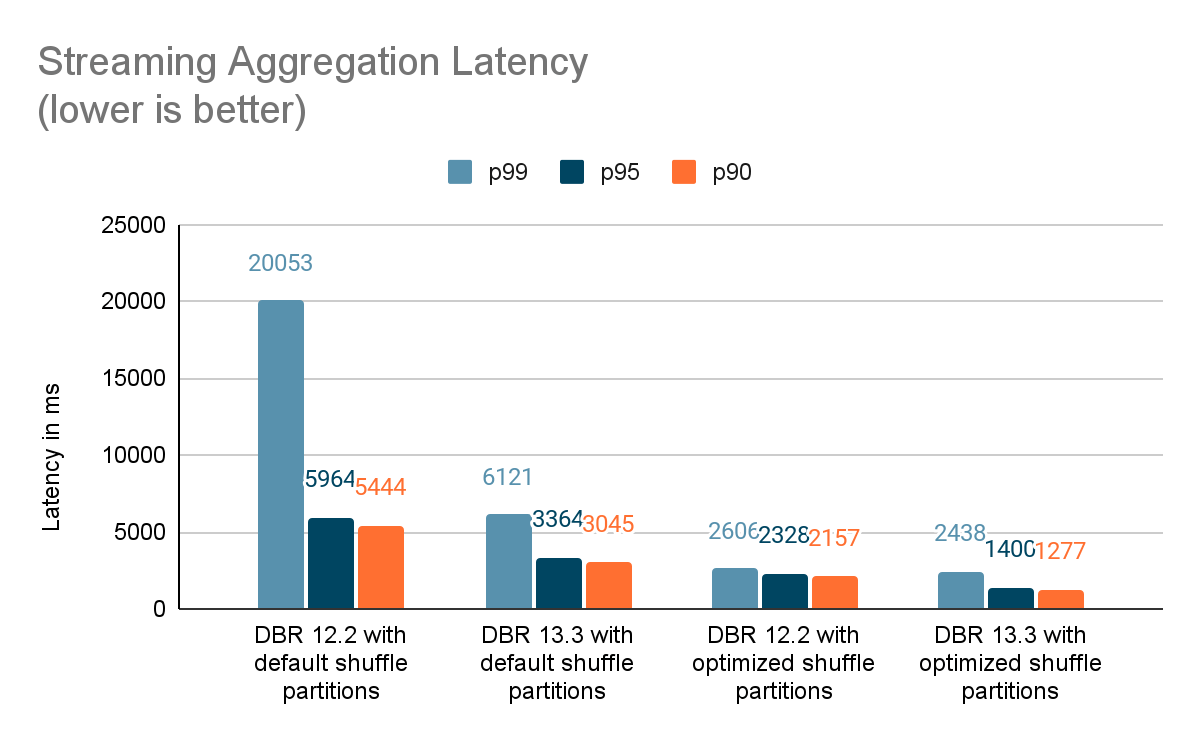
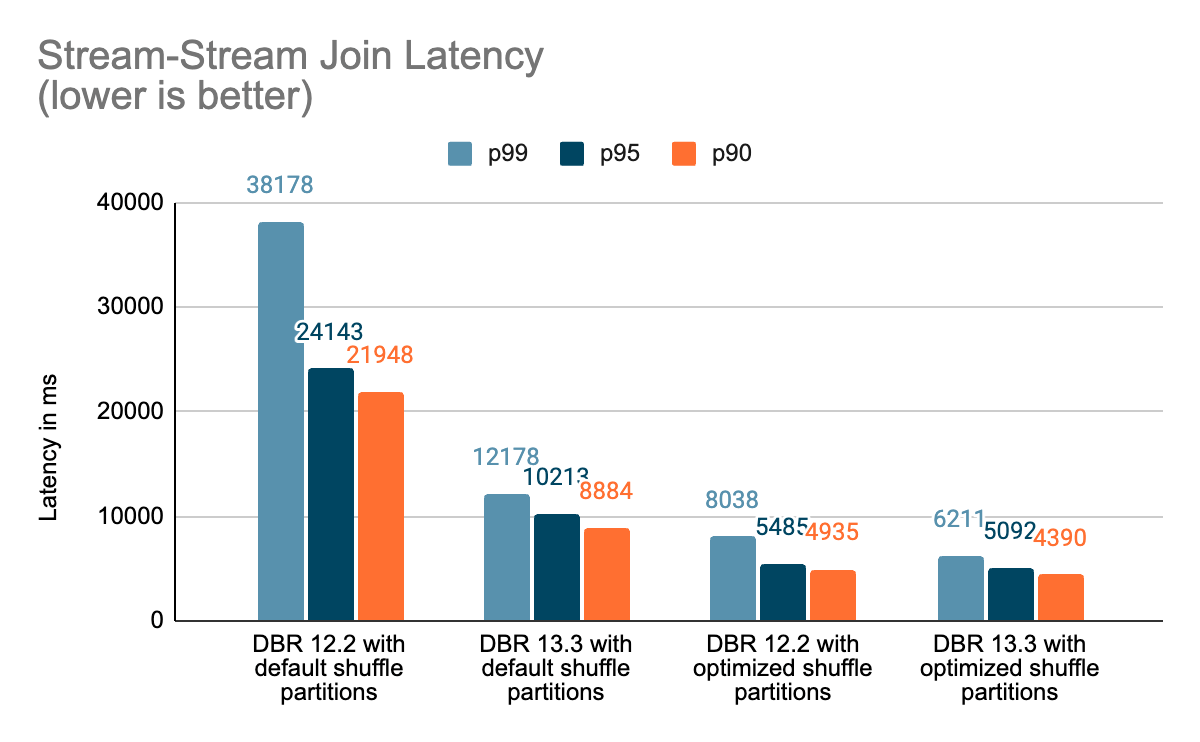
We created a set of benchmarks to grasp higher the efficiency of stateful streaming pipelines and the results of our enhancements. We generated information from a supply at a continuing throughput for testing functions. The generated data contained details about when the data had been created. For all stateful streaming benchmarks, we tracked end-to-end latency on a per-record foundation. On the sink facet, we used the Apache DataSketches library to gather the distinction between the time every report was written to the sink and the timestamp generated by the supply. This information was used to calculate the latency in milliseconds.
For the Kafka benchmark, we put aside some cluster nodes for operating Kafka and producing the information for feeding to Kafka. We calculated the latency of a report solely after the report had been efficiently printed to Kafka (on the sink). All of the checks had been run with RocksDB because the state retailer supplier for stateful streaming queries.
All checks beneath ran on i3.2xlarge cases in AWS with 8 cores and 61 GB RAM. Checks ran with one driver and 5 employee nodes, utilizing DBR 12.2 (with out the enhancements) as the bottom picture and DBR 13.3 LTS (which incorporates all of the enhancements) because the take a look at picture.
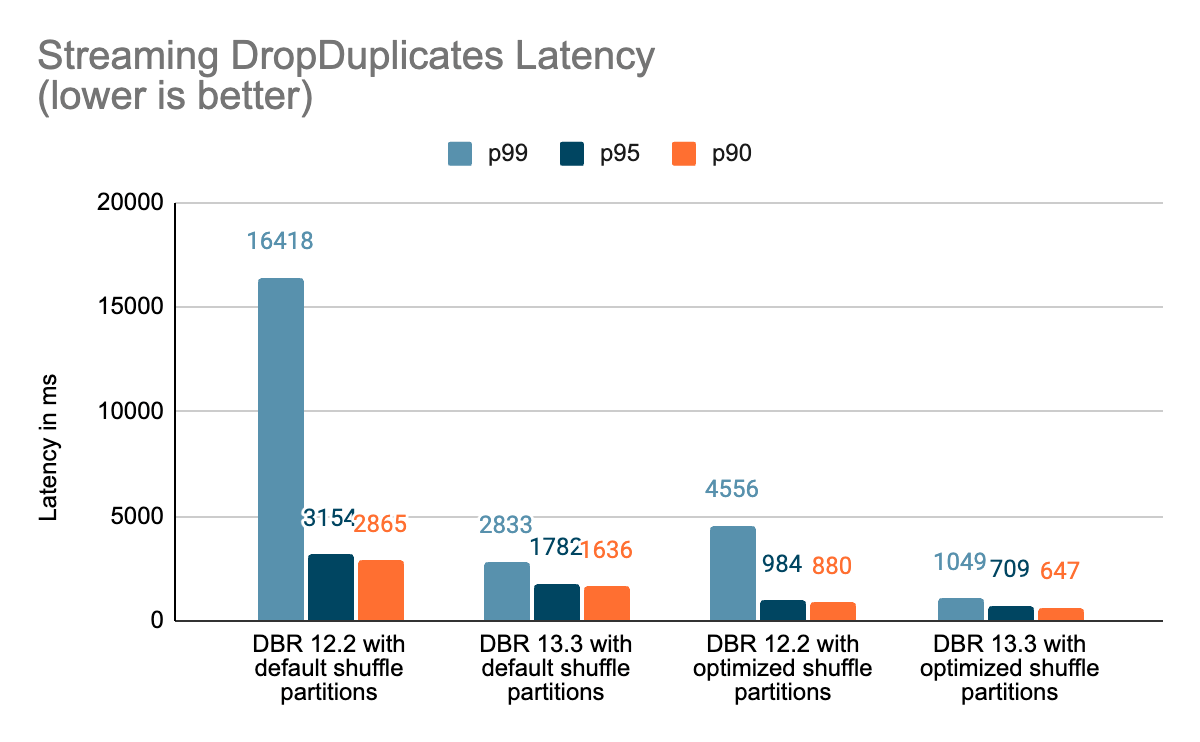
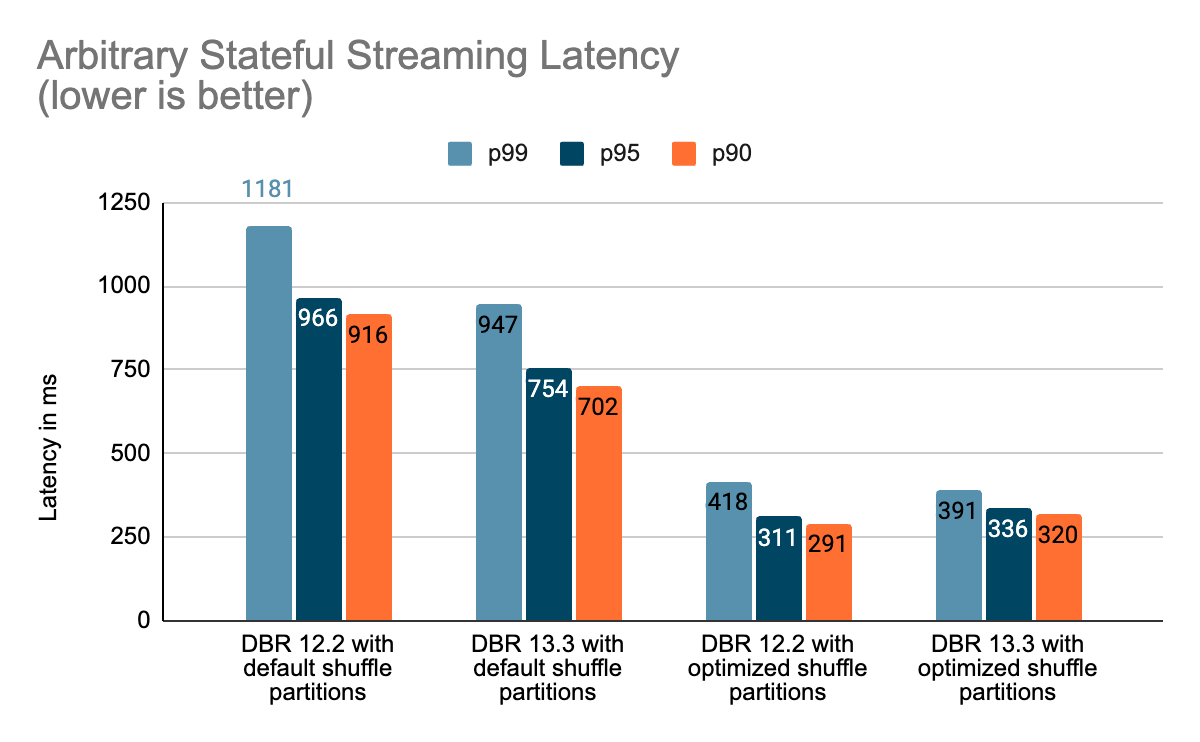
Conclusion
On this weblog, we offered a high-level overview of the benchmark we have carried out to showcase the efficiency enhancements talked about within the Challenge Lightspeed replace weblog. Because the benchmarks present, the efficiency enhancements we’ve added unlock a whole lot of pace and worth for purchasers operating stateful pipelines utilizing Spark Structured Streaming on Databricks. The added efficiency enhancements to stateful pipelines deserve their very own time for a extra in-depth dialogue, which you’ll be able to sit up for within the subsequent weblog publish “A Deep Dive Into the Newest Efficiency Enhancements of Stateful Pipelines in Apache Spark Structured Streaming“.
Availability
All of the options talked about above can be found from the DBR 13.3 LTS launch.

boAt Airdopes Atom 81 TWS Earbuds with Upto 50H Playtime, Quad Mics ENx™ Tech, 13MM Drivers,Super Low Latency(50ms), ASAP™ Charge, BT v5.3(Opal Black)
₹899.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z7s 5G by vivo (Pacific Night, 8GB RAM, 128GB Storage) | Ultra Bright AMOLED Display | Snapdragon 695 5G 6nm Processor | 64 MP OIS Ultra Stable Camera | 44WFlashCharge
(as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth in Ear Earphones with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.0(Cosmic Grey)
₹999.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CP PLUS 3 MP Full HD Smart Wi-fi CCTV Camera | 360° Pan & Tilt | View & Talk | Motion Alert | Night Vision | SD Card (Up to 128 GB) | Alexa & OK Google | 2-Way Talk | IR Distance 10Mtr | CP-E35A
₹1,299.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹664.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive, Metal, Silver
₹396.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Immortal 141 TWS Gaming in Ear Earbuds with Enx Tech,Up to 40 Hrs Playtime,Signature Sound,Beast Mode,Ipx4 Resistance,Iwp Tech,RBG Lights,&USB Type-C Port(Black Sabre)
₹899.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS Zeb-Dash Plus 2.4GHz High Precision Wireless Mouse with up to 1600 DPI, Power Saving Mode, Nano Receiver and Plug & Play Usage - USB
₹203.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹679.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L 1.2M POR-1401 Fast Charging 3A 8 Pin USB Cable with Charge & Sync Function (White)
₹129.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 1TB Portable External Hard Drive USB 3.0, Black - HDTB510XK3AA
$55.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Western Digital WD 1TB My Passport Portable External Hard Drive with backup software and password protection, Black - WDBYVG0010BBK-WESN
$54.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$67.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ARCTIC MX-4 (incl. Spatula, 4 g) - Premium Performance Thermal Paste for all processors (CPU, GPU - PC, PS4, XBOX), very high thermal conductivity, long durability, safe application, CPU Thermal Paste
$5.38 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)