

Massive Language Fashions (LLMs) have grow to be more and more pivotal within the burgeoning discipline of synthetic intelligence, particularly in knowledge administration. These fashions, that are primarily based on superior machine studying algorithms, have the potential to streamline and improve knowledge processing duties considerably. Nevertheless, integrating LLMs into repetitive knowledge era pipelines is difficult, primarily on account of their unpredictable nature and the potential of vital output errors.
Operationalizing LLMs for large-scale knowledge era duties is fraught with complexities. For example, in capabilities like producing customized content material primarily based on person knowledge, LLMs would possibly carry out extremely in a couple of instances but additionally threat inflicting incorrect or inappropriate content material. This inconsistency can result in vital points, notably when LLM outputs are utilized in delicate or essential functions.
Managing LLMs inside knowledge pipelines has relied closely on guide interventions and fundamental validation strategies. Builders face substantial challenges in predicting all potential failure modes of LLMs. This problem results in an over-reliance on fundamental frameworks incorporating rudimentary assertions to filter out inaccurate knowledge. These assertions, whereas helpful, have to be extra complete to catch all sorts of errors, leaving gaps within the knowledge validation course of.
The introduction of Spade, a way for synthesizing assertions in LLM pipelines by researchers from UC Berkeley, HKUST, LangChain, and Columbia College, considerably advances this space. Spade addresses the core challenges in LLM reliability and accuracy by innovatively synthesizing and filtering assertions, guaranteeing high-quality knowledge era in numerous functions. It capabilities by analyzing the variations between consecutive variations of LLM prompts, which regularly point out particular failure modes of the LLMs. Based mostly on this evaluation, spade synthesizes Python capabilities as candidate assertions. These capabilities are then meticulously filtered to make sure minimal redundancy and most accuracy, addressing the complexities of LLM-generated knowledge.
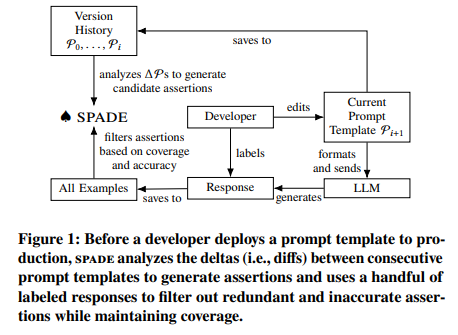
Spade’s methodology includes producing candidate assertions primarily based on immediate deltas – the variations between consecutive immediate variations. These deltas usually point out particular failure modes that LLMs would possibly encounter. For instance, an adjustment in a immediate to keep away from complicated language would possibly necessitate an assertion to test the response’s complexity. As soon as these candidate assertions are generated, they bear a rigorous filtering course of. This course of goals to scale back redundancy, which regularly stems from repeated refinements to related parts of a immediate, and to boost accuracy, notably in assertions involving complicated LLM calls.
In sensible functions, throughout numerous LLM pipelines, it has considerably diminished the variety of mandatory assertions and decreased the speed of false failures. That is evident in its means to scale back the variety of assertions by 14% and reduce false failures by 21% in comparison with easier baseline strategies. These outcomes spotlight Spade’s functionality to boost the reliability and accuracy of LLM outputs in knowledge era duties, making it a beneficial instrument in knowledge administration.

In abstract, the next factors can offered on the analysis carried out:
- Spade represents a breakthrough in managing LLMs in knowledge pipelines, addressing the unpredictability and error potential in LLM outputs.
- It generates and filters assertions primarily based on immediate deltas, guaranteeing minimal redundancy and most accuracy.
- The instrument has considerably diminished the variety of mandatory assertions and the speed of false failures in numerous LLM pipelines.
- Its introduction is a testomony to the continuing developments in AI, notably in enhancing the effectivity and reliability of information era and processing duties.
This complete overview of Spade underscores its significance within the evolving panorama of AI and knowledge administration. Spade ensures high-quality knowledge era by addressing the elemental challenges related to LLMs. It simplifies the operational complexities related to these fashions, paving the way in which for his or her more practical and widespread use.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
Hiya, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m obsessed with know-how and wish to create new merchandise that make a distinction.

OnePlus 12 (Flowy Emerald, 16 GB RAM, 512GB)
₹69,999.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes 141 Bluetooth TWS Earbuds with 42H Playtime,Low Latency Mode for Gaming, ENx Tech, IWP, IPX4 Water Resistance, Smooth Touch Controls(Bold Black)
₹1,299.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C (Starfrost White, 4GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹8,999.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Samsung Original 25W Single Port, Type-C Fast Charger, (Cable not Included), White
₹1,299.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme Buds T300 Truly Wireless in-Ear Earbuds with 30dB ANC, 360° Spatial Audio Effect, 12.4mm Dynamic Bass Boost Driver with Dolby Atmos Support, Upto 40Hrs Battery and Fast Charging (Stylish Black)
₹2,299.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹299.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L 1.2M POR-1401 Fast Charging 3A 8 Pin USB Cable with Charge & Sync Function (White)
₹129.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Duracell USB Type C, 3A Braided Sync & Quick Charging Cable, 3.9 Feet (1.2M), QC 2.0/3.0, Compatible with Samsung, MI, Realme & all C type devices, Rapid Data Transmission, Series 1, Black
₹229.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000Dpi, Led Tracking, Scrolling Wheel, Plug and Play
₹269.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toysbuddy Re-Writable LCD Writing Tablet Pad with Screen 21.5cm (8.5Inch) for Drawing, Playing, Handwriting Best Birthday Gifts for Adults & Kids Girls Boys, Multicolor
₹99.00 (as of January 31, 2024 00:36 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Graphics Card GPU Brace Support, Video Card Sag Holder Bracket, GPU Stand, L
$9.99 (as of January 28, 2024 21:00 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ARCTIC MX-6 (8 g) - Ultimate Performance Thermal Paste for CPU, Consoles, Graphics Cards, laptops, Very high Thermal Conductivity, Long Durability, Non-Conductive, CPU Thermal Paste
$10.99 (as of January 28, 2024 21:00 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair VENGEANCE LPX DDR4 RAM 32GB (2x16GB) 3200MHz CL16 Intel XMP 2.0 Computer Memory - Black (CMK32GX4M2E3200C16)
$77.99 (as of January 28, 2024 21:00 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
NOLYTH External CD DVD Drive, USB 3.0 Type-C CD/DVD Player Burner Writer Reader with SD/TF Slot Slim CD Disc Drive for Laptop PC Mac Windows MacBook Air Pro Desktop iMac
$19.99 (as of January 28, 2024 21:00 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)