

Information curation is vital in large-scale pretraining, considerably impacting language, imaginative and prescient, and multimodal modeling efficiency. Effectively-curated datasets can obtain sturdy efficiency with much less information, however present pipelines usually depend on guide curation, which is expensive and arduous to scale. Mannequin-based information curation, leveraging coaching mannequin options to pick out high-quality information, provides potential enhancements in scaling effectivity. Conventional strategies concentrate on particular person information factors, however batch high quality additionally is determined by composition. In pc imaginative and prescient, arduous negatives—clusters of factors with totally different labels—present a more practical studying sign than simply solvable ones.
Researchers from Google DeepMind have proven that deciding on batches of knowledge collectively relatively than independently enhances studying. Utilizing multimodal contrastive aims, they developed a easy JEST algorithm for joint instance choice. This methodology selects related sub-batches from bigger super-batches, considerably accelerating coaching and lowering computational overhead. By leveraging pretrained reference fashions, JEST guides the information choice course of, bettering efficiency with fewer iterations and fewer computation. Flexi-JEST, a variant of JEST, additional reduces prices utilizing variable patch sizing. This strategy outperforms state-of-the-art fashions, demonstrating the effectiveness of model-based information curation.
Offline curation strategies initially centered on the standard of textual captions and alignment with high-quality datasets, utilizing pretrained fashions like CLIP and BLIP for filtering. These strategies, nevertheless, fail to think about dependencies inside batches. Cluster-level information pruning strategies handle this by lowering semantic redundancy and utilizing core-set choice, however these are heuristic-based and decoupled from coaching aims. On-line information curation adapts throughout studying, addressing the constraints of mounted methods. Laborious damaging mining optimizes the collection of difficult examples, whereas mannequin approximation strategies enable smaller fashions to behave as proxies for bigger ones, enhancing information choice effectivity throughout coaching.
The tactic selects essentially the most related information sub-batches from a bigger super-batch utilizing model-based scoring features, contemplating losses from each the learner and pretrained reference fashions. Prioritizing high-loss batches for the learner can discard trivial information however may up-sample noise. Alternatively, deciding on low-loss information for the reference mannequin can establish high-quality examples however could also be overly depending on the reference mannequin. Combining these approaches, learnability scoring prioritizes unlearned and learnable information, accelerating large-scale studying. Environment friendly scoring with on-line mannequin approximation and multi-resolution coaching additional optimizes the method.
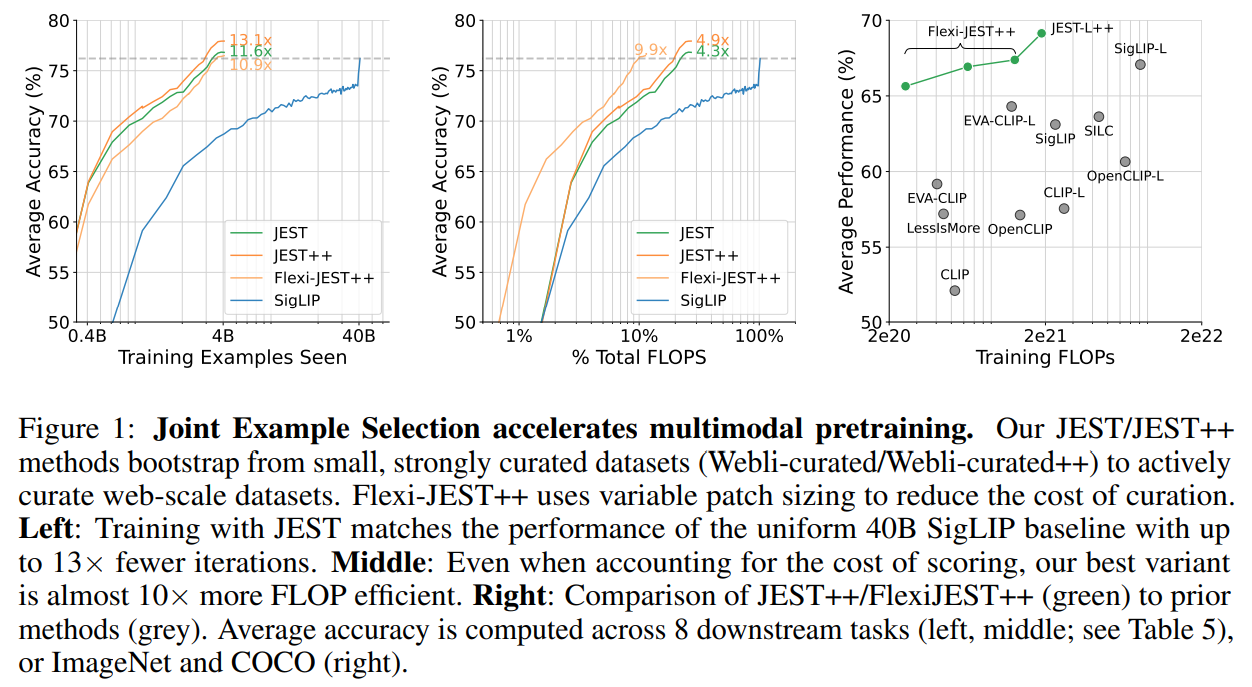
The efficacy of JEST for forming learnable batches was evaluated, revealing that JEST quickly will increase batch learnability with few iterations. It outperforms impartial choice, attaining efficiency corresponding to brute-force strategies. In multimodal studying, JEST considerably accelerates coaching and improves last efficiency, with advantages scaling with filtering ratios. Flexi-JEST, a compute-efficient variant utilizing multi-resolution coaching, additionally reduces computational overhead whereas sustaining speedups. JEST’s efficiency improves with stronger information curation, and it surpasses prior fashions on a number of benchmarks, demonstrating effectiveness in each coaching and compute effectivity.
In conclusion, The JEST methodology, designed for collectively deciding on essentially the most learnable information batches, considerably accelerates large-scale multimodal studying, attaining superior efficiency with as much as 10× fewer FLOPs and 13× fewer examples. It highlights the potential for “information high quality bootstrapping,” the place small curated datasets information studying on bigger, uncurated ones. In contrast to static dataset filtering, which might restrict efficiency, on-line building of helpful batches enhances pretraining effectivity. This implies that basis distributions can successfully substitute generic basis datasets, whether or not by way of pre-scored datasets or dynamically adjusted with learnability JEST. Nonetheless, the tactic depends on small, curated reference datasets, indicating a necessity for future analysis to deduce reference datasets from downstream duties.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.