

As digital interactions turn into more and more complicated, the demand for stylish analytical instruments to know and course of this various knowledge intensifies. The core problem entails integrating distinct knowledge varieties, primarily pictures, and textual content, to create fashions that may successfully interpret and reply to multimodal inputs. This problem is vital for purposes starting from automated content material era to enhanced interactive programs.
Current analysis contains fashions like LLaVa-NeXT and MM1, that are recognized for his or her strong multimodal capabilities. The LLaVa-NeXT sequence, significantly the 34B variant, and MM1-Chat fashions have set benchmarks in visible query answering and image-text integration. Gemini fashions like Gemini 1.0 Professional additional push efficiency in complicated AI duties. DeepSeek-VL focuses on visible query answering, whereas Claude 3 Haiku excels in producing narrative content material from visible inputs, showcasing various approaches to mixing visible and textual knowledge inside AI frameworks.
Hugging Face Researchers have launched Idefics2, a strong 8B parameter vision-language mannequin designed to reinforce the combination of textual content and picture processing inside a single framework. This technique contrasts with earlier fashions, which regularly required the resizing of pictures to fastened dimensions, doubtlessly compromising the element and high quality of visible knowledge. This functionality, derived from the NaViT technique, allows Idefics2 to course of visible data extra precisely and effectively. Integrating visible options into the language spine through discovered Perceiver pooling and an MLP modality projection additional distinguishes this mannequin, facilitating a deeper and extra nuanced understanding of multimodal inputs.
The mannequin was pre-trained on a mix of publicly obtainable assets, together with Interleaved internet paperwork, image-caption pairs from the Public Multimodal Dataset and LAION-COCO, and specialised OCR knowledge from PDFA, IDL, and Rendered-text. Furthermore, Idefics2 was fine-tuned utilizing “The Cauldron,” a rigorously curated compilation of fifty vision-language datasets. This fine-tuning part employed applied sciences like Lora for adaptive studying and particular fine-tuning methods for newly initialized parameters within the modality connector, which underpins the distinct functionalities of its numerous variations—starting from the generalist base mannequin to the conversationally adept Idefics2-8B-Chatty, poised for launch. Every model is designed to excel in numerous situations, from primary multimodal duties to complicated, long-duration interactions.
Variations of Idefics2:
Idefics2-8B-Base:
This model serves as the inspiration of the Idefics2 sequence. It has 8 billion parameters and is designed to deal with basic multimodal duties. The bottom mannequin is pre-trained on a various dataset, together with internet paperwork, image-caption pairs, and OCR knowledge, making it strong for a lot of primary vision-language duties.
Idefics2-8B:
The Idefics2-8B extends the bottom mannequin by incorporating fine-tuning on ‘The Cauldron,’ a specifically ready dataset consisting of fifty manually curated multimodal datasets and text-only instruction fine-tuning datasets. This model is tailor-made to carry out higher on complicated instruction-following duties, enhancing its means to know and course of multimodal inputs extra successfully.
Idefics2-8B-Chatty (Coming Quickly):
Anticipated as an development over the prevailing fashions, the Idefics2-8B-Chatty is designed for lengthy conversations and deeper contextual understanding. It’s additional fine-tuned for dialogue purposes, making it preferrred for situations that require prolonged interactions, corresponding to customer support bots or interactive storytelling purposes.
Enhancements over Idefics1:
- Idefics2 makes use of the NaViT technique for processing pictures in native resolutions, enhancing visible knowledge integrity.
- Enhanced OCR capabilities by means of specialised knowledge integration enhance textual content transcription accuracy.
- Simplified structure utilizing imaginative and prescient encoder and Perceiver pooling boosts efficiency considerably over Idefics1.
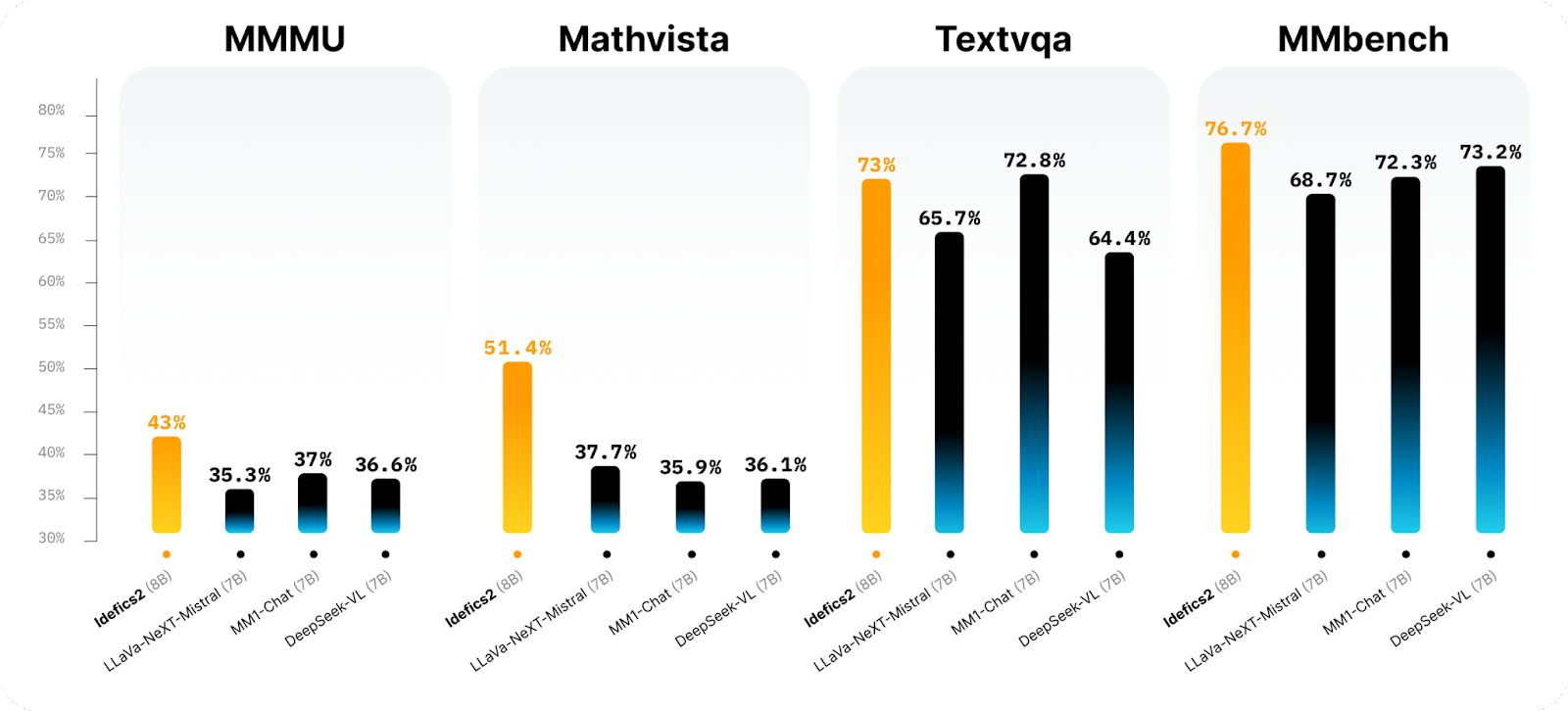
In testing, Idefics2 demonstrated distinctive efficiency throughout a number of benchmarks. The mannequin achieved an 81.2% accuracy in Visible Query Answering (VQA) on normal benchmarks, considerably surpassing its predecessor, Idefics1. Moreover, Idefics2 confirmed a 20% enchancment in character recognition accuracy in document-based OCR duties in comparison with earlier fashions. The enhancements in OCR capabilities particularly lowered the error charge from 5.6% to three.2%, establishing its efficacy in sensible purposes requiring excessive ranges of accuracy in textual content extraction and interpretation.
To conclude, the analysis launched Idefics2, a visionary vision-language mannequin that integrates native picture decision processing and superior OCR capabilities. The mannequin demonstrates important developments in multimodal AI, attaining top-tier ends in visible query answering and textual content extraction duties. By sustaining the integrity of visible knowledge and enhancing textual content recognition accuracy, Idefics2 represents a considerable leap ahead, promising to facilitate extra correct and environment friendly AI purposes in fields requiring refined multimodal evaluation.
Take a look at the HF Venture Web page and Weblog. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 40k+ ML SubReddit
For Content material Partnership, Please Fill Out This Type Right here..
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

Ambrane Unbreakable 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹179.00 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme narzo 60 5G (Mars Orange,8GB+128GB) 90Hz Super AMOLED Display | Ultra Premium Vegan Leather Design | with 33W SUPERVOOC Charger
₹14,499.00 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 Lite 5G (Chromatic Gray, 8GB RAM, 128GB Storage)
₹17,499.00 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z7s 5G by vivo (Norway Blue, 8GB RAM, 128GB Storage) | Ultra Bright AMOLED Display | Snapdragon 695 5G 6nm Processor | 64 MP OIS Ultra Stable Camera | 44WFlashCharge
₹15,999.00 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS New Launch Uzi High Precision Wired Gaming Mouse with 4 Buttons, Rainbow LED Lights, DPI Switch with 800/1200/1600/2400 DPI, Plug & Play, 3 Million clicks, Lightweight Mouse
₹199.00 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of April 18, 2024 13:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SanDisk Ultra Dual Drive Go USB Type C Pendrive for Mobile (Black, 128 GB, 5Y - SDDDC3-128G-I35)
₹929.00 (as of April 18, 2024 13:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹667.00 (as of April 18, 2024 13:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Mpad Mouse Mat 230X190X3mm Gaming Mouse Pad, Non-Slip Rubber Base, Waterproof Surface, Premium-Textured, Compatible with Laser and Optical Mice(Universe Black)
₹99.00 (as of April 18, 2024 13:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹296.00 (as of April 18, 2024 13:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell USB DVD Drive-DW316 , Black
$35.40 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Crucial T500 1TB Gen4 NVMe M.2 Internal Gaming SSD, Up to 7300MB/s, Laptop & Desktop Compatible + 1mo Adobe CC All Apps - CT1000T500SSD8
$79.99 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CORSAIR 4000D AIRFLOW Tempered Glass Mid-Tower ATX Case - High-Airflow - Cable Management System - Spacious Interior - Two Included 120 mm Fans - Black
$89.99 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SanDisk 2TB Extreme Portable SSD - Up to 1050MB/s, USB-C, USB 3.2 Gen 2, IP65 Water and Dust Resistance, Updated Firmware - External Solid State Drive - SDSSDE61-2T00-G25
$160.14 (as of April 18, 2024 12:55 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)