

We’re happy to announce the preview launch of the vector engine for Amazon OpenSearch Serverless. The vector engine offers a easy, scalable, and high-performing similarity search functionality in Amazon OpenSearch Serverless that makes it simple so that you can construct fashionable machine studying (ML) augmented search experiences and generative synthetic intelligence (AI) purposes with out having to handle the underlying vector database infrastructure. This publish summarizes the options and functionalities of our vector engine.
Utilizing augmented ML search and generative AI with vector embeddings
Organizations throughout all verticals are quickly adopting generative AI for its capacity to deal with huge datasets, generate automated content material, and supply interactive, human-like responses. Clients are exploring methods to rework the end-user expertise and interplay with their digital platform by integrating superior conversational generative AI purposes akin to chatbots, query and reply methods, and customized suggestions. These conversational purposes allow you to go looking and question in pure language and generate responses that carefully resemble human-like responses by accounting for the semantic that means, consumer intent, and question context.
ML-augmented search purposes and generative AI purposes use vector embeddings, that are numerical representations of textual content, picture, audio, and video knowledge to generate dynamic and related content material. The vector embeddings are skilled in your personal knowledge and signify the semantic and contextual attributes of the knowledge. Ideally, these embeddings may be saved and managed near your domain-specific datasets, akin to inside your present search engine or database. This lets you course of a consumer’s question to search out the closest vectors and mix them with extra metadata with out counting on exterior knowledge sources or extra software code to combine the outcomes. Clients need a vector database possibility that’s easy to construct on and allows them to maneuver rapidly from prototyping to manufacturing to allow them to give attention to creating differentiated purposes. The vector engine for OpenSearch Serverless extends OpenSearch’s search capabilities by enabling you to retailer, search, and retrieve billions of vector embeddings in actual time and carry out correct similarity matching and semantic searches with out having to consider the underlying infrastructure.
Exploring the vector engine’s capabilities
Constructed on OpenSearch Serverless, the vector engine inherits and advantages from its sturdy structure. With the vector engine, you don’t have to fret about sizing, tuning, and scaling the backend infrastructure. The vector engine mechanically adjusts sources by adapting to altering workload patterns and demand to offer persistently quick efficiency and scale. Because the variety of vectors grows from just a few thousand throughout prototyping to a whole lot of tens of millions and past in manufacturing, the vector engine will scale seamlessly, with out the necessity for reindexing or reloading your knowledge to scale your infrastructure. Moreover, the vector engine has separate compute for indexing and search workloads, so you may seamlessly ingest, replace, and delete vectors in actual time whereas making certain that the question efficiency your customers expertise stays unaffected. All the info is continued in Amazon Easy Storage Service (Amazon S3), so that you get the identical knowledge sturdiness ensures as Amazon S3 (eleven nines). Regardless that we’re nonetheless in preview, the vector engine is designed for manufacturing workloads with redundancy for Availability Zone outages and infrastructure failures.
The vector engine for OpenSearch Serverless is powered by the k-nearest neighbor (kNN) search function within the open-source OpenSearch Venture, confirmed to ship dependable and exact outcomes. Many shoppers as we speak are utilizing OpenSearch kNN search in managed clusters for providing semantic search and personalization of their purposes. With the vector engine, you will get the identical performance with the simplicity of a serverless surroundings. The vector engine helps the favored distance metrics akin to Euclidean, cosine similarity, and dot product, and might accommodate 16,000 dimensions, making it well-suited to help a variety of foundational and different AI/ML fashions. It’s also possible to retailer various fields with varied knowledge sorts akin to numeric, boolean, date, key phrase, geopoint for metadata, and textual content for descriptive info so as to add extra context to the saved vectors. Colocating the info sorts reduces the complexity and maintainability and avoids knowledge duplication, model compatibility challenges, and licensing points, successfully simplifying your software stack. As a result of the vector engine helps the identical OpenSearch open-source suite APIs, you may benefit from its wealthy question capabilities, akin to full textual content search, superior filtering, aggregations, geo-spatial question, nested queries for quicker retrieval of knowledge, and enhanced search outcomes. For instance, in case your use case requires you to search out the outcomes inside 15 miles of the requestor, the vector engine can do that in a single question, eliminating the necessity for sustaining two totally different methods after which combining the outcomes by means of software logic. With help for integration with LangChain, Amazon Bedrock, and Amazon SageMaker, you may simply combine your most well-liked ML and AI system with the vector engine.
The vector engine helps a variety of use circumstances throughout varied domains, together with picture search, doc search, music retrieval, product suggestion, video search, location-based search, fraud detection, and anomaly detection. We additionally anticipate a rising development for hybrid searches that mix lexical search strategies with superior ML and generative AI capabilities. For instance, when a consumer searches for a “pink shirt” in your e-commerce web site, semantic search helps develop the scope by retrieving all shades of pink, whereas preserving the tuning and boosting logic applied on the lexical (BM25) search. With OpenSearch filtering, you may additional improve the relevance of your search outcomes by offering customers with choices to refine their search primarily based on dimension, model, value vary, and availability in close by shops, permitting for a extra customized and exact expertise. The hybrid search help within the vector engine lets you question vector embeddings, metadata, and descriptive info inside a single question name, making it simple to offer extra correct and contextually related search outcomes with out constructing advanced software code.
You will get began in minutes with the vector engine by making a specialised vector search assortment underneath OpenSearch Serverless utilizing the AWS Administration Console, AWS Command Line Interface (AWS CLI), or the AWS software program growth package (AWS SDK). Collections are a logical grouping of listed knowledge that works collectively to help a workload, whereas the bodily sources are mechanically managed within the backend. You don’t should declare how a lot compute or storage is required or monitor the system to ensure it’s operating nicely. OpenSearch Serverless applies totally different sharding and indexing methods for the three accessible assortment sorts: time sequence, search, and vector search. The vector engine’s compute capability used for knowledge ingestion, and search and question are measured in OpenSearch Compute Items (OCUs). One OCU can deal with 4 million vectors for 128 dimensions or 500K for 768 dimensions at 99% recall fee. The vector engine is constructed on OpenSearch Serverless, which is a extremely accessible service and requires a minimal of 4 OCUs (two OCUs for the ingest together with main and standby, and two OCUs for the search with two lively replicas throughout Availability Zones) for that first assortment in an account. All subsequent collections utilizing the identical AWS Key Administration Service (AWS KMS) key can share these OCUs.
Get began with vector embeddings
To get began utilizing vector embeddings utilizing the console, full the next steps:
- Create a brand new assortment on the OpenSearch Serverless console.
- Present a reputation and elective description.
- At present, vector embeddings are supported completely by vector search collections; subsequently, for Assortment kind, choose Vector search.

- Subsequent, you will need to configure the safety insurance policies, which incorporates encryption, community, and knowledge entry insurance policies.
We’re introducing the brand new Straightforward create possibility, which streamlines the safety configuration for quicker onboarding. All the info within the vector engine is encrypted in transit and at relaxation by default. You possibly can select to carry your individual encryption key or use the one supplied by the service that’s devoted to your assortment or account. You possibly can select to host your assortment on a public endpoint or inside a VPC. The vector engine helps fine-grained AWS Identification and Entry Administration (IAM) permissions with the intention to outline who can create, replace, and delete encryption, community, collections, and indexes, thereby enabling organizational alignment.
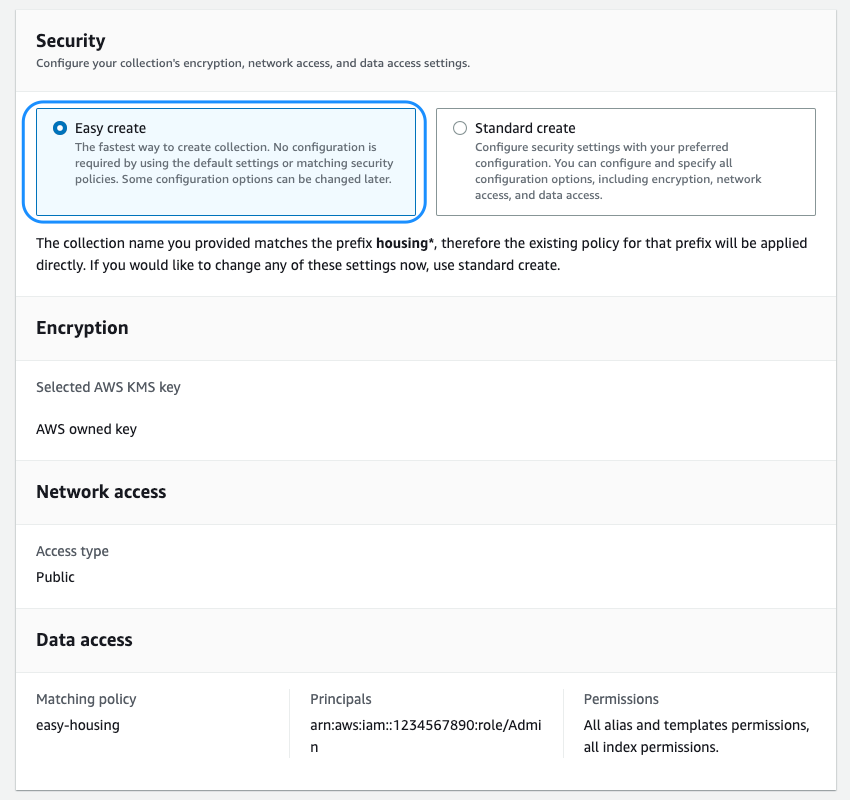
- With the safety settings in place, you may end creating the gathering.
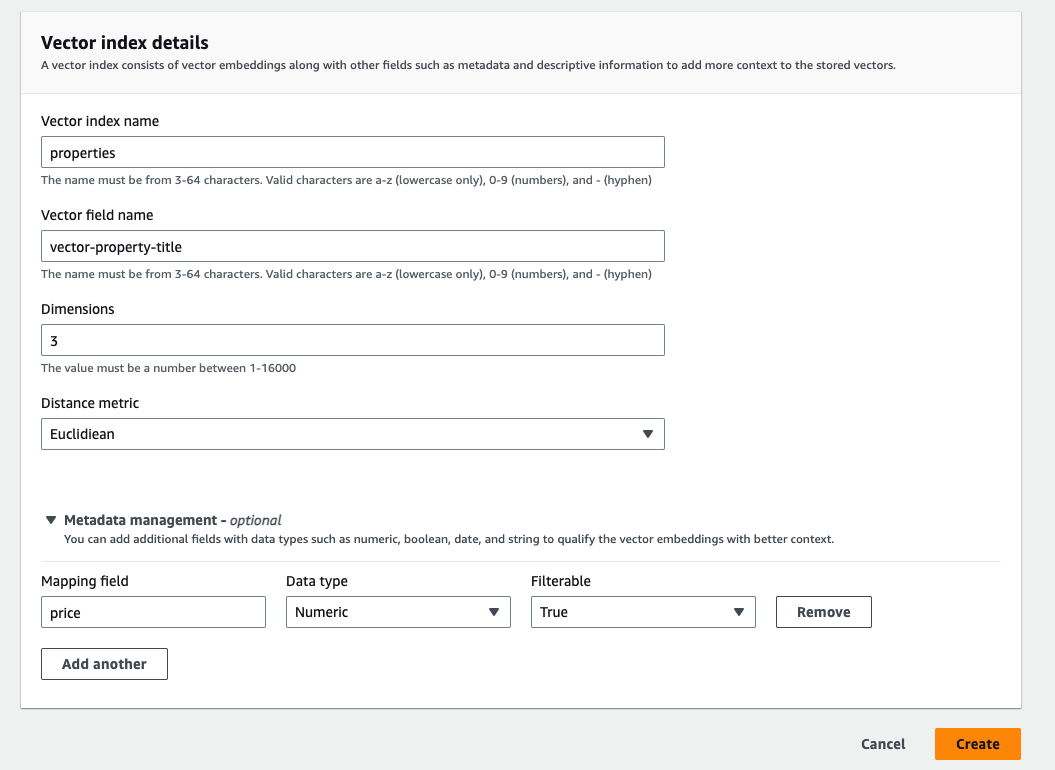
After the gathering is efficiently created, you may create the vector index. At this level, you need to use the API or the console to create an index. An index is a group of paperwork with a typical knowledge schema and offers a approach so that you can retailer, search, and retrieve your vector embeddings and different fields. The vector index helps as much as 1,000 fields.
- To create the vector index, you will need to outline the vector discipline title, dimensions, and the gap metric.
The vector index helps as much as 16,000 dimensions and three sorts of distance metrics: Euclidean, cosine, and dot product.
After you have efficiently created the index, you need to use OpenSearch’s highly effective question capabilities to get complete search outcomes.
The next instance reveals how simply you may create a easy property itemizing index with the title, description, value, and placement particulars as fields utilizing the OpenSearch API. Through the use of the question APIs, this index can effectively present correct outcomes to match your search requests, akin to “Discover me a two-bedroom condo in Seattle that’s underneath $3000.”
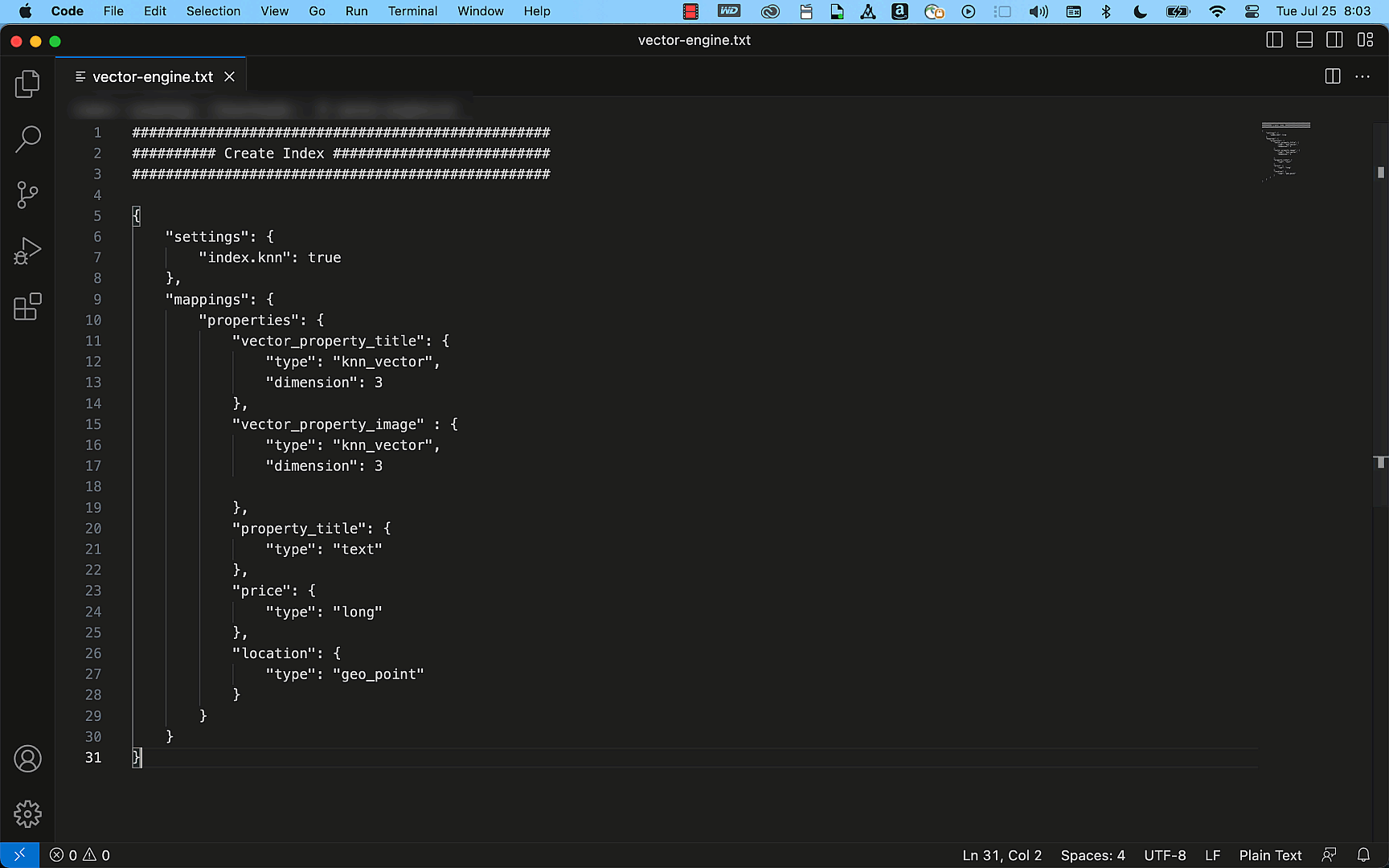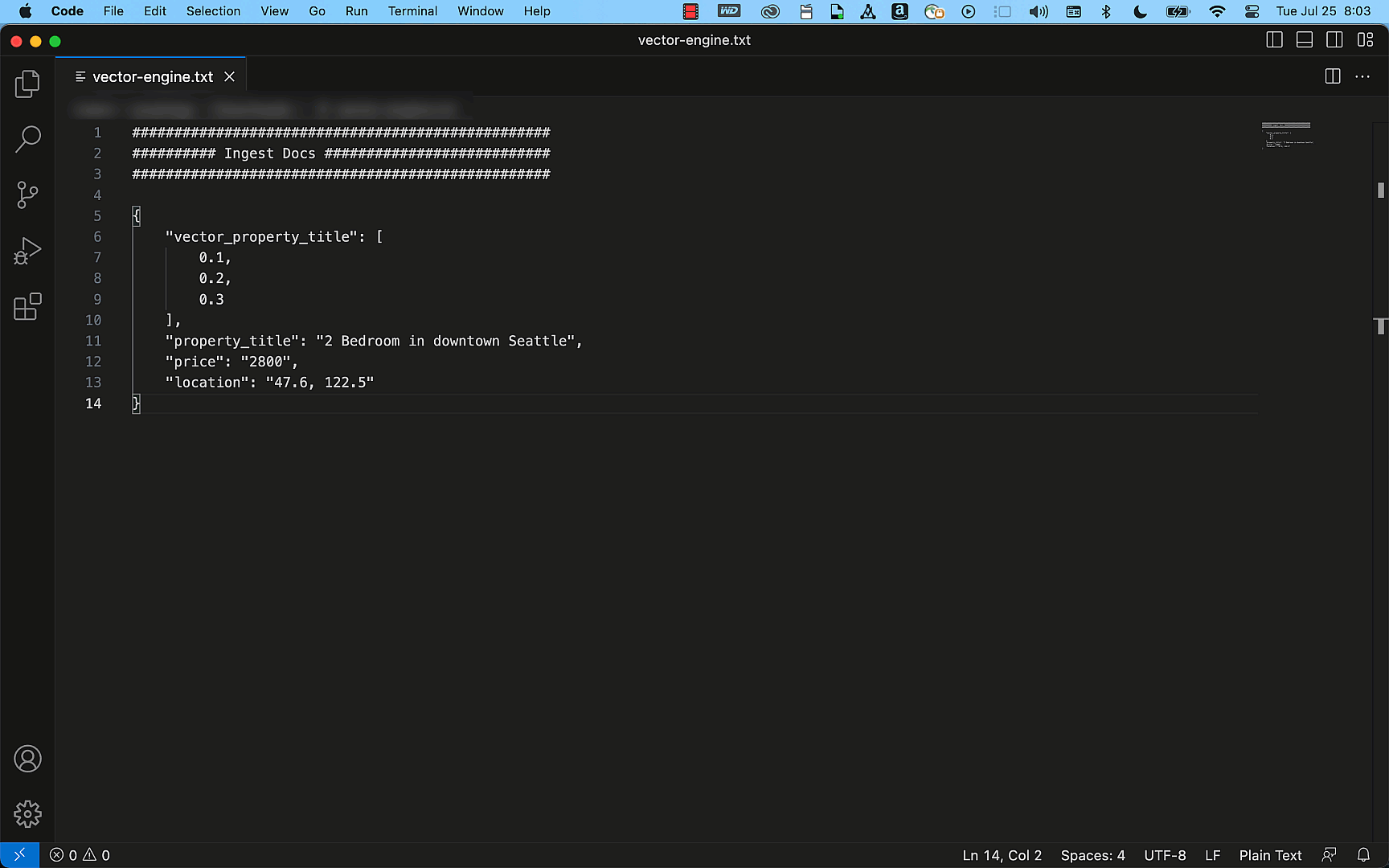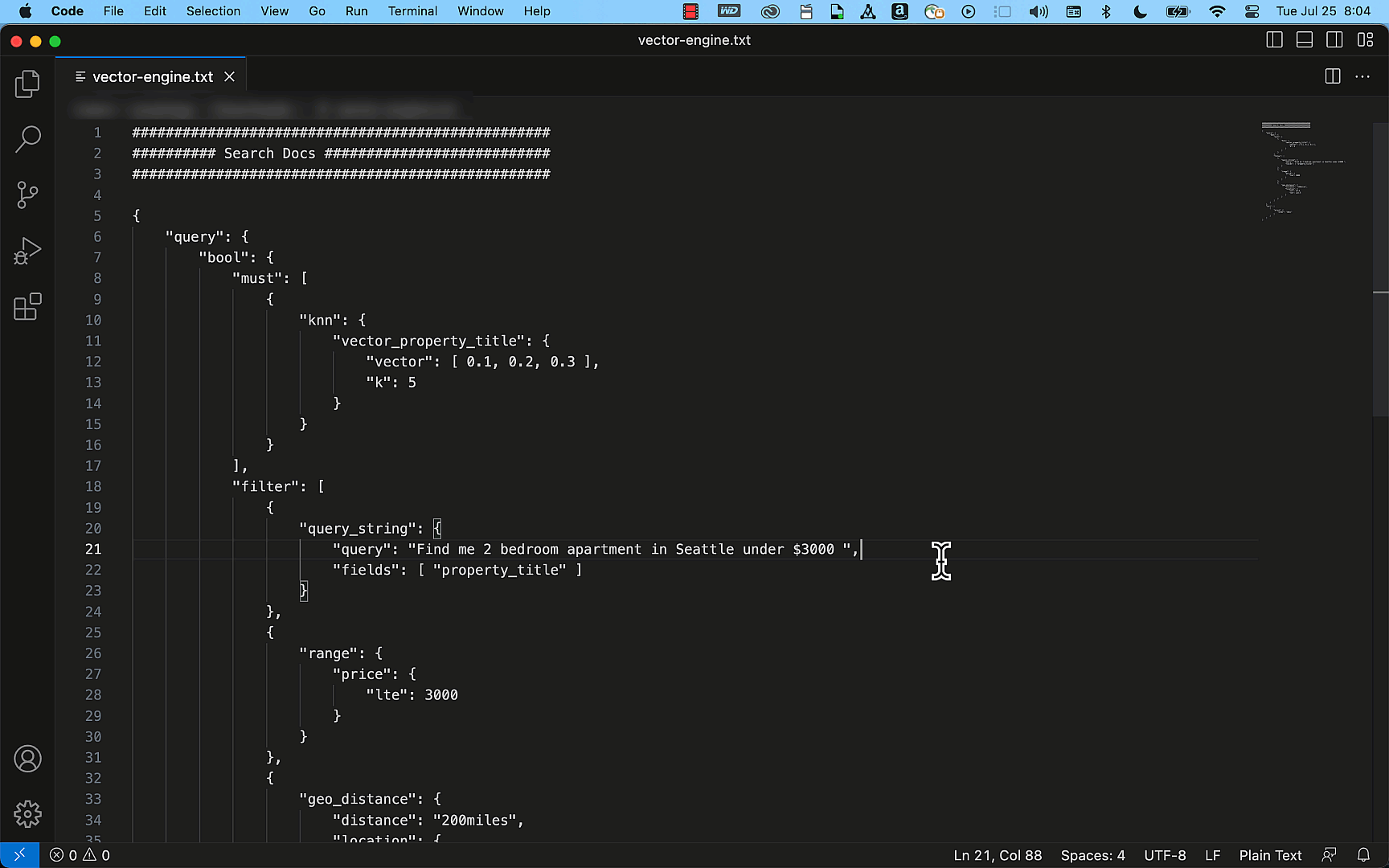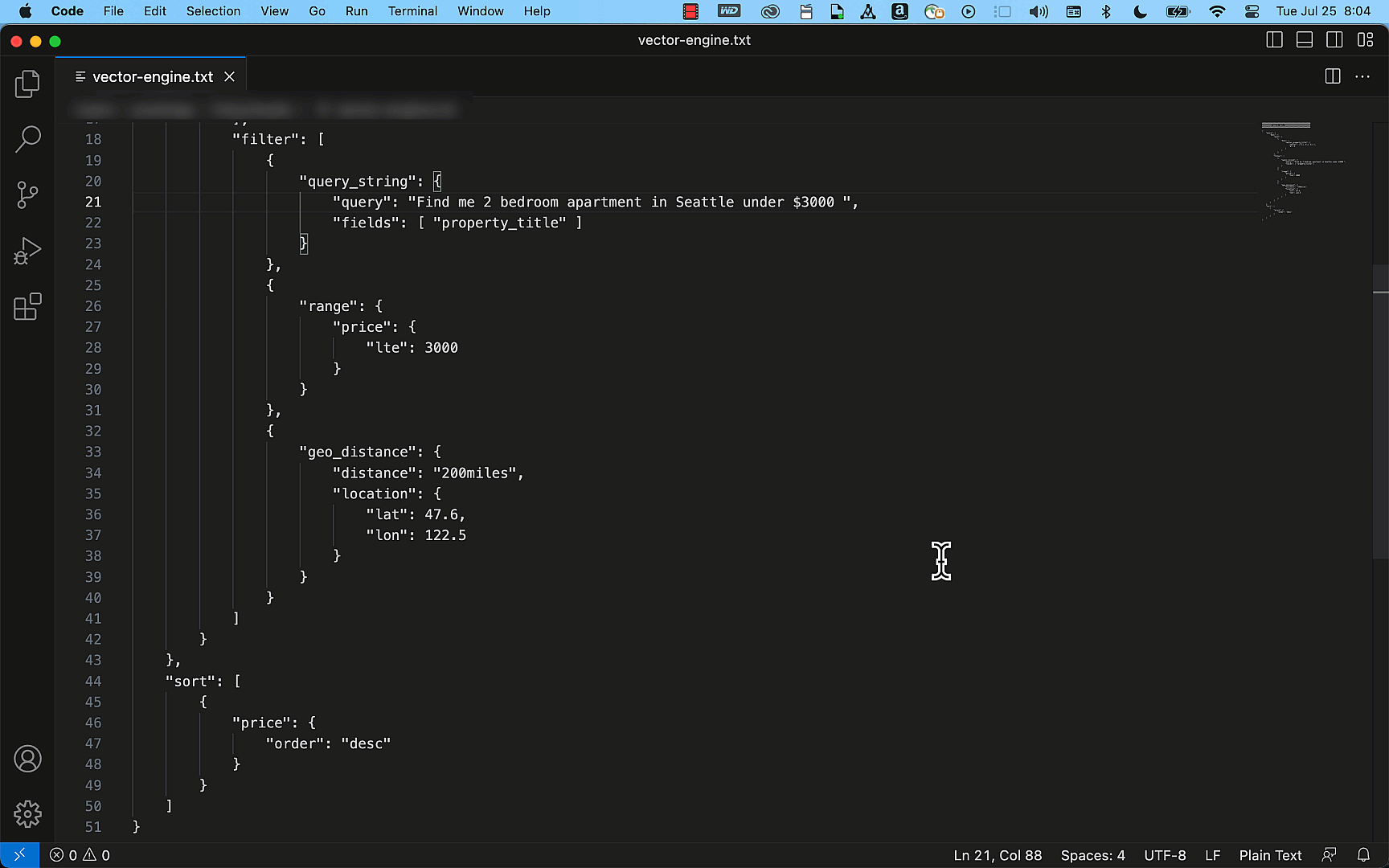
From preview to GA and past
Immediately, we’re excited to announce the preview of the vector engine, making it accessible so that you can start testing it out instantly. As we famous earlier, OpenSearch Serverless was designed to offer a extremely accessible service to energy your enterprise purposes, with unbiased compute sources for index and search and built-in redundancy.
We acknowledge that a lot of you might be within the experimentation section and would love a extra economical possibility for dev-test. Previous to GA, we plan to supply two options that may allow us to cut back the price of your first assortment. The primary is a brand new dev-test possibility that lets you launch a group with no lively standby or reproduction, decreasing the entry value by 50%. The vector engine nonetheless offers sturdiness ensures as a result of it persists all the info in Amazon S3. The second is to initially provision a 0.5 OCU footprint, which can scale up as wanted to help your workload, additional decreasing prices in case your preliminary workload is within the tens of 1000’s to low-hundreds of 1000’s of vectors (relying on the variety of dimensions). Between these two options, we are going to cut back the minimal OCUs wanted to energy your first assortment from 4 OCUs right down to 1 OCU per hour.
We’re additionally engaged on options that may enable us to attain workload pause and resume capabilities within the coming months, which is especially helpful for the vector engine as a result of many of those use circumstances don’t require steady indexing of the info.
Lastly, we’re diligently targeted on optimizing the efficiency and reminiscence utilization of the vector graphs, together with bettering caching, merging and extra.
Whereas we work on these value reductions, we will probably be providing the primary 1400 OCU-hours per thirty days free on vector collections till the dev-test possibility is made accessible. It will allow you to check the vector engine preview for as much as two weeks each month without charge, primarily based in your workload.
Abstract
The vector engine for OpenSearch Serverless introduces a easy, scalable, and high-performing vector storage and search functionality that makes it simple so that you can rapidly retailer and question billions of vector embeddings generated from quite a lot of ML fashions, akin to these supplied by Amazon Bedrock, with response instances in milliseconds.
The preview launch of vector engine for OpenSearch Serverless is now accessible in eight Areas globally: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Eire).
We’re the excited in regards to the future forward and your suggestions will play a significant position in guiding the progress of this product. We encourage you to check out the vector engine for OpenSearch Serverless and share your use circumstances, questions, and suggestions within the feedback part.
Within the coming weeks, we will probably be publishing a sequence of posts to offer you detailed steering on tips on how to combine the vector engine with LangChain, Amazon Bedrock, and SageMaker. To study extra in regards to the vector engine’s capabilities, seek advice from our Getting Began with Amazon OpenSearch Serverless documentation
In regards to the authors
 Pavani Baddepudi is a Principal Product Supervisor for Search Providers at AWS and the lead PM for OpenSearch Serverless. Her pursuits embody distributed methods, networking, and safety. When not working, she enjoys mountaineering and exploring new cuisines.
Pavani Baddepudi is a Principal Product Supervisor for Search Providers at AWS and the lead PM for OpenSearch Serverless. Her pursuits embody distributed methods, networking, and safety. When not working, she enjoys mountaineering and exploring new cuisines.
 Carl Meadows is Director of Product Administration at AWS and is chargeable for Amazon Elasticsearch Service, OpenSearch, Open Distro for Elasticsearch, and Amazon CloudSearch. Carl has been with Amazon Elasticsearch Service since earlier than it was launched in 2015. He has an extended historical past of working within the enterprise software program and cloud companies areas. When not working, Carl enjoys making and recording music.
Carl Meadows is Director of Product Administration at AWS and is chargeable for Amazon Elasticsearch Service, OpenSearch, Open Distro for Elasticsearch, and Amazon CloudSearch. Carl has been with Amazon Elasticsearch Service since earlier than it was launched in 2015. He has an extended historical past of working within the enterprise software program and cloud companies areas. When not working, Carl enjoys making and recording music.