

On this weblog submit, we focus on Nice-Grained RLHF, a framework that allows coaching and studying from reward features which can be fine-grained in two other ways: density and variety. Density is achieved by offering a reward after each phase (e.g., a sentence) is generated. Range is achieved by incorporating a number of reward fashions related to completely different suggestions varieties (e.g., factual incorrectness, irrelevance, and data incompleteness).
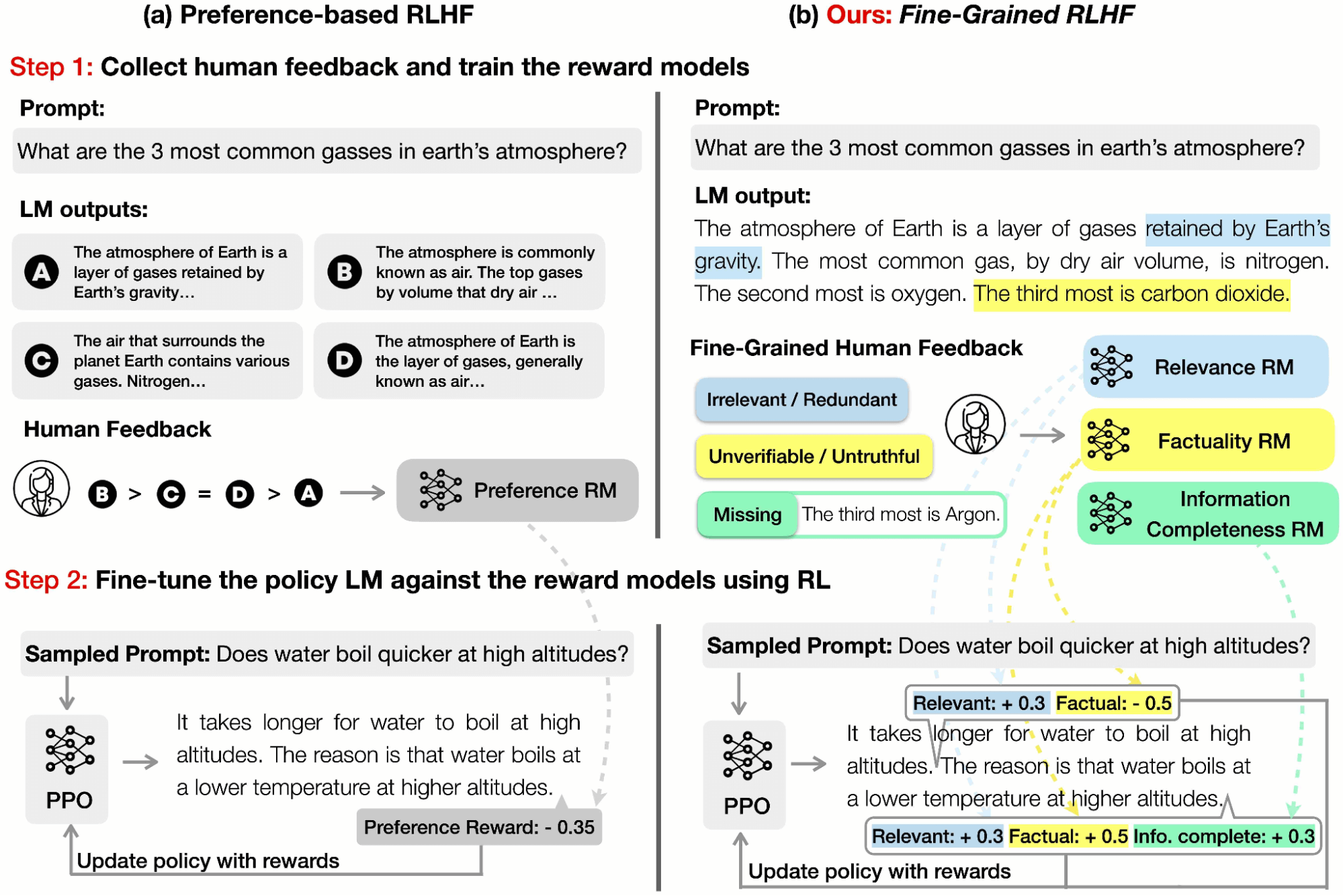
What are Nice-Grained Rewards?
Prior work in RLHF has been centered on accumulating human preferences on the general high quality of language mannequin (LM) outputs. Nonetheless, this sort of holistic suggestions affords restricted data. In a paper we introduced at NeurIPS 2023, we launched the idea of fine-grained human suggestions (e.g., which sub-sentence is irrelevant, which sentence shouldn’t be truthful, which sentence is poisonous) as an express coaching sign.
A reward operate in RLHF is a mannequin that takes in a chunk of textual content and outputs a rating indicating how “good” that piece of textual content is. As seen within the determine above, historically, holistic preference-based RLHF would offer a single reward for your complete piece of textual content with the definition of “good” having no explicit nuance or variety.
In distinction, our rewards are fine-grained in two facets:
(a) Density: We supplied a reward after every phase (e.g., a sentence) is generated, just like OpenAI’s “step-by-step course of reward”. We discovered that this method is extra informative than holistic suggestions and, thus, simpler for reinforcement studying (RL).
(b) Range: We employed a number of reward fashions to seize several types of suggestions (e.g., factual inaccuracy, irrelevance, and data incompleteness). A number of reward fashions are related to completely different suggestions varieties; apparently, we noticed that these reward fashions each complement and compete with one another. By adjusting the weights of the reward fashions, we may management the steadiness between the several types of suggestions and tailor the LM for various duties in line with particular wants. As an illustration, some customers could desire brief and concise outputs, whereas others could search longer and extra detailed responses.
Human suggestions obtained anecdotally from human annotators was that labeling knowledge in fine-grained type was simpler than utilizing holistic preferences. The doubtless purpose for that is that judgments are localized as a substitute of unfold out over massive generations. This reduces the cognitive load on the human annotator and ends in desire knowledge that’s cleaner, with greater inter-annotator settlement. In different phrases, you are prone to get extra prime quality knowledge per unit value with fine-grained suggestions than holistic preferences.
We performed two main case research of duties to check the effectiveness of our technique.
Job 1: Cleansing
The duty of cleansing goals to cut back the toxicity within the mannequin technology. We used Perspective API to measure toxicity. It returns a toxicity worth between 0 (not poisonous) and 1 (poisonous).
We in contrast two sorts of rewards:

(a) Holistic Rewards for (non-)Toxicity: We use 1-Perspective(y) because the reward
(b) Sentence-level (Nice-Grained) Rewards for (non-)Toxicity: We question the API after the mannequin generates every sentence as a substitute of producing the total sequence. For every generated sentence, we use -Δ(Perspective(y)) because the reward for the sentence (i.e. how a lot toxicity is modified from producing the present sentence).
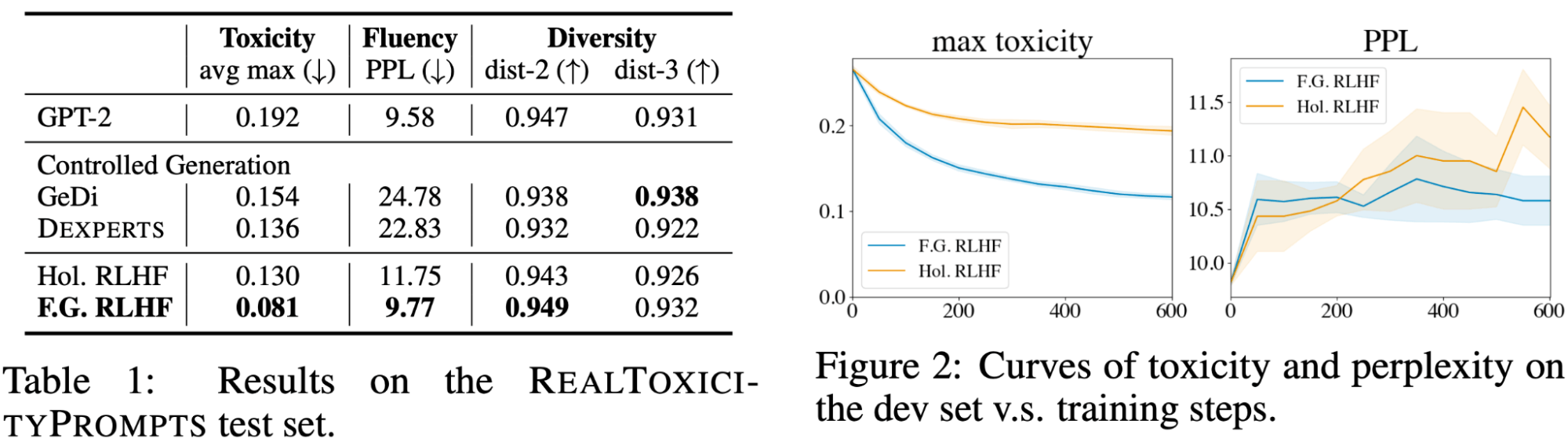
Desk 1 reveals that Our Nice-Grained RLHF with sentence-level fine-grained reward attains the bottom toxicity and perplexity amongst all strategies, whereas sustaining an analogous degree of variety. Determine 2 reveals that studying from denser fine-grained rewards is extra sample-efficient than holistic rewards. One rationalization is that fine-grained rewards are situated the place the poisonous content material is, which is a stronger coaching sign in contrast with a scalar reward for the entire textual content.
Job 2: Lengthy-Kind Query Answering
We collected QA-Suggestions, a dataset of long-form query answering, with human preferences and fine-grained suggestions. QA-Suggestions is predicated on ASQA, a dataset that focuses on answering ambiguous factoid questions.
There are three forms of fine-grained human suggestions, and we skilled a fine-grained reward mannequin for every of them:
1: irrelevance, repetition, and incoherence (rel.); The reward mannequin has the density degree of sub-sentences; i.e., returns a rating for every sub-sentence. If the sub-sentence is irrelevant, repetitive, or incoherent, the reward is -1; in any other case, the reward is +1.
2: incorrect or unverifiable info (truth.); The reward mannequin has the density degree of sentences; i.e., returns a rating for every sentence. If the sentence has any factual error, the reward is -1; in any other case, the reward is +1.
3: incomplete data (comp.); The reward mannequin checks if the response is full and covers all the data within the reference passages which can be associated to the query. This reward mannequin provides one reward for the entire response.
Nice-Grained Human Analysis
We in contrast our Nice-Grained RLHF towards the next baselines:
SFT: The supervised finetuning mannequin (skilled on 1K coaching examples) that’s used because the preliminary coverage for our RLHF experiments.
Pref. RLHF: The baseline RLHF mannequin that makes use of holistic reward.
SFT-Full: We finetuned LM with human-written responses (supplied by ASQA) of all coaching examples and denoted this mannequin as SFT-Full. Discover that every gold response takes 15 min to annotate (in line with ASQA), which takes for much longer time than our suggestions annotation (6 min).

Human analysis confirmed that our Nice-Grained RLHF outperformed SFT and Choice RLHF on all error varieties and that RLHF (each preference-based and fine-grained) was significantly efficient in decreasing factual errors.
Customizing LM behaviors

By altering the burden of the Relevance reward mannequin and protecting the burden of the opposite two reward fashions mounted, we have been in a position to customise how detailed and prolonged the LM responses could be. In Determine X, we in contrast the outputs of three LMs that have been every skilled with completely different reward mannequin combos.
Nice-Grained reward fashions each complement and compete with one another
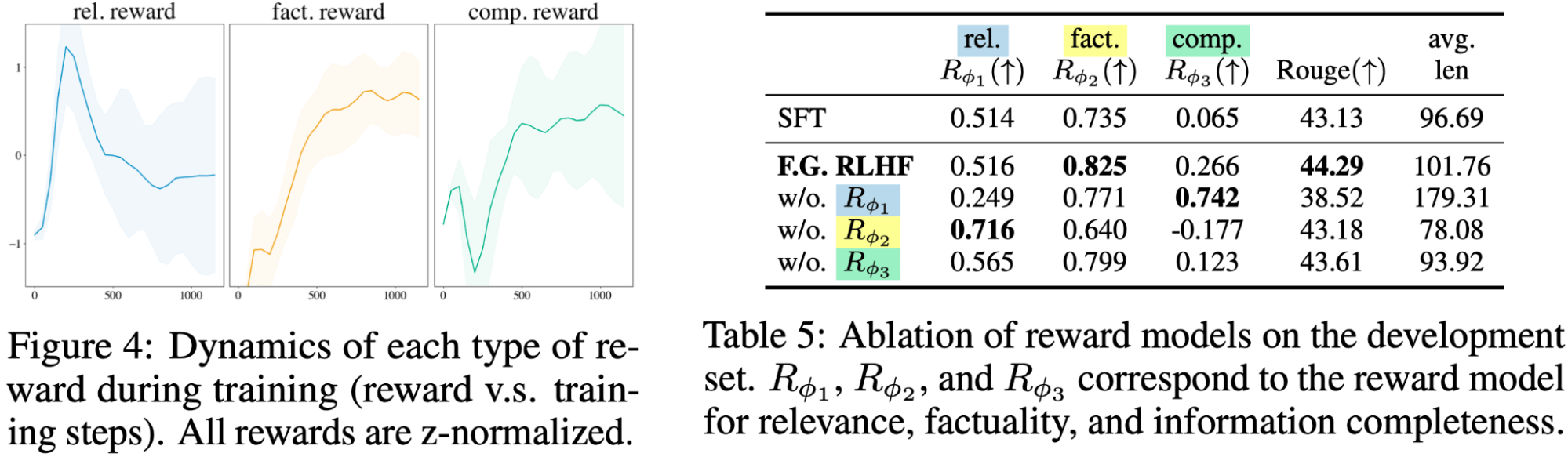
We discovered that there’s a trade-off between the reward fashions: relevance RM prefers shorter and extra concise responses, whereas Data Completeness RM prefers longer and extra informative responses. Thus, these two rewards compete towards one another throughout coaching and finally attain a steadiness. In the meantime, Factuality RM constantly improves the factual correctness of the response. Lastly, eradicating any one of many reward fashions will degrade the efficiency.
We hope our demonstration of the effectiveness of fine-grained rewards will encourage different researchers to maneuver away from fundamental holistic preferences as the premise for RLHF and spend extra time exploring the human suggestions element of RLHF. If you need to quote our publication, see beneath; you can too discover extra data right here.
@inproceedings{wu2023finegrained,
title={Nice-Grained Human Suggestions Offers Higher Rewards for Language Mannequin Coaching},
writer={Zeqiu Wu and Yushi Hu and Weijia Shi and Nouha Dziri and Alane Suhr and Prithviraj
Ammanabrolu and Noah A. Smith and Mari Ostendorf and Hannaneh Hajishirzi},
booktitle={Thirty-seventh Convention on Neural Data Processing Techniques (NeurIPS)},
yr={2023},
url={https://openreview.web/discussion board?id=CSbGXyCswu},
}

OnePlus Nord CE 3 Lite 5G (Pastel Lime, 8GB RAM, 128GB Storage)
₹17,249.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes 91 in Ear TWS Earbuds with 45 hrs Playtime, Beast Mode with 50 ms Low Latency, Dual Mics with ENx, ASAP Charge, IWP Tech, IPX4 & Bluetooth v5.3(Active Black)
₹899.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TECNO Spark Go 2024 (Gravity Black,6GB* RAM, 64GB ROM)| Segment First 90Hz Dot-in Display with Dynamic Port & Dual Speakers with DTS| 5000mAh| 10W Type-C| Fingerprint Sensor| Octa-Core Processor
₹6,799.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹179.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Newly Launched Rockerz 255 ANC Bluetooth Neckband w/ 100 HRS Playback, Spatial Audio, 32dB ANC, ASAP Charge(10Mins=24HRS), 3 Mics AI ENx Tech,13mm Drivers & Dual EQ Modes(Raven Black)
₹1,899.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹299.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Immortal 141 TWS Gaming in Ear Earbuds with Enx Tech,Up to 40 Hrs Playtime,Signature Sound,Beast Mode,Ipx4 Resistance,Iwp Tech,RBG Lights,&USB Type-C Port(Black Sabre)
₹899.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Wayona Nylon Braided USB to Lightning Fast Charging and Data Sync Cable Compatible for iPhone 13, 12,11, X, 8, 7, 6, 5, iPad Air, Pro, Mini (3 FT Pack of 1, Grey)
₹399.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics Zeb-Power Wired USB Mouse, 3-Button, 1200 DPI Optical Sensor, Plug & Play, for Windows/Mac
₹139.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ARCTIC MX-6 (4 g) - Ultimate Performance Thermal Paste for CPU, Consoles, Graphics Cards, laptops, Very high Thermal Conductivity, Long Durability, Non-Conductive, CPU Thermal Paste
$6.15 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 2TB Portable External Hard Drive USB 3.0, Black - HDTB520XK3AA
$64.83 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Western Digital 2TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0020BBK-WESN
$72.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermal Grizzly Kryonaut, High Performance Thermal Paste for Cooling All Processors, Graphics Cards and Heat Sinks in Computers and Consoles -1.0 Gram
$8.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)