

Machine studying fashions have been working for a very long time on a single information mode or unimodal mode. This concerned textual content for translation and language modeling, photos for object detection and picture classification, and audio for speech recognition.
Nevertheless, it is a well-known proven fact that human intelligence isn’t restricted to a single information modality as human beings are able to studying in addition to writing textual content. People are able to seeing photos and watching movies. They are often looking out for unusual noises to detect hazard and take heed to music on the similar time for rest. Therefore, working with multimodal information is critical for each people and synthetic intelligence (AI) to operate in the true world.
A serious headway in AI analysis and growth is most likely the incorporation of further modalities like picture inputs into massive language fashions (LLMs) ensuing within the creation of huge multimodal fashions (LMMs). Now, one wants to know what precisely LMMs are as each multimodal system isn’t a
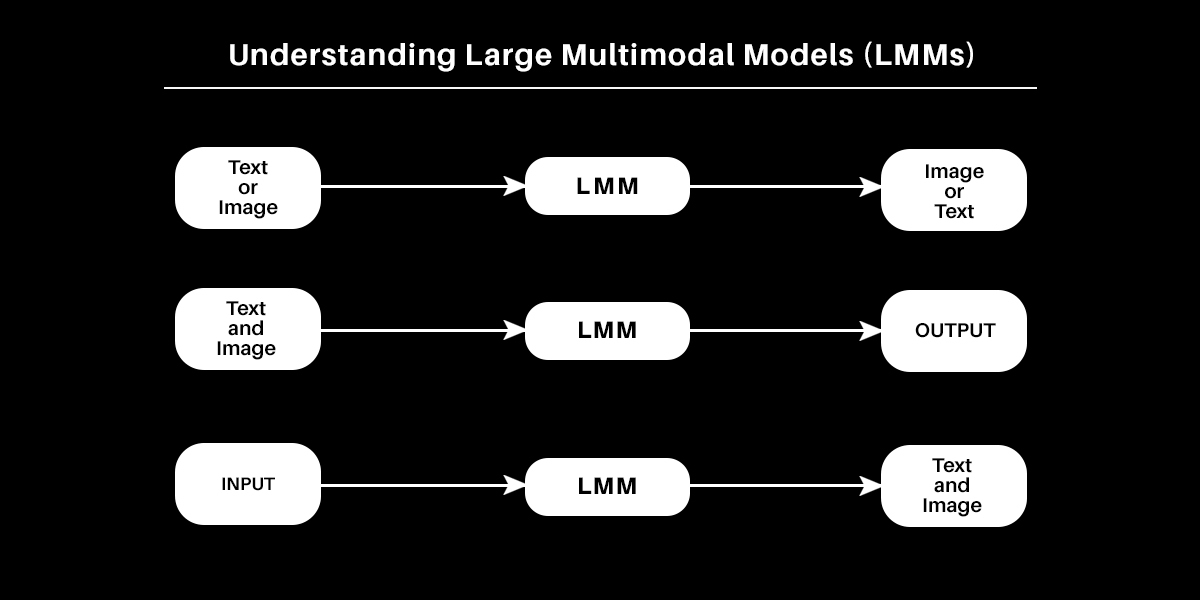
LMM. Multimodal might be any one of many following:
1. Enter and output comprise of various modalities (textual content to picture or picture to textual content).
2. Inputs are multimodal (each textual content and pictures might be processed).
3. Outputs are multimodal (a system can produce textual content in addition to photos).
Use Circumstances for Massive Multimodal Fashions
LMMs supply a versatile interface for interplay permitting one to work together with them in the very best method. It permits one to question by merely typing, speaking, or pointing their digicam at one thing. A particular use case value mentioning right here entails enabling blind folks to browse the Web. A number of use circumstances aren’t potential with out multimodality. These embrace industries dealing with a mixture of information modalities like healthcare, robotics, e-commerce, retail, gaming, and so forth. Additionally, bringing information from different modalities can help in boosting the efficiency of the mannequin.
Regardless that multimodal AI is not one thing new, it’s gathering momentum. It has great potential for remodeling human-like capabilities via growth in laptop imaginative and prescient and pure language processing. LMM is far nearer to imitating human notion than ever earlier than.
Given the know-how remains to be in its main stage, it’s nonetheless higher when in comparison with people in a number of exams. There are a number of fascinating functions of multimodal AI aside from simply context recognition. Multimodal AI assists with enterprise planning and makes use of machine studying algorithms since it may acknowledge numerous sorts of knowledge and affords significantly better and extra knowledgeable insights.
The mix of knowledge from totally different streams permits it to make predictions concerning an organization’s monetary outcomes and upkeep necessities. In case of previous gear not receiving the specified consideration, a multimodal AI can deduce that it does not require servicing steadily.
A multimodal strategy can be utilized by AI to acknowledge numerous sorts of knowledge. For example, an individual could perceive a picture via a picture, whereas one other via a video or a track. Varied sorts of languages will also be acknowledged which might show to be very helpful.
A mix of picture and sound can allow a human to explain an object in a way that a pc can not. Multimodal AI can help in limiting that hole. Together with laptop imaginative and prescient, multimodal programs can study from numerous sorts of knowledge. They’ll make selections by recognizing texts and pictures from a visible picture. They’ll additionally study them from context.
Summing up, a number of analysis tasks have investigated multimodal studying enabling AI to study from numerous sorts of knowledge enabling machines to understand a human’s message. Earlier a number of organizations had concentrated their efforts on increasing their unimodal programs, however, the latest growth of multimodal functions has opened doorways for chip distributors and platform firms.
Multimodal programs can resolve points which might be widespread with conventional machine studying programs. For example, it may incorporate textual content and pictures together with audio and video. The preliminary step right here entails aligning the interior illustration of the mannequin throughout modalities.
Many organizations have embraced this know-how. LMM framework derives its success based mostly on language, audio, and imaginative and prescient networks. It could actually resolve points in each area on the similar time by combining these applied sciences. For instance, Google Translate makes use of a multimodal neural community for translations which is a step within the route of speech integration, language, and imaginative and prescient understanding into one community.
The put up From Massive Language Fashions to Massive Multimodal Fashions appeared first on Datafloq.

OnePlus Nord CE 3 Lite 5G (Pastel Lime, 8GB RAM, 128GB Storage)
₹17,999.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes 91 in Ear TWS Earbuds with 45 hrs Playtime, Beast Mode with 50 ms Low Latency, Dual Mics with ENx, ASAP Charge, IWP Tech, IPX4 & Bluetooth v5.3(Active Black)
₹1,199.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CP PLUS 3 MP Full HD Smart Wi-fi CCTV Camera | 360° Pan & Tilt | View & Talk | Motion Alert | Night Vision | SD Card (Up to 128 GB) | Alexa & OK Google | 2-Way Talk | IR Distance 10Mtr | CP-E35A
₹1,299.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple 20W USB-C Power Adapter (for iPhone, iPad & AirPods)
₹1,599.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
POCO C51 (Royal Blue, 6GB RAM, 128GB Storage)
₹5,999.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 60W / 3A Fast Charging 1.5m Braided Micro USB Cable for Smartphones, Tablets, Laptops & other Micro USB devices, 480Mbps Data Sync, Quick Charge 3.0 (RCM15, Black)
₹149.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 25 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹299.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L POR-1403 Fast Charging 3A Type-C Cable 1.2 Meter with Charge & Sync Function for All Type-C Devices (White)
₹119.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Western Digital 2TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0020BBK-WESN
$72.99 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Storage Expansion Card 2TB Solid State Drive - NVMe SSD for Xbox Series X|S, Quick Resume, Plug & Play, Licensed (STJR2000400)
$249.99 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 7 7800X3D 8-Core, 16-Thread Desktop Processor
$364.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 2TB Portable External Hard Drive USB 3.0, Black - HDTB520XK3AA
$64.63 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)