

The efforts to create fashions that may perceive and course of textual content with human-like accuracy are ongoing in pure language processing. Among the many well-known challenges, one stands out: crafting fashions that may effectively convert huge quantities of textual info right into a kind that machines can perceive and act upon. Textual content embedding fashions serve this goal by remodeling textual content into dense vectors, thereby enabling machines to gauge semantic similarity, classify paperwork, and retrieve info primarily based on content material relevance. Nonetheless, creating such fashions beforehand relied on giant, manually annotated datasets, a time- and resource-intensive course of.
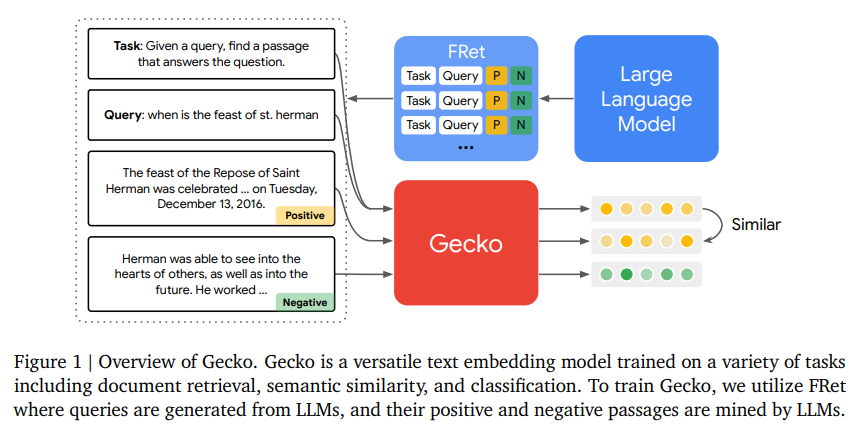
Researchers from Google DeepMind launched Gecko, an modern textual content embedding mannequin. Gecko distinguishes itself by leveraging giant language fashions (LLMs) for data distillation. Not like conventional fashions that depend upon intensive labeled datasets, Gecko initiates its studying course of by producing artificial paired knowledge by way of an LLM. This preliminary step produces a broad vary of query-passage pairs that lay the groundwork for a various and complete coaching dataset.
The crew additional refines the standard of this artificial dataset by using the LLM to relabel the passages, guaranteeing every question matches probably the most related passage. This relabeling course of is crucial, because it weeds out much less related knowledge and highlights the passages that really resonate with the corresponding queries, a way that conventional fashions, restricted by their datasets, typically fail to attain.
When benchmarked on the Huge Textual content Embedding Benchmark (MTEB), it demonstrated distinctive efficiency, outpacing fashions with bigger embedding sizes. Gecko with 256 embedding dimensions outperformed all entries with 768 embedding sizes, and when expanded to 768 dimensions, it scored a mean of 66.31. These figures are notably spectacular, contemplating Gecko competes towards fashions seven instances its measurement and with embedding dimensions 5 instances larger.

Gecko’s foremost breakthrough lies in FRet, an artificial dataset ingeniously crafted utilizing LLMs. This dataset emerges from a two-tiered course of by which LLMs first generate a broad spectrum of query-passage pairs, simulating numerous retrieval situations. These pairs are then refined, with passages relabeled for accuracy, guaranteeing every question aligns with probably the most related passage. FRet leverages the huge data inside LLMs to provide a various and exactly tailor-made dataset for superior language understanding duties.

In conclusion, Gecko’s growth marks a notable development in using LLMs to generate and refine its coaching dataset. It cuts the constraints of conventional dataset dependencies and units a brand new benchmark for the effectivity and flexibility of textual content embedding fashions. The mannequin’s distinctive efficiency on the MTEB, coupled with its modern method to knowledge era and refinement, underscores the potential of LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 39k+ ML SubReddit
Whats up, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m obsessed with expertise and need to create new merchandise that make a distinction.

Noise Newly Launched Buds N1 in-Ear Truly Wireless Earbuds with Chrome Finish, 40H of Playtime, Quad Mic with ENC, Ultra Low Latency(up to 40 ms), Instacharge(10 min=120 min), BT v5.3(Carbon Black)
₹1,299.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹296.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Boult Audio [Just Launched] UFO True Wireless in Ear Earbuds with 48H Playtime, Built-in App Support, 4 Mics Clear Calling, Low Latency Gaming, Made in India Bluetooth 5.3 TWS Ear Buds (White Opal)
₹1,499.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Samsung Original 25W Single Port, Type-C Fast Charger, (Cable not Included), White
₹1,299.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme NARZO 70 Pro 5G (Glass Green, 8GB RAM,128GB Storage) Dimensity 7050 5G Chipset | Horizon Glass Design | Segment 1st Flagship Sony IMX890 OIS Camera
₹19,999.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics-NS1500 Laptop Stand Featuring Foldable Design, Anti-Slip Silicone Rubber Pads, Supports Maximum of 5kgs Weight Tabletop
₹299.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dyazo 6 Angles Adjustable Aluminum Ergonomic Foldable Portable Tabletop Laptop/Desktop Riser Stand Holder Compatible for MacBook, HP, Dell, Lenovo & All Other Notebook (Silver)
₹399.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹296.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,399.00 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
UnionSine 1TB Ultra Slim Portable External Hard Drive HDD-USB 3.0 for PC, Mac, Laptop, PS4, Xbox one,Xbox 360-Super Fast Transmission-HD-2510(Black)
$52.19 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CORSAIR 4000D AIRFLOW Tempered Glass Mid-Tower ATX Case - High-Airflow - Cable Management System - Spacious Interior - Two Included 120 mm Fans - Black
$104.99 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$99.99 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
WD 5TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0050BBK-WESN
$124.99 (as of April 2, 2024 18:52 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)