

Within the quest for Synthetic Common Intelligence, LLMs and LMMs stand as outstanding instruments, akin to sensible minds, able to various human-like duties. Whereas benchmarks are essential for assessing their capabilities, the panorama is fragmented, with datasets scattered throughout platforms like Google Drive and Dropbox. lm-evaluation-harness units a precedent for LLM analysis, but multimodal mannequin analysis lacks a unified framework. This hole highlights the infancy of multi-modality mannequin analysis, calling for a cohesive strategy to evaluate their efficiency throughout numerous datasets.
Researchers from Nanyang Technological College, College of Wisconsin-Madison, and Bytedance have developed LLaVA-NeXT, a pioneering open-source LMM skilled solely on text-image knowledge. The revolutionary AnyRes approach enhances reasoning, Optical Character Recognition (OCR), and world information, showcasing distinctive efficiency throughout numerous image-based multimodal duties. Surpassing Gemini-Professional on benchmarks like MMMU and MathVista, LLaVA-NeXT signifies a major leap in multimodal understanding capabilities.
Venturing into video comprehension, LLaVA-NeXT unexpectedly reveals strong efficiency, that includes key enhancements. Leveraging AnyRes, it achieves zero-shot video illustration, displaying unprecedented modality switch capability for LMMs. The mannequin’s size generalization functionality successfully handles longer movies, surpassing token size constraints via linear scaling methods. Additional, supervised fine-tuning (SFT) and direct choice optimization (DPO) improve the video understanding prowess. On the identical time, environment friendly deployment through SGLang allows 5x quicker inference, facilitating scalable functions like million-level video re-captioning. LLaVA-NeXT’s feats underscore its state-of-the-art efficiency and flexibility throughout multimodal duties, rivaling proprietary fashions like Gemini-Professional on key benchmarks.
The AnyRes algorithm in LLaVA-NeXT is a versatile framework that effectively processes high-resolution photos. It segments photos into sub-images utilizing completely different grid configurations to attain optimum efficiency whereas assembly the token size constraints of the underlying LLM structure. With changes, it can be used for video processing, however token allocation per body must be rigorously thought of to keep away from exceeding token limits. Spatial pooling methods optimize token distribution, balancing body rely and token density. Nevertheless, successfully capturing complete video content material stays difficult when rising the body rely.
Addressing the necessity to course of longer video sequences, LLaVA-NeXT implements size generalization methods impressed by latest developments in dealing with lengthy sequences in LLMs. The mannequin can accommodate longer sequences by scaling the utmost token size capability, enhancing its applicability in analyzing prolonged video content material, and using DPO leverages LLM-generated suggestions to coach LLaVA-NeXT-Video, leading to substantial efficiency positive factors. This strategy provides an economical different to buying human choice knowledge and showcases promising prospects for refining coaching methodologies in multimodal contexts.
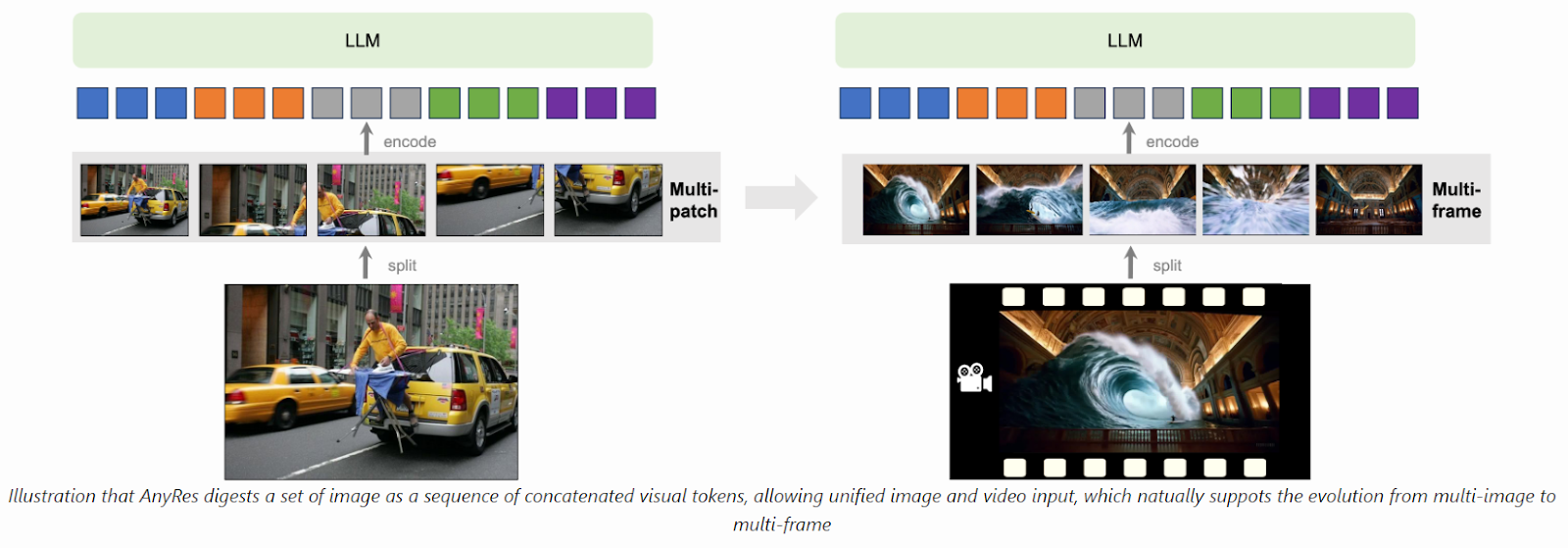
In conclusion, To successfully symbolize movies throughout the constraints of the LLM, the researchers discovered an optimum configuration: allocating 12×12 tokens per body, sampling 16 frames per video, and leveraging “linear scaling” methods to additional Superb-tuningilities, permitting for longer sequences of inference tokens. Superb-tuning LLaVA-NeXT-Video includes a blended coaching strategy with video and picture knowledge. Mixing knowledge varieties inside batches yields the perfect efficiency, highlighting the importance of incorporating picture and video knowledge throughout coaching to reinforce the mannequin’s proficiency in video-related duties.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.

boAt Airdopes 207 TWS Earbuds with 50 hrs Playtime, Quad Mics with ENx Tech, ASAP Charging, IWP Tech, Beast Mode with 50 ms Low Latency, Bluetooth v5.3, USB Type-C Port & IPX5(Bold Blue)
₹899.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme NARZO 70x 5G (Forest Green, 6GB RAM,128GB Storage| 120Hz Ultra Smooth Display | Dimensity 6100+ 6nm 5G | 50MP AI Camera | 45W Charger in The Box
₹13,499.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Noise Newly Launched Buds N1 in-Ear Truly Wireless Earbuds with Chrome Finish, 40H of Playtime, Quad Mic with ENC, Ultra Low Latency(up to 40 ms), Instacharge(10 min=120 min), BT v5.3(Forest Green)
₹1,299.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
amazon basics True Wireless in-Ear Earbuds with Mic, Low-Latency Gaming Mode, Touch Control, IPX5 Water-Resistance, Bluetooth 5.3, Up to 60 Hours Play Time, Voice Assistance and Fast Charging (White)
₹999.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Samsung Galaxy M34 5G (Waterfall Blue,6GB,128GB)|120Hz sAMOLED Display|50MP Triple No Shake Cam|6000 mAh Battery|4 Gen OS Upgrade & 5 Year Security Update|12GB RAM with RAM+|Android 13|Without Charger
₹13,999.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹667.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Callas Multipurpose Foldable Laptop Table with Cup Holder | Drawer | Mac Holder | Study Table, Breakfast Table, Foldable and Portable/Ergonomic & Rounded Edges/Non-Slip Legs (WA-27-Black) | Metal
₹497.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Rellon Industries Study Table for Students Bed Table for Study Foldable Laptop Table Portable & Lightweight Mini Table Bed Reading Table,Laptop Stands, Laptop Desk (A1)
₹599.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive,
₹429.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Mpad Mouse Mat 230X190X3mm Gaming Mouse Pad, Non-Slip Rubber Base, Waterproof Surface, Premium-Textured, Compatible with Laser and Optical Mice(Universe Black)
₹99.00 (as of May 14, 2024 14:12 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)Auto Amazon Links: No products found.