

Within the quickly evolving subject of synthetic intelligence, the “LONG AGENT” strategy emerges as a groundbreaking resolution to a longstanding problem: effectively processing and understanding prolonged texts, a website the place even probably the most subtle fashions like GPT-4 have traditionally stumbled. Developed by a devoted crew at Fudan College, this modern methodology considerably expands the capabilities of language fashions, enabling them to navigate paperwork with as much as 128,000 tokens. This leap is achieved via a novel multi-agent collaboration approach, basically altering the panorama of textual content evaluation.
The essence of “LONG AGENT” lies in its distinctive structure, the place a central chief agent oversees a crew of member brokers, every tasked with a textual content section. This configuration permits for granular evaluation of in depth paperwork, with the chief agent synthesizing inputs from crew members to generate a cohesive understanding of the textual content. Such a mechanism is adept at managing the complexities and nuances of huge datasets, guaranteeing complete evaluation with out the constraints of conventional fashions.
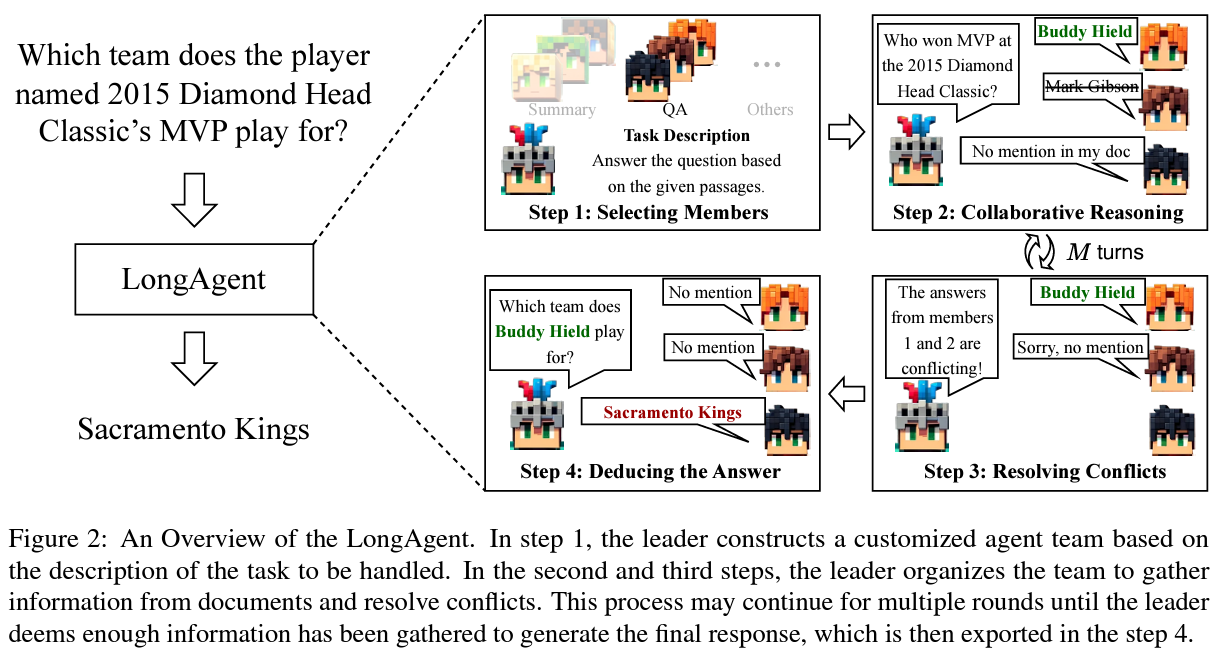
The methodology behind “LONG AGENT” is each intricate and ingenious. Upon receiving a question, the chief divides it into less complicated, manageable sub-queries distributed among the many member brokers. Every member then processes the assigned textual content chunk, reporting findings to the chief. This course of might contain a number of rounds of dialogue, with the chief and members iteratively refining their understanding till a consensus is reached. To handle discrepancies or “hallucinations” — cases the place brokers generate incorrect data not current within the textual content — “LONG AGENT” employs an inter-member communication technique. This entails members sharing their textual content chunks to confirm and proper their responses, guaranteeing the accuracy of the collective output.
Fudan College’s analysis crew has rigorously examined “LONG AGENT” in opposition to benchmark duties, demonstrating its superiority over current fashions. In features like long-text retrieval and multi-hop query answering, “LONG AGENT,” powered by the LLaMA-7B mannequin, has proven outstanding efficiency enhancements. Particularly, within the Needle-in-a-Haystack PLUS take a look at, which assesses fashions’ talents to retrieve data from lengthy texts, “LONG AGENT” achieved an accuracy enchancment of 19.53% over GPT-4 for single-document settings and 4.96% for multi-document settings. These numbers underscore the tactic’s efficacy and spotlight its potential to revolutionize how we work together with and analyze intensive textual content information.
The implications of “LONG AGENT” prolong far past tutorial curiosity, promising substantial advantages for varied purposes. From authorized doc evaluation to complete literature critiques, effectively processing and understanding massive volumes of textual content can considerably improve data retrieval, decision-making processes, and data discovery. As we proceed to generate and accumulate textual content information at an unprecedented price, the demand for such superior processing capabilities will solely develop.
In conclusion, “LONG AGENT” stands as a testomony to the ingenuity and forward-thinking of the researchers at Fudan College. By pushing the boundaries of what’s attainable with language fashions, they’ve opened new avenues for textual content evaluation, setting a brand new commonplace for effectivity and effectiveness. As this know-how continues to evolve, we will anticipate a future the place the depth and breadth of our understanding of textual content information are restricted not by computational constraints however by the extent of our curiosity. The “LONG AGENT” strategy, with its potential to navigate the complexities of in depth paperwork, is not only a milestone in synthetic intelligence analysis however a beacon for future explorations within the huge ocean of textual content information.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
You might also like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a concentrate on Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

OnePlus Buds 3 in Ear TWS Bluetooth Earbuds with Upto 49dB Smart Adaptive Noise Cancellation,Hi-Res Sound Quality,Sliding Volume Control,10mins for 7Hours Fast Charging with Upto 44Hrs Playback
₹5,499.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Bullets Z2 Bluetooth Wireless in Ear Earphones with Mic, Bombastic Bass - 12.4 Mm Drivers, 10 Mins Charge - 20 Hrs Music, 30 Hrs Battery Life (Magico Black)
₹1,799.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple iPhone 13 (128GB) - Starlight
₹49,300.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus 12R (Iron Gray, 8GB RAM, 128GB Storage)
₹39,999.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple 20W USB-C Power Adapter (for iPhone, iPad & AirPods)
₹1,599.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP X1000 Wired USB Mouse with 3 Handy Buttons, Fast-Moving Scroll Wheel and Optical Sensor works on most Surfaces, 3 years warranty
₹279.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS Zeb-Dash Plus 2.4GHz High Precision Wireless Mouse with up to 1600 DPI, Power Saving Mode, Nano Receiver and Plug & Play Usage - USB
₹203.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 25 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000DPI, LED Tracking, Scrolling Wheel, Plug and Play
₹269.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive, Metal, Silver
₹396.00 (as of February 27, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG SSD T7 Portable External Solid State Drive 2TB, USB 3.2 Gen 2, Reliable Storage for Gaming, Students, Professionals, MU-PC2T0T/AM, Gray
$149.99 (as of February 26, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair Vengeance LPX 16GB (2x8GB) DDR4 DRAM 3200MHz C16 Desktop Memory Kit - Black (CMK16GX4M2B3200C16)
$45.99 (as of February 26, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 5TB External Hard Drive HDD – USB 3.0 for PC, Mac, PS4, & Xbox - 1-Year Rescue Service (STGX5000400), Black
$129.99 (as of February 26, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
2 Pack-Apple Earbuds/iPhone Headphones/Lightning/Wired Earphones [Apple MFi Certified] Built-in Microphone & Volume Control Compatible with iPhone 14/13/12/11/8/Pro Max/X/7, Support All iOS System
$21.98 (as of February 26, 2024 21:13 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)