

Picture created by Creator utilizing Midjourney
Introduction to RAG
Within the always evolving world of language fashions, one steadfast methodology of specific notice is Retrieval Augmented Technology (RAG), a process incorporating components of Data Retrieval (IR) throughout the framework of a text-generation language mannequin with a view to generate human-like textual content with the purpose of being extra helpful and correct than that which might be generated by the default language mannequin alone. We’ll introduce the elementary ideas of RAG on this submit, with an eye fixed towards constructing some RAG techniques in subsequent posts.
RAG Overview
We create language fashions utilizing huge, generic datasets that aren’t tailor-made to your personal private or personalized information. To ontend with this actuality, RAG can mix your specific information with the prevailing “data” of an language mannequin. To facilitate this, what have to be achieved, and what RAG does, is to index your information to make it searchable. When a search made up of your information is executed, the related and necessary data is extracted from the listed information, and can be utilized inside a question towards a language mannequin to return a related and helpful response made by the mannequin. Any AI engineer, information scientist, or developer constructing chatbots, fashionable data retrieval techniques, or different varieties of private assistants, an understanding of RAG, and the data of easy methods to leverage your personal information, is vitally necessary.
Merely put, RAG is a novel method that enriches language fashions with enter retrieval performance, which boosts language fashions by incorporating IR mechanisms into the technology course of, mechanisms that may personalize (increase) the mannequin’s inherent “data” used for generative functions.
To summarize, RAG includes the next excessive degree steps:
- Retrieve data out of your personalized information sources
- Add this information to your immediate as extra context
- Have the LLM generate a response based mostly on the augmented immediate
RAG offers these benefits over the choice of mannequin fine-tuning:
- No coaching happens with RAG, so there is no such thing as a fine-tuning value or time
- Personalized information is as recent as you make it, and so the mannequin can successfully stay updated
- The particular personalized information paperwork will be cited throughout (or following) the method, and so the system is way more verifiable and reliable
A Nearer Look
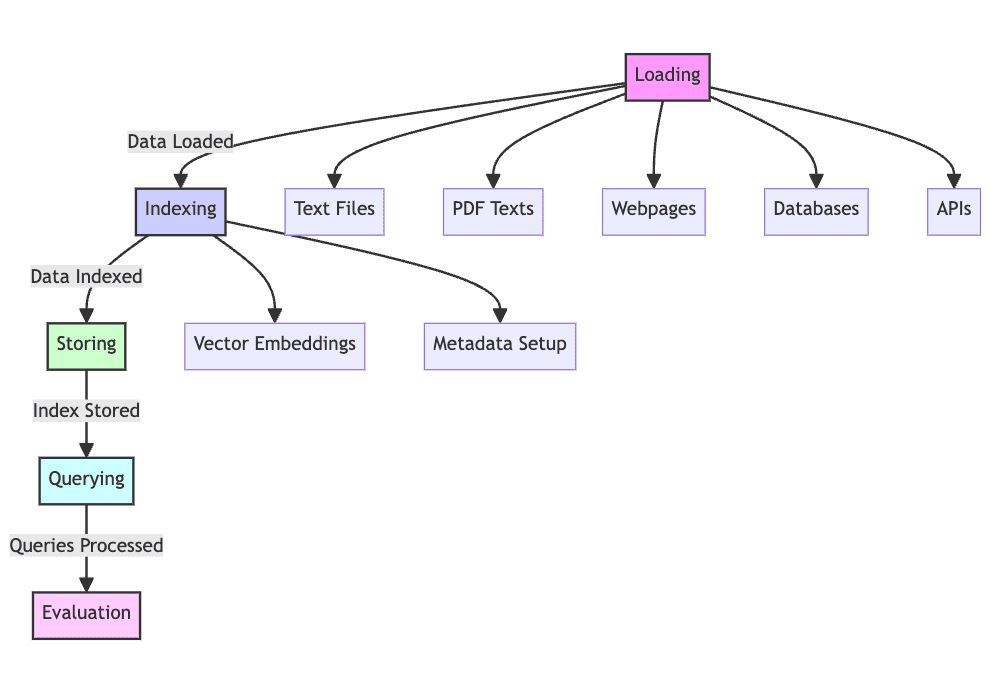
Upon a extra detailed examination, we are able to say {that a} RAG system will progress by way of 5 phases of operation.
1. Load: Gathering the uncooked textual content information — from textual content recordsdata, PDFs, net pages, databases, and extra — is the primary of many steps, placing the textual content information into the processing pipeline, making this a mandatory step within the course of. With out loading of information, RAG merely can’t perform.
2. Index: The info you now have have to be structured and maintained for retrieval, looking, and querying. Language fashions will use vector embeddings created from the content material to offer numerical representations of the information, in addition to using specific metadata to permit for profitable search outcomes.
3. Retailer: Following its creation, the index have to be saved alongside the metadata, guaranteeing this step doesn’t should be repeated repeatedly, permitting for simpler RAG system scaling.
4. Question: With this index in place, the content material will be traversed utilizing the indexer and language mannequin to course of the dataset in keeping with numerous queries.
5. Consider: Assessing efficiency versus different attainable generative steps is beneficial, whether or not when altering present processes or when testing the inherent latency and accuracy of techniques of this nature.
Picture created by Creator
A Brief Instance
Think about the next easy RAG implementation. Think about that it is a system created to discipline buyer enquiries a couple of fictitious on-line store.
1. Loading: Content material will spring from product documentation, person opinions, and buyer enter, saved in a number of codecs reminiscent of message boards, databases, and APIs.
2. Indexing: You’ll produce vector embeddings for product documentation and person opinions, and so on., alongside the indexing of metadata assigned to every information level, such because the product class or buyer ranking.
3. Storing: The index thus developed shall be saved in a vector retailer, a specialised database for the storage and optimum retreival of vectors, which is what embeddings are saved as.
4. Querying: When a buyer question arrives, a vector retailer databases lookup shall be achieved based mostly on the query textual content, and language fashions then employed to generate responses by utilizing the origins of this precursor information as context.
5. Analysis: System efficiency shall be evaluated by evaluating its efficiency to different choices, reminiscent of conventional language mannequin retreival, measuring metrics reminiscent of reply correctness, response latency, and general person satisfaction, to make sure that the RAG system will be tweaked and honed to ship superior outcomes.
This instance walkthrough ought to provide you with some sense of the methodology behind RAG and its use with a view to convey data retrieval capability upon a language mannequin.
Conclusion
Introducing retrieval augmented technology, which mixes textual content technology with data retrieval with a view to enhance accuracy and contextual consistency of language mannequin output, was the topic of this text. The tactic permits the extraction and augmentation of information saved in listed sources to be integrated into the generated output of language fashions. This RAG system can present improved worth over mere fine-tuning of language mannequin.
The subsequent steps of our RAG journey will encompass studying the instruments of the commerce with a view to implement some RAG techniques of our personal. We’ll first give attention to using instruments from LlamaIndex reminiscent of information connectors, engines, and software connectors to ease the mixing of RAG and its scaling. However we save this for the following article.
In forthcoming tasks we’ll assemble complicated RAG techniques and check out potential makes use of and enhancements to RAG expertise. The hope is to disclose many new potentialities within the realm of synthetic intelligence, and utilizing these numerous information sources to construct extra clever and contextualized techniques.
Matthew Mayo (@mattmayo13) holds a Grasp’s diploma in laptop science and a graduate diploma in information mining. As Managing Editor, Matthew goals to make complicated information science ideas accessible. His skilled pursuits embrace pure language processing, machine studying algorithms, and exploring rising AI. He’s pushed by a mission to democratize data within the information science group. Matthew has been coding since he was 6 years outdated.

Oneplus Nord CE4 (Dark Chrome, 8GB RAM, 256GB Storage)
₹26,999.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Samsung Original 25W Single Port, Type-C Fast Charger, (Cable not Included), White
₹1,297.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Ninja Call Pro Plus 1.83" Smart Watch with Bluetooth Calling, AI Voice Assistance, 100 Sports Modes IP67 Rating, 240 * 280 Pixel High Resolution
₹1,299.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple iPhone 13 (128GB) - Midnight
₹49,299.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C 5G (Startrail Silver, 4GB RAM, 128GB Storage) | MediaTek Dimensity 6100+ 5G | 90Hz Display
₹10,499.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Max in Ear Earphones with 60H Playtime,Eq Modes,Power Magnetic Earbuds,Beast Mode,Enx Tech,ASAP Charge(10 Mins=10 Hrs),Textured Finish,Dual Pair(Stunning Black),Bluetooth
₹1,099.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹698.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹249.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Logitech B170 Wireless Mouse, 2.4 GHz with USB Nano Receiver, Optical Tracking, 12-Months Battery Life, Ambidextrous, PC/Mac/Laptop - Black
₹595.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link TL-WA850RE Single_Band 300Mbps RJ45 Wireless Range Extender, Broadband/Wi-Fi Extender, Wi-Fi Booster/Hotspot with 1 Ethernet Port, Plug and Play, Built-in Access Point Mode, White
₹1,299.00 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
2 Packs-iPhone Headphones for Apple Earbuds Wired Lightning Earphones [Apple MFi Certified]Built-in Microphone & Volume Control Noise Isolating Earphones for iPhone 14/13/12/11/XR/XS/X/8/7/Pro/Pro Max
$9.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 1TB External Hard Drive HDD – USB 3.0 for PC, Mac, PlayStation, & Xbox, 1-Year Rescue Service (STGX1000400) , Black
$59.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 2TB Portable External Hard Drive USB 3.0, Black - HDTB520XK3AA
$77.12 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ROOFULL External CD DVD +/-RW Drive USB 3.0 & USB-C CD Burner DVD Player Reader Writer Optical Disc Drive with Carrying Case for Laptop Mac MacBook Pro/Air, Windows 11/10/8/7, Linux PC
$34.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)