

Giant capability fashions, corresponding to Giant Language Fashions (LLMs) and Giant Multi-modal Fashions (LMMs), have demonstrated effectiveness throughout varied domains and duties. Scaling up these fashions by rising parameter depend enhances efficiency however considerably reduces inference pace, limiting practicality. Sparse Mixtures of Consultants (SMoE) provide a promising different, enabling mannequin scalability whereas mitigating computational prices. Nonetheless, SMoE faces two key challenges: i) low knowledgeable activation and ii) restricted analytical capabilities, which hinder its effectiveness and scalability.
SMoE enhances mannequin capability whereas sustaining fixed computational demand, yielding superior efficiency in comparison with densely-activated fashions. Not like dense fashions, SMoE employs N-independent Feed-Ahead Networks (FFN) as consultants inside every Combination-of-Consultants (MoE) layer and a gating perform to distribute weights over these consultants’ outputs. The routing mechanism selects the top-k consultants from N consultants, the place ok << N facilitates information and knowledgeable parallelism. Bigger ok values usually enhance mannequin efficiency however can cut back coaching effectivity.
Researchers from Tsinghua College and Microsoft Analysis introduce Multi-Head Combination-of-Consultants (MH-MoE). MH-MoE utilises a multi-head mechanism to divide every enter token into a number of sub-tokens and distribute them throughout completely different consultants, attaining denser knowledgeable activation with out rising computational or parameter complexity. In distinction to SMoE, MH-MoE prompts 4 consultants for a single enter token by splitting it into 4 sub-tokens. This allocation permits the mannequin to concentrate on varied illustration areas inside consultants, facilitating a extra nuanced understanding of imaginative and prescient and language patterns.

The structure of MH-MoE addresses problems with low knowledgeable activation and token ambiguity by using a multi-head mechanism to separate tokens into sub-tokens and route them to numerous consultants. In MH-MoE, every parallel layer incorporates a set of N consultants, with a multi-head layer projecting inputs adopted by token splitting and gating capabilities to route sub-tokens to consultants. The highest-k routing mechanism prompts consultants with the best scores, and the ensuing sub-tokens are processed by these activated consultants and rearranged earlier than token merging to take care of input-output form consistency. The Token-Splitting-Merging (TSM) operation will increase the info quantity routed to particular consultants, leading to denser knowledgeable activation and improved understanding. This course of ensures no further computational price in subsequent blocks, with a hyperparameter β used to steadiness parameters and computational complexity with the unique SMoE.

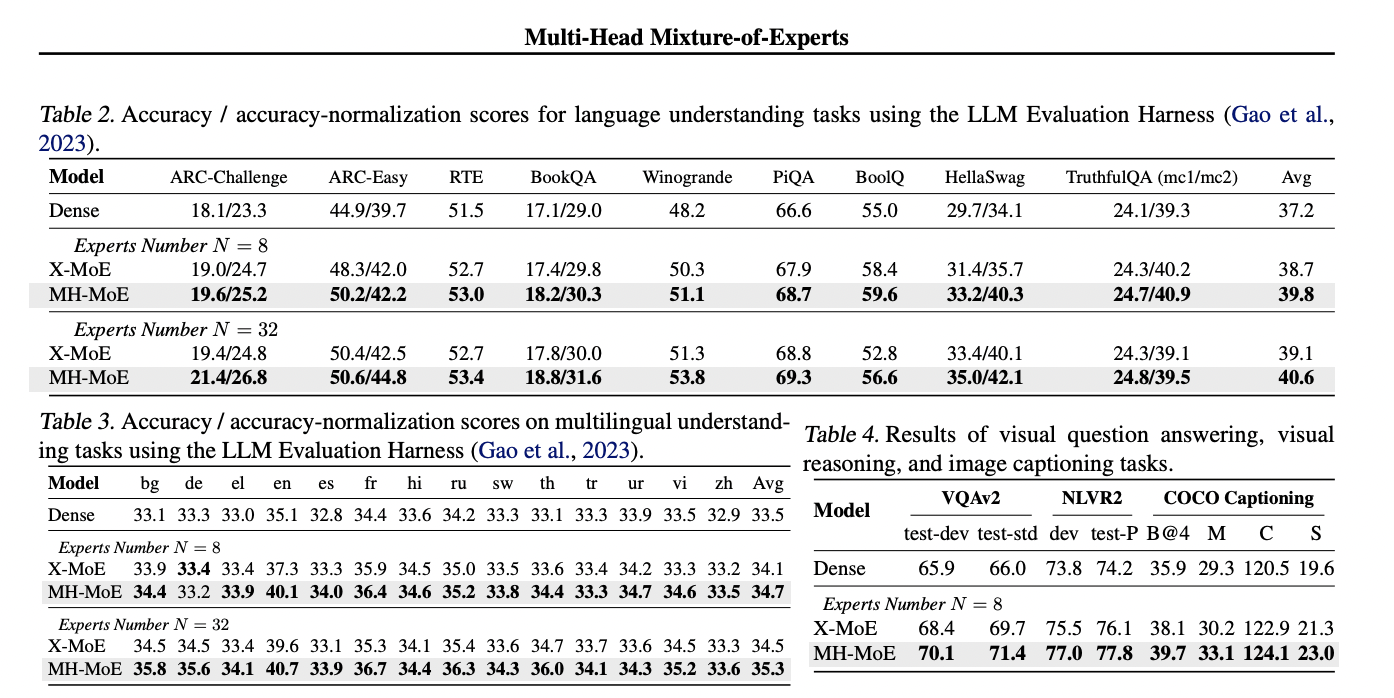
The validation perplexity curves for all pretrained fashions and pre-training duties are examined below two knowledgeable settings (8 consultants and 32 consultants). MH-MoE persistently maintains decrease perplexity than the baselines throughout varied experimental setups, indicating simpler studying. Additionally, rising the variety of consultants correlates with a lower in perplexity for MH-MoE, suggesting enhanced illustration studying capabilities. Downstream analysis throughout completely different pre-training duties additional validates the efficacy of MH-MoE. In English-focused language modeling, MH-MoE achieves the perfect efficiency throughout a number of benchmarks, demonstrating its effectiveness in enhancing language illustration. Equally, MH-MoE outperforms X-MoE persistently in multi-lingual language modeling, showcasing its superiority in modeling cross-lingual pure language. In masked multi-modal modeling duties corresponding to visible query answering, visible reasoning, and picture captioning, MH-MoE persistently outperforms Dense and X-MoE baselines, underscoring its potential to seize numerous semantic and detailed info inside visible information.
In conclusion, This paper investigates strategies for attaining denser knowledgeable activation with out introducing further price whereas enhancing fine-grained understanding potential. The proposed MH-MoE gives an easy implementation of those functionalities. Additionally, MH-MoE’s simplicity facilitates seamless integration with different SMoE frameworks, enhancing efficiency simply. In depth empirical outcomes throughout three duties validate the effectiveness of MH-MoE in attaining these aims.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 40k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

Redmi 13C (Starfrost White, 4GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹7,699.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics iKonnect C Pro Type C to 3.5 mm Audio Jack Connector with DAC Headphone Converter Adapter Compatible with iPhone 15 Pro Max/15 Pro/15 Plus, Galaxy S23/S22/S21/S208 & Other Type C Phones
₹219.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oneplus Nord CE4 (Celadon Marble, 8GB RAM, 256GB Storage)
₹26,999.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple iPhone 13 (128GB) - Midnight
₹49,499.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme Buds 2 Wired in Ear Earphones with Mic (Black)
₹599.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹667.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,399.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹698.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹249.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Max in Ear Earphones with 60H Playtime,Eq Modes,Power Magnetic Earbuds,Beast Mode,Enx Tech,ASAP Charge(10 Mins=10 Hrs),Textured Finish,Dual Pair(Stunning Black),Bluetooth
₹1,099.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$99.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SanDisk 1TB Extreme Portable SSD - Up to 1050MB/s, USB-C, USB 3.2 Gen 2, IP65 Water and Dust Resistance, Updated Firmware - External Solid State Drive - SDSSDE61-1T00-G25
$95.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
LaCie Rugged Mini 2TB External Hard Drive Portable HDD - USB 3.0/ 2.0 Compatible, Drop Shock Dust Rain Resistant Shuttle Drive, For Mac And PC Computer (LAC9000298), orange
$93.46 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ELEGOO 120pcs Multicolored Dupont Wire 40pin Male to Female, 40pin Male to Male, 40pin Female to Female Breadboard Jumper Ribbon Cables Kit Compatible with Arduino Projects
$6.98 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)