
Pretrained massive language fashions aren’t significantly good at responding in concise, coherent sentences out of the field. At a minimal, they must be finetuned with the intention to reply in a selected type. Normal customers anticipate LLMs to reply within the type of a general-purpose “AI assistant,” with well mannered, paragraph-length responses to open-ended queries. Researchers and builders, however, need LLMs to do properly on benchmarks resembling MMLU and BigBench that require a distinct type with a multiple-choice, terse format. How ought to LLMs be instruction finetuned to reply in two utterly completely different types?
Whereas there are various methods to finetune LLMs for general-purpose query answering, one significantly intriguing method is that of supervised finetuning on a small variety of high-quality samples. The current LIMA (“much less is extra for alignment”) examine boldly claimed that general-purpose instruction following may very well be achieved by merely finetuning on 1,000 numerous, high-quality question-answering pairs; a number of different contemporaneous research additionally argue that this sort of “type alignment” might be achieved with a small variety of high-quality samples (e.g. Alpaca, Vicuna, Alpagasus, and Tülü, however see additionally The False Promise of Imitating Proprietary LLMs). All through this weblog publish, we use the time period “type alignment” to confer with the overall remark that LLMs might be finetuned on a small variety of samples. Whereas the extra widespread time period “instruction finetuning” can embody approaches like LIMA, it additionally encompasses datasets resembling FLANv2, which accommodates greater than 15 million examples of question-answer pairs extracted from a large swath of conventional NLP datasets and arranged into instruction templates for 1,836 duties.
A key consideration is consider LLM finetuning. The 2 types highlighted above (conversational vs. concise) are evaluated utilizing two utterly completely different approaches. NLP analysis benchmarks resembling MMLU include quick, academic-style questions and anticipate an actual token match. Nonetheless, it’s troublesome to guage the standard and elegance of a mannequin’s responses to extra basic, open-ended questions when utilizing conventional perplexity-based NLP benchmarks. With the arrival of simply accessible high-quality LLMs like LLaMA and ChatGPT, it grew to become potential to guage mannequin high quality by utilizing one other LLM as a decide (e.g. AlpacaEval and MTBench). On this model-based analysis paradigm, an LLM is prompted with an instruction and is requested to guage a pair of corresponding responses. Given the success of low-sample finetuning, we requested whether or not it was potential to optimize for 2 completely different types AND do properly on each perplexity-based and model-based analysis paradigms?
In a paper we offered at a NeurIPS workshop in December, we thought-about the type alignment method from LIMA and examined whether or not a small quantity of high-quality instruction finetuning samples might enhance efficiency on each conventional perplexity-based NLP benchmarks and open-ended, model-based analysis. Regardless of variations between perplexity-based and LLM-based analysis paradigms, we discovered that cautious building of finetuning datasets can increase efficiency on each paradigms.
In our analysis, we finetuned open-source MPT-7B and MPT-30B fashions on instruction finetuning datasets of varied sizes starting from 1k to 60k samples. We discovered that subsets of 1k-6k instruction finetuning samples had been capable of obtain good efficiency on each conventional NLP benchmarks and model-based analysis (aka “LLM-as-a-judge”). Lastly, we discovered that mixing textbook-style and open-ended QA finetuning datasets optimized efficiency on each analysis paradigms.
TLDR
So what do you have to do if you wish to successfully and cheaply “instruction finetune” an LLM?
- Finetune on a small variety of numerous, high-quality samples for type alignment. When instruction finetuning your LLM, ensure that to incorporate numerous samples with completely different types and from completely different sources that additionally match your analysis paradigm. For instance, we discovered it significantly useful to mix trivia-like a number of selection QA samples (in a mode much like benchmarks like MMLU) with longer, extra open-ended “AI-assistant” type QA examples (that are favored by LLMs “as-a-judge”). We discovered that mixing 2,000 – 6,000 samples was surprisingly efficient on the 7B and 30B mannequin scale.
- Use a number of analysis paradigms. Ensure that to guage your mannequin utilizing each conventional NLP analysis paradigms resembling MMLU in addition to newer paradigms like LLM-as-a-judge.
Doing these two issues will optimize your LLM for normal NLP benchmarks in addition to extra fluid “AI assistant”-like dialog analysis strategies. This work is extensively detailed in our arXiv paper LIMIT: Much less Is Extra for Instruction Tuning Throughout Analysis Paradigms (Jha et al. 2022). For a technical abstract of our experiments, carry on studying!
Technical Deep Dive
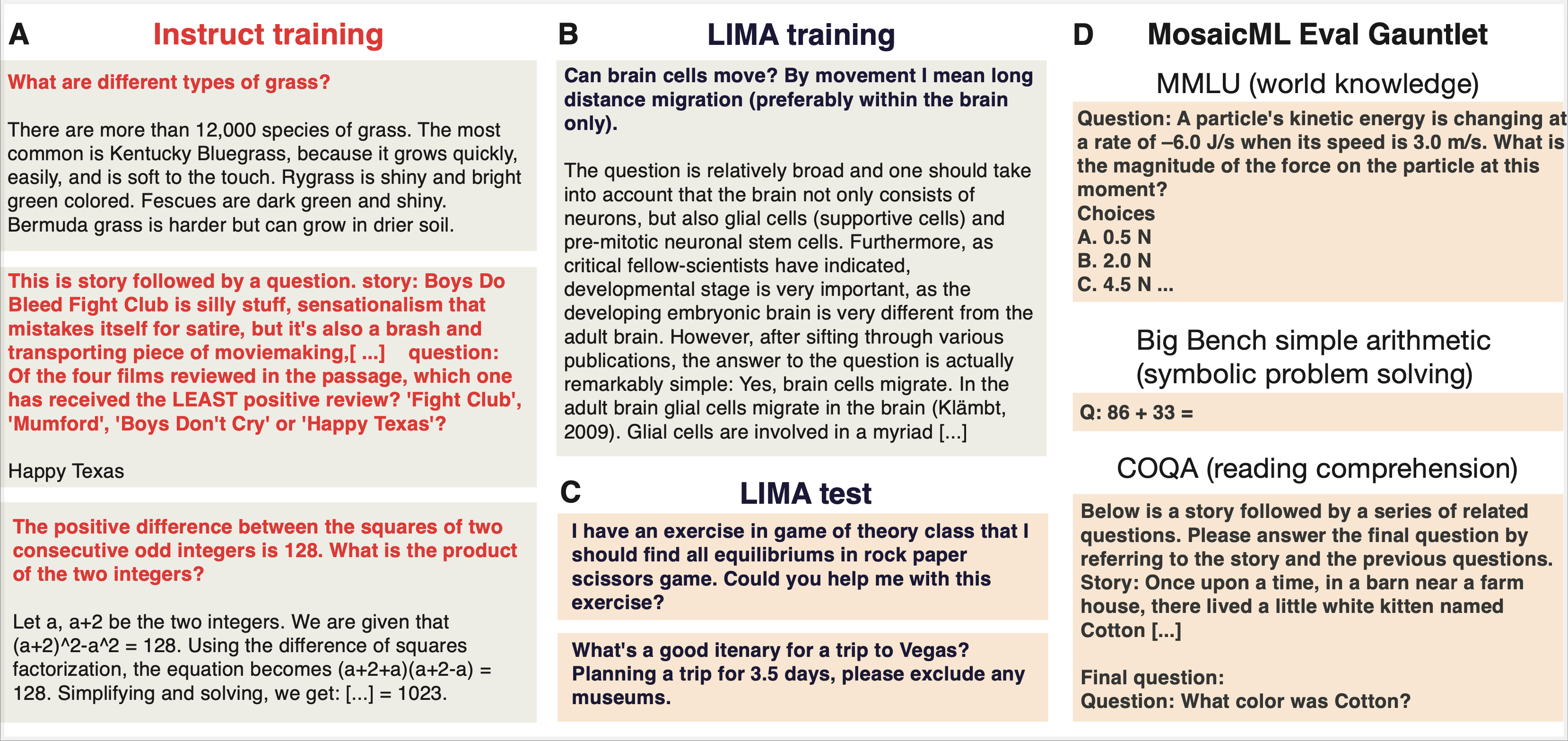
We selected to concentrate on two open-source fashions from the Mosaic MPT household, MPT-7B and MPT-30B, in addition to three open-source instruction tuning datasets: Instruct-v1 (59.3k samples, additionally known as dolly_hhrlhf) and Instruct-v3 (56.2k samples), that are the corresponding instruction finetuning datasets for MPT-7B-Instruct and MPT-30B-Instruct, and the LIMA dataset (1k samples). We consider mannequin efficiency utilizing (1) Mosaic’s environment friendly, open-source Eval Gauntlet, which is predicated on conventional NLP benchmarks resembling MMLU and BIG-bench, in addition to (2) AlpacaEval’s suite for model-based analysis utilizing GPT-4 because the decide.
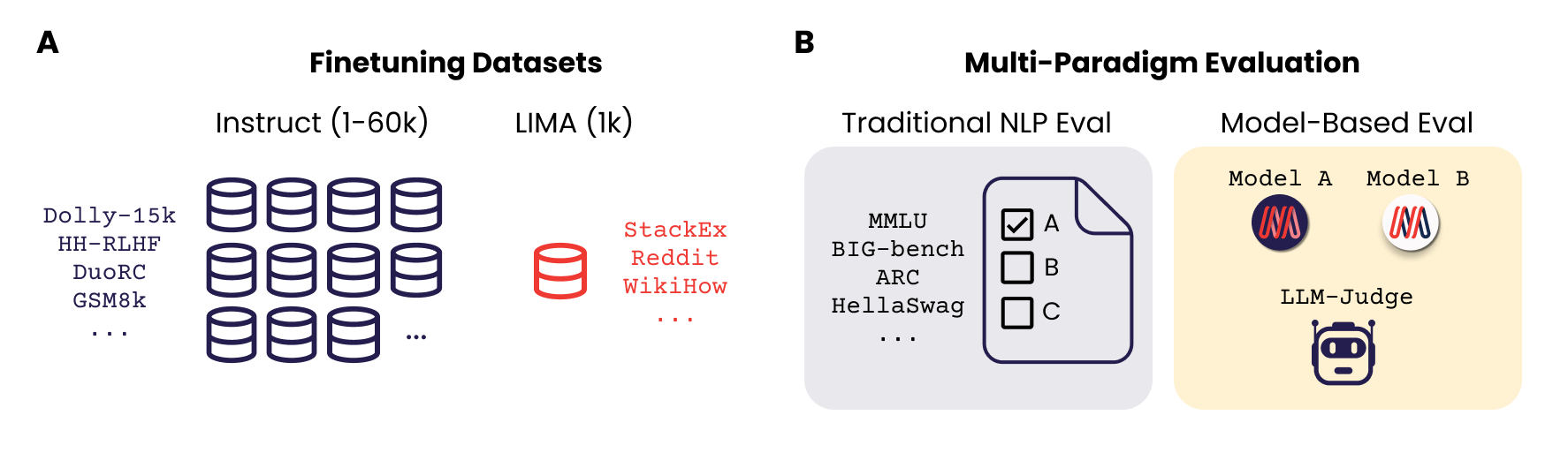
ML practitioners typically use the phrases “finetuning” and “instruction finetuning” interchangeably. Nonetheless, we want to disentangle the concept of introducing new information to a pretrained mannequin by way of finetuning on new information from the method of enabling a base mannequin to do basic query answering by instruction finetuning. There’s ample proof that “extra information is best” with regards to introducing new information to a mannequin. In our work, we had been involved extra particularly with the query of “type alignment” by finetuning on query answering examples with numerous directions.
Instruction Finetuning Datasets
We used three publicly accessible finetuning datasets. The LIMA coaching and check units have high-quality samples of open-ended questions and multi-paragraph solutions written within the tone of a general-purpose AI assistant. The MPT Instruct-v1 and MPT Instruct-v3 coaching (and check units) include trivia-like questions and solutions that are typically shorter than one paragraph. In our paper, we explored the variations between these datasets intimately; every of the three datasets is briefly described beneath.
LIMA Dataset: The LIMA coaching set accommodates 1,000 samples (750,000 tokens) curated from Reddit, Stack Overflow, wikiHow, Tremendous-NaturalInstructions, and examples manually written by the paper authors. The examples had been chosen after strict filtering to make sure variety and high quality. LIMA’s authors sampled an equal variety of prompts from numerous classes inside StackExchange (programming, math, English, cooking, and many others.) and chosen the highest reply for every immediate, which then went by further filtering primarily based on size and writing type. On this examine, we solely used the single-turn examples.
You may get a way of what sort of questions and responses are on this dataset by a clustered model maintained by Lilac AI. Looking this dataset reveals inventive writing prompts, resembling “Write a poem from the angle of a canine,” advertising questions resembling “Tips on how to make your LinkedIn profile stand out?” in addition to programming questions, relationship recommendation, health and wellness ideas, and many others. A lot of the curated responses span a number of paragraphs.
MPT Instruct-v1 Dataset (a.okay.a “Dolly-HHRLHF”): This coaching set was used to coach the MPT-7BInstruct mannequin. The MPT Instruct-v1 dataset accommodates the Databricks Dolly-15k dataset and a curated subset of Anthropic’s Useful and Innocent (HH-RLHF) datasets, each of that are open supply and commercially licensed. Mosaic’s MPT-7B-Instruct mannequin was finetuned utilizing this dataset. It accommodates 59.3k examples; 15k are derived from Dolly-15k and the remainder are from Anthropic’s HH-RLHF dataset. Dolly-15k accommodates a number of courses of prompts together with classification, closed-book query answering, era, data extraction, open QA, and summarization. Anthropic’s HH-RLHF dataset accommodates crowd-sourced conversations of employees with Anthropic’s LLMs. Solely the primary flip of multi-turn conversations was used, and chosen samples had been restricted to be useful and instruction-following in nature (versus dangerous).
MPT Instruct-v3 Dataset: This coaching set was used to coach the MPT-30B-Instruct mannequin. It accommodates a filtered subset of MPT Instruct-v1, in addition to a number of different publicly accessible datasets: Competitors Math, DuoRC, CoT GSM8k, Qasper, SQuALITY, Summ Display screen FD and Spider. Because of this, Instruct-v3 has a lot of studying comprehension examples, the place the directions include a protracted passage of textual content adopted by questions associated to the textual content (derived from DuoRC, Qasper, Summ Display screen FD, SQuALITY). It additionally accommodates math issues derived from CompetitionMath and CoT GSM8K, in addition to text-to-SQL prompts derived from Spider. Instruct-v3 has a complete of 56.2k samples. Each Instruct-v1 and Instruct-v3 had been purpose-built to enhance efficiency on conventional NLP benchmarks.
You may also get a way of how completely different instruct-v3 is from the LIMA dataset by subject clusters right here. This dataset accommodates hundreds of math issues resembling “Resolve for x: 100^3 = 10^x” in addition to questions on plot summaries, sports activities and leisure trivia, and historical past trivia resembling “What yr did the primary chilly struggle begin?” When skimming by the examples, it’s clear that a number of examples are sometimes included within the directions (i.e. a type of in-context studying) and that right responses are normally shorter than a single sentence.
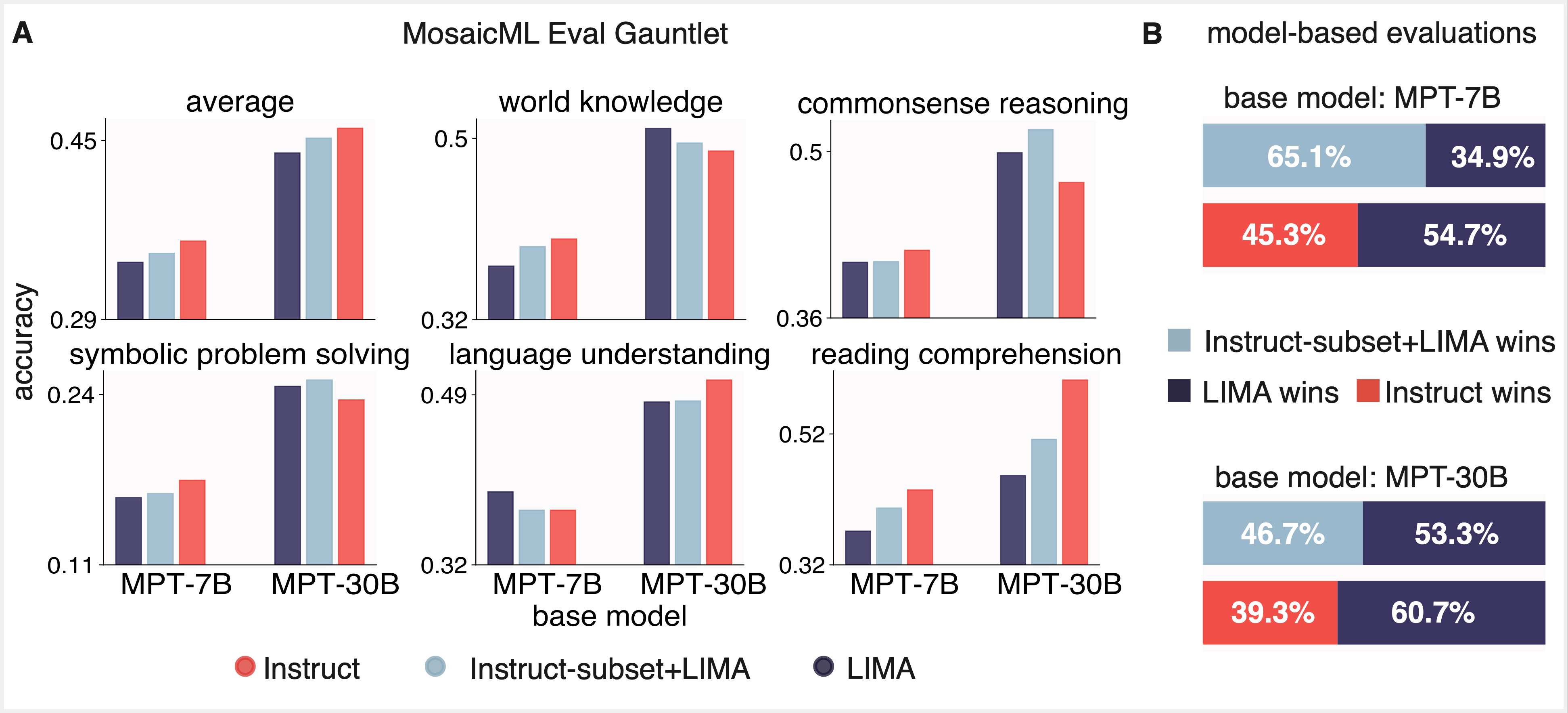
We first requested whether or not LIMA’s 1,000 pattern dataset might ship on its promise: might we finetune a MPT base mannequin on LIMA that delivers optimum efficiency on conventional NLP benchmarks AND performs properly when evaluated by an LLM? We finetuned MPT-7B and MPT-30B base fashions on LIMA and evaluated the ensuing fashions utilizing Mosaic’s Eval Gauntlet in addition to AlpacaEval’s model-based analysis suite with GPT-4 because the “decide” (Figures 3 and 4). Whereas the ensuing fashions had been judged favorably by GPT-4, we discovered that they didn’t carry out on par with MPT-7B and MPT-30B skilled on a lot bigger instruction finetuning datasets (Instruct-v1 and Instruct-v3, respectively).
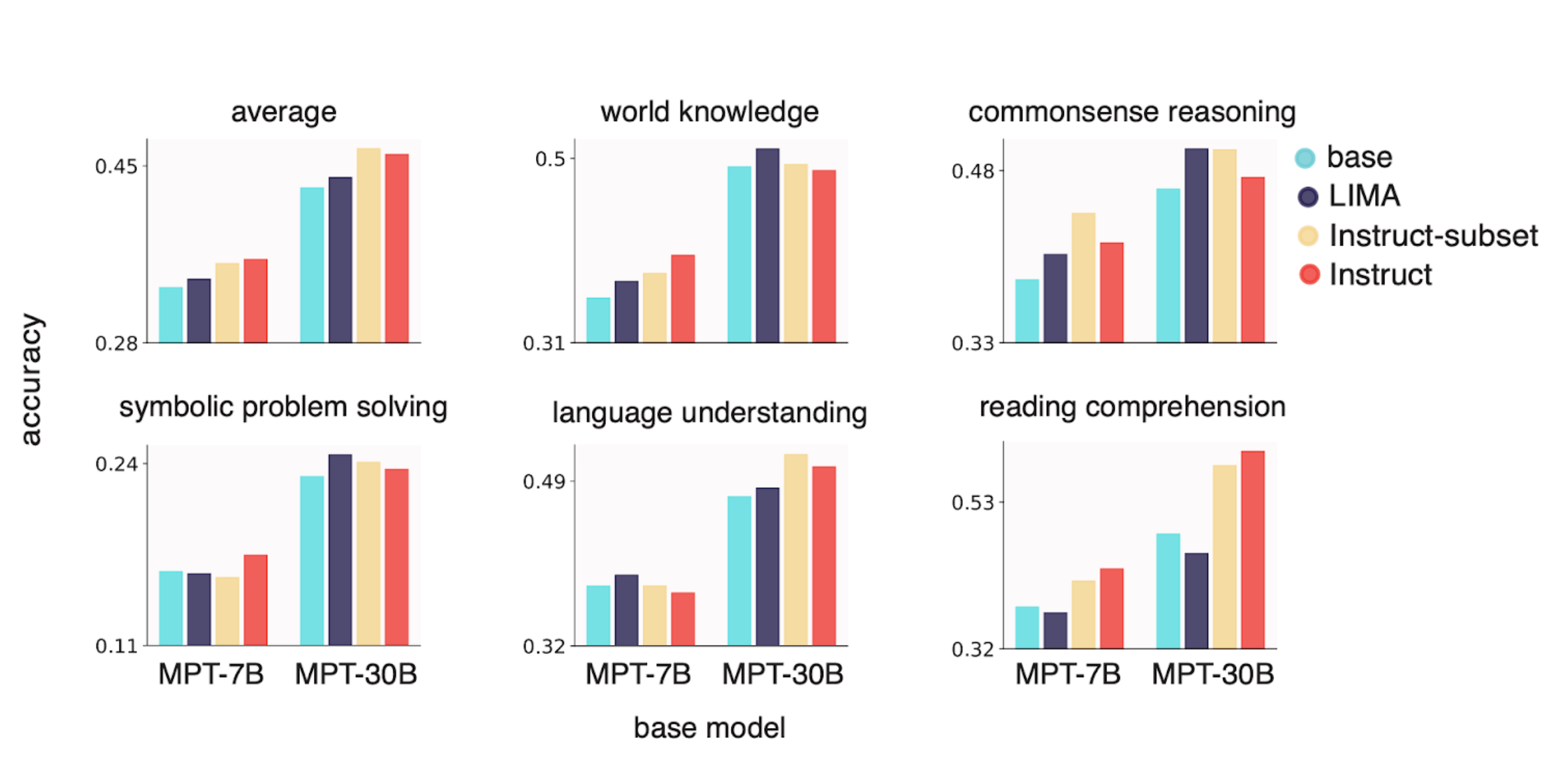
We suspected that the LIMA dataset was barely out-of-domain with respect to MMLU and BIGbench, so we investigated whether or not a random subset of 1,000-5,000 “in-domain” samples from Instruct-v1 and Instruct-v3 might attain parity on the Eval Gauntlet with the total datasets. We had been pleasantly shocked to seek out that this small subset of finetuning information had related efficiency on the Eval Gauntlet, corroborating the overall small-sample method of LIMA (Determine 3). Nonetheless, these identical fashions did poorly when evaluated by GPT-4 (Determine 4).
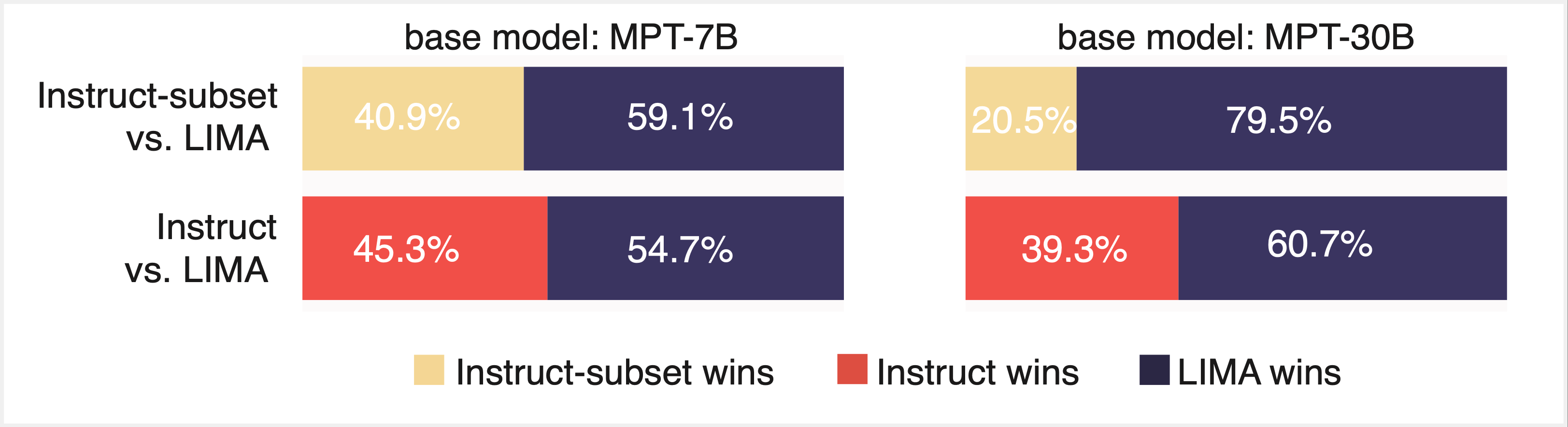
Lastly, we thought-about whether or not we might get the most effective of each worlds—i.e. get good efficiency on each analysis paradigms—by finetuning on a subset of some thousand Instruct and LIMA samples (Determine 5). We discovered that this certainly led to good efficiency throughout each paradigms. Whereas we had been initially skeptical that efficient finetuning may very well be achieved with lower than 1,000 samples, our outcomes replicated LIMA and constructed on the “much less is extra” method to type alignment.
Dialogue
The shift away from instruction finetuning on bigger and bigger datasets was catalyzed by the open-source launch of the LLaMA fashions and by the closed-source launch of GPT-3 and chatGPT. AI researchers rapidly realized that open supply LLMs resembling LLaMA-7B may very well be successfully finetuned on high-quality instruction following information generated by state-of-the-art GPT fashions.
For instance, Alpaca is a 7 billion parameter LLaMa mannequin finetuned on 56,000 examples of question-response samples generated by GPT-3 (text-davinci-003). The authors of this examine discovered that Alpaca responded in an analogous type to the a lot bigger GPT-3 mannequin. Whereas the strategies used within the Alpaca examine had been considerably questionable (the human choice analysis was finished by the 5 authors themselves), additional finetuning research resembling Vicuna, MPT-7B-chat, Tülü, Baize, Falcon-40B arrived at related conclusions. Sadly, outcomes throughout many of those papers are primarily based on completely different analysis paradigms, making them troublesome to check side-by-side.
Thankfully, further analysis has begun to fill out the total image. The Tülü paper “How Far Can Camels Go? Exploring the State of INstruction Tuning on Open Assets” (Wang et al. 2023) argued that finetuned LLMs needs to be examined utilizing conventional fact-recall capabilities with benchmarks like MMLU, together with model-based analysis (utilizing GPT-4) and crowd-sourced human analysis. Each the Tülü and the comply with up Tülü 2 paper discovered that finetuning LLaMA fashions over completely different datasets promotes particular expertise and that nobody dataset improves efficiency over all analysis paradigms.
In “The false promise of imitating proprietary LLMs” (Gudibande et al. 2023), the authors confirmed that whereas finetuning small LLMs with “imitation” information derived from ChatGPT conversations can enhance conversational type, this technique doesn’t result in improved efficiency on conventional fact-based benchmarks like MMLU and Pure Questions. Nonetheless, they did be aware that coaching on GPT-4-derived “imitation” information within the area of Pure-Questions-like queries improves efficiency on the Pure Questions benchmark. Lastly, the “AlpaGasus: Coaching A Higher Alpaca with Fewer Information” (Chen et al. 2023) and “Changing into self-instruct: introducing early stopping standards for minimal instruct tuning” (AlShikh et al. 2023) straight addressed the query of what number of finetuning examples are needed for good downstream efficiency. Our outcomes align properly with the above research.
Acknowledgements and Code
This line of labor was impressed by LIMA in addition to the Tulu papers from AI2 (How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Assets and Camels in a Altering Local weather: Enhancing LM Adaptation with Tulu 2).
All experiments had been finished utilizing Mosaic’s Composer library and llm-foundry repository for LLM coaching in PyTorch 1.13. Extra particulars can be found on our undertaking web site.
Finetuning Datasets
LLM Mannequin Weights
This analysis was led by Aditi Jha and Jacob Portes with recommendation from Alex Trott. Sam Havens led the event of Instruct-v1 and Instruct-v3 datasets, and Jeremy Dohmann developed the Mosaic analysis harness.
Disclaimer
The work detailed on this weblog was carried out for analysis functions, and never for Databricks product improvement.

Redmi 13C 5G (Starlight Black, 4GB RAM, 128GB Storage) | MediaTek Dimensity 6100+ 5G | 90Hz Display
₹10,999.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi Note 13 5G (Arctic White, 6GB RAM, 128GB Storage) | MTK Dimensity 6080 5G | 7.6mm, Slimmest Note Ever
₹17,999.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth in Ear Earphones with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.0(Moon White)
₹999.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt BassHeads 100 in-Ear Wired Headphones with Mic (Black)
₹349.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord Buds 2 TWS in Ear Earbuds with Mic,Upto 25dB ANC 12.4mm Dynamic Titanium Drivers, Playback:Upto 36hr case, 4-Mic Design, IP55 Rating, Fast Charging [Thunder Gray]
₹2,499.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Logitech B170 Wireless Mouse, 2.4 GHz with USB Nano Receiver, Optical Tracking, 12-Months Battery Life, Ambidextrous, PC/Mac/Laptop - Black
₹499.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell USB Wireless Keyboard and Mouse Set- KM3322W, Anti-Fade & Spill-Resistant Keys, up to 36 Month Battery Life, 3Y Advance Exchange Warranty, Black
₹1,199.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹299.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
amazon basics Type A to Micro USB Braided Cable | 3A/18W Fast Charging and 480 Mbps Data Transfer Speed | 1.2m, Tangle Free Cable
₹109.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Amazon Basics 128 GB Flash Drive | USB 2.0 E Series | Temperature, Shock and Vibration Resistant | Plastic Body Finish
₹499.00 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 5TB External Hard Drive HDD – USB 3.0 for PC, Mac, PS4, & Xbox - 1-Year Rescue Service (STGX5000400), Black
$129.99 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 2TB Portable External Hard Drive USB 3.0, Black - HDTB520XK3AA
$64.99 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG SSD T7 Portable External Solid State Drive 1TB, Up to USB 3.2 Gen 2, Reliable Storage for Gaming, Students, Professionals, MU-PC1T0T/AM, Gray
$94.99 (as of February 12, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)