

Machine studying fashions, which might comprise billions of parameters, require refined strategies to fine-tune their efficiency effectively. Researchers purpose to boost the accuracy of those fashions whereas minimizing the computational sources wanted. This enchancment is essential for sensible purposes in varied domains, comparable to pure language processing & synthetic intelligence, the place environment friendly useful resource utilization can considerably affect total efficiency and feasibility.
A big downside in fine-tuning LLMs is the substantial GPU reminiscence required, making the method costly and resource-intensive. The problem lies in growing environment friendly fine-tuning strategies with out compromising the mannequin’s efficiency. This effectivity is especially vital because the fashions should adapt to new duties whereas retaining their beforehand realized capabilities. Environment friendly finetuning strategies be sure that massive fashions can be utilized in numerous purposes with out prohibitive prices.
Researchers from Columbia College and Databricks Mosaic AI have explored varied strategies to handle this difficulty, together with full finetuning and parameter-efficient finetuning methods like Low-Rank Adaptation (LoRA). Full finetuning includes adjusting all mannequin parameters, which is computationally costly. In distinction, LoRA goals to avoid wasting reminiscence by solely modifying a small subset of parameters, thereby lowering the computational load. Regardless of its recognition, the effectiveness of LoRA in comparison with full finetuning has been a subject of debate, particularly in difficult domains comparable to programming and arithmetic, the place exact efficiency enhancements are essential.
The analysis in contrast the efficiency of LoRA and full finetuning throughout two goal domains:
- Programming
- Arithmetic
They thought of instruction finetuning, involving roughly 100,000 prompt-response pairs, and continued pretraining with round 10 billion unstructured tokens. The comparability aimed to guage how effectively LoRA and full finetuning tailored to those particular domains, given the totally different knowledge regimes and the complexity of the duties. This complete comparability supplied an in depth understanding of the strengths and weaknesses of every methodology below varied circumstances.
The researchers found that LoRA usually underperformed in comparison with full finetuning in programming and arithmetic duties. For instance, within the programming area, full finetuning achieved a peak HumanEval rating of 0.263 at 20 billion tokens, whereas one of the best LoRA configuration reached solely 0.175 at 16 billion tokens. Equally, within the arithmetic area, full finetuning achieved a peak GSM8K rating of 0.642 at 4 epochs, whereas one of the best LoRA configuration achieved 0.622 on the similar level. Regardless of this underperformance, LoRA supplied a useful type of regularization, which helped keep the bottom mannequin’s efficiency on duties outdoors the goal area. This regularization impact was stronger than frequent methods like weight decay and dropout, making LoRA advantageous when retaining base mannequin efficiency, which is essential.
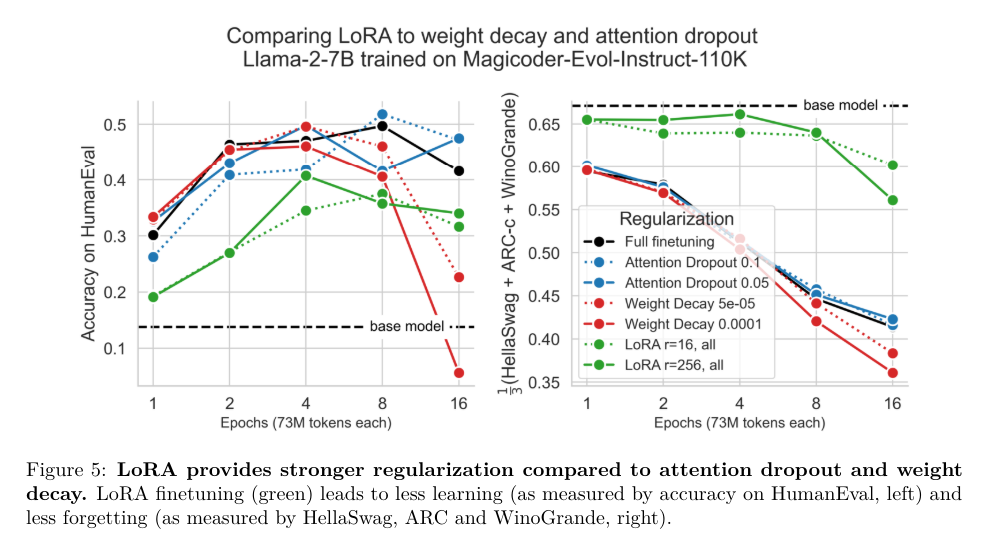
An in depth evaluation confirmed that full finetuning resulted in weight perturbations that ranked 10 to 100 instances better than these sometimes utilized in LoRA configurations. As an illustration, full finetuning required ranks as excessive as 256, whereas LoRA configurations sometimes used ranks of 16 or 256. This important distinction in rank probably explains a few of the efficiency gaps noticed. The analysis indicated that LoRA’s decrease rank perturbations contributed to sustaining extra numerous output generations than full finetuning, usually resulting in restricted options. This variety in output is helpful in purposes requiring diversified and artistic options.

In conclusion, whereas LoRA is much less efficient than full finetuning in accuracy and pattern effectivity, it provides important benefits in regularization and reminiscence effectivity. The examine means that optimizing hyperparameters, comparable to studying charges and goal modules, and understanding the trade-offs between studying and forgetting can improve LoRA’s utility to particular duties. The analysis highlighted that though full finetuning usually performs higher, LoRA’s capability to keep up the bottom mannequin’s capabilities and generate numerous outputs makes it worthwhile in sure contexts. This analysis supplies important insights into balancing efficiency and computational effectivity in finetuning LLMs, providing a pathway for extra sustainable and versatile AI improvement.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 42k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.