

Pure Language Processing (NLP) is a cutting-edge discipline that allows machines to know, interpret, & generate human language. It has purposes in numerous domains, equivalent to language translation, textual content summarization, sentiment evaluation, and the event of conversational brokers. Giant language fashions (LLMs) have considerably superior these purposes by leveraging huge information to carry out duties with excessive accuracy, virtually matching human efficiency.
At the moment’s major problem in NLP is the large computational and power calls for required to coach and deploy these LLMs. Their sheer measurement typically limits these fashions, making them costly and fewer accessible to a broader viewers. The excessive computational value and vital power influence limit the usability of those fashions, emphasizing the necessity to scale back the computational footprint with out compromising accuracy. Addressing this problem is essential for making these highly effective instruments extra extensively accessible and sustainable.
Varied strategies have been employed to mitigate these challenges and scale back LLMs’ measurement and computational necessities. Quantization is one method that reduces the variety of bits required to signify every mannequin parameter, whereas pruning entails eradicating much less vital weights to streamline the mannequin. Nevertheless, each strategies face vital hurdles in sustaining excessive accuracy, particularly for complicated duties. Present methods typically wrestle to attain significant compression ratios with out damaging mannequin efficiency, notably at excessive sparsity ranges.
Researchers from Neural Magic, Cerebras Methods, and IST Austria have launched a novel method to create sparse foundational variations of enormous language fashions. They particularly focused the LLaMA-2 7B mannequin, aiming to mix the SparseGPT pruning technique with sparse pretraining methods. This revolutionary technique seeks to attain excessive sparsity ranges whereas preserving or enhancing the mannequin’s accuracy. The researchers’ method entails initially pruning the mannequin to 50% sparsity, adopted by additional iterative coaching and pruning steps to succeed in 70% sparsity.
The tactic begins with sparse pretraining on subsets of high-quality datasets equivalent to SlimPajama and The Stack. The sparse pretraining course of contains fine-tuning with per-layer distillation, making certain the mannequin retains excessive accuracy throughout numerous complicated duties, together with chat, code era, and instruction following. This detailed course of entails coaching the 50% sparse mannequin till convergence after which pruning it additional to attain the 70% goal. The weights are pruned and frozen, and sparsity masks are enforced throughout coaching to take care of the specified sparsity ranges. This iterative course of is essential for sustaining excessive restoration ranges after fine-tuning.
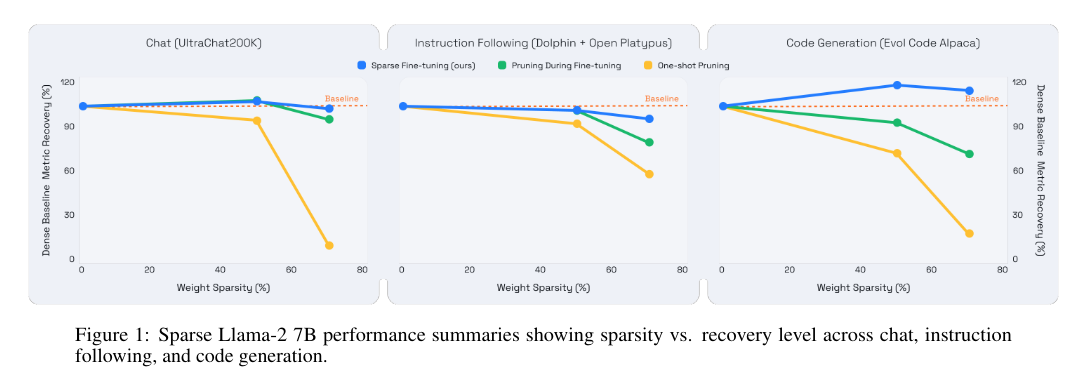
The sparse fashions demonstrated the power to attain as much as 70% sparsity whereas absolutely recovering accuracy for fine-tuning duties. Coaching acceleration on Cerebras CS-3 chips carefully matched theoretical scaling, showcasing the effectivity of the method. Inference speeds elevated considerably, with enhancements of as much as 3x on CPUs utilizing Neural Magic’s DeepSparse engine and 1.7x on GPUs utilizing the nm-vllm engine. Moreover, the mixture of sparsity and quantization resulted in complete speedups on CPUs reaching as much as 8.6x, highlighting the strategy’s effectivity and effectiveness.
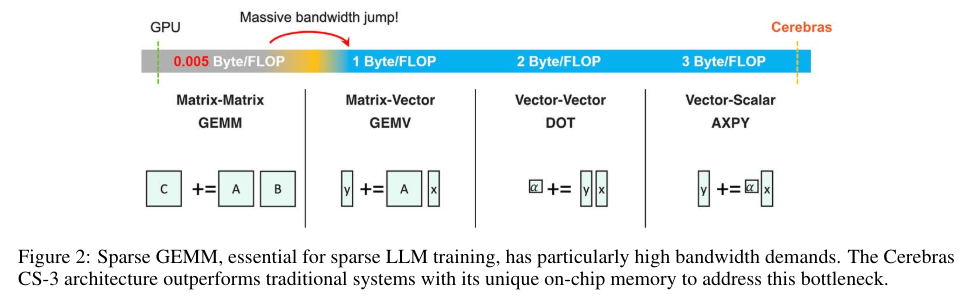
The research’s outcomes underscore the potential of mixing sparsity with quantization to attain dramatic speedups and efficiency positive aspects. The sparse pretraining methodology proved notably efficient, demonstrating excessive restoration at as much as 70% sparsity ranges. The combination of Cerebras’s CS-3 AI accelerator for sparse pretraining additional highlighted some great benefits of this method, enabling near-ideal speedups and considerably lowering computational necessities.

In conclusion, this analysis efficiently addresses the problem of lowering the computational calls for of LLMs whereas sustaining their efficiency. The revolutionary sparse pretraining and deployment methods launched by the Neural Magic, Cerebras Methods, and IST Austria researchers supply a promising resolution to the issue. This method not solely enhances the effectivity and accessibility of NLP fashions but in addition units the stage for future developments within the discipline.
Take a look at the Paper and Mannequin. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 42k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.