

At the moment we’re excited to announce MLflow 2.8 helps our LLM-as-a-judge metrics which may also help save time and prices whereas offering an approximation of human-judged metrics. In our earlier report, we mentioned how the LLM-as-a-judge approach helped us increase effectivity, lower prices, and preserve over 80% consistency with human scores within the Databricks Documentation AI Assistant, leading to vital financial savings in time (from 2 weeks with human workforce to half-hour with LLM judges) and prices (from $20 per job to $0.20 per job). We’ve additionally adopted up our earlier report on finest practices for LLM-as-a-judge analysis of RAG (Retrieval Augmented Era) purposes with a Half 2 under. We’ll stroll via how one can apply the same methodology, together with information cleansing, to guage and tune the efficiency of your personal RAG purposes. As with the earlier report, LLM-as-a-judge is a promising software with a tradeoff between value and accuracy of the ensuing metrics, and a worthy companion to the gold normal of human-judged analysis.
MLflow 2.8: Automated Analysis
The LLM group has been exploring the usage of “LLMs as a choose” for automated analysis and we utilized their idea to manufacturing tasks. We discovered it can save you vital prices and time should you use automated analysis with state-of-the-art LLMs, just like the GPT, MPT, and Llama2 mannequin households, with a single analysis instance for every criterion. MLflow 2.8 introduces a robust and customizable framework for LLM analysis. We have prolonged the MLflow Analysis API to help GenAI metrics and analysis examples. You get out-of-the-box metrics like toxicity, latency, tokens and extra, alongside some GenAI metrics that use GPT-4 because the default choose, like faithfulness, answer_correctness, and answer_similarity. Customized metrics can at all times be added in MLflow, even for GenAI metrics. Let’s have a look at MLflow 2.8 in apply with some examples!
When making a customized GenAI metric with the LLM-as-a-judge approach, it’s a must to select which LLM you need as a choose, present a grading scale, and provides an instance for every grade within the scale. Right here is an instance of tips on how to outline a GenAI metric for `Professionalism` in MLflow 2.8:
professionalism = mlflow.metrics.make_genai_metric(
identify="professionalism",
definition=(
"Professionalism refers to the usage of a proper, respectful, and applicable model of communication that's "
"tailor-made to the context and viewers. It typically includes avoiding overly informal language, slang, or "
"colloquialisms, and as an alternative utilizing clear, concise, and respectful language."
),
grading_prompt=(
"Professionalism: If the reply is written utilizing knowledgeable tone, under are the small print for various scores: "
"- Rating 1: Language is extraordinarily informal, casual, and should embrace slang or colloquialisms. Not appropriate for "
"skilled contexts."
"- Rating 2: Language is informal however typically respectful and avoids robust informality or slang. Acceptable in "
"some casual skilled settings."
"- Rating 3: Language is total formal however nonetheless have informal phrases/phrases. Borderline for skilled contexts."
"- Rating 4: Language is balanced and avoids excessive informality or formality. Appropriate for {most professional} contexts. "
"- Rating 5: Language is noticeably formal, respectful, and avoids informal parts. Applicable for formal "
"enterprise or tutorial settings. "
),
examples=[professionalism_example_score_1, professionalism_example_score_2, professionalism_example_score_3, professionalism_example_score_4, professionalism_example_score_5],
mannequin="openai:/gpt-4",
parameters={"temperature": 0.0},
aggregations=["mean", "variance"],
greater_is_better=True,
)Much like what we noticed in our earlier report, analysis examples (the `examples` record within the snippet above) may also help with the accuracy of the LLM-judged metric. MLflow 2.8 makes it straightforward to outline an EvaluationExample:
professionalism_example_score_2 = mlflow.metrics.EvaluationExample(
enter="What's MLflow?",
output=(
"MLflow is like your pleasant neighborhood toolkit for managing your machine studying tasks. It helps "
"you observe experiments, bundle your code and fashions, and collaborate along with your group, making the entire ML "
"workflow smoother. It is like your Swiss Military knife for machine studying!"
),
rating=2,
justification=(
"The response is written in an informal tone. It makes use of contractions, filler phrases reminiscent of 'like', and "
"exclamation factors, which make it sound much less skilled. "
),
)We all know there are frequent metrics that you just want so MLflow 2.8 helps some GenAI metrics out-of-the-box. By telling us what `model_type` your utility is, e.g., “question-answering”, the MLflow Consider API will robotically generate frequent GenAI metrics for you. You may add “additional” metrics as effectively, like we do with “Reply Relevance” within the following instance:
from mlflow.metrics.genai.metric_definitions import answer_relevance
answer_relevance_metric = answer_relevance()
eval_df = pd.DataFrame() # Index(['inputs', 'predictions', 'context'], dtype='object')
eval_results = mlflow.consider(
information = eval_df, # analysis information
model_type="question-answering",
predictions="predictions", # prediction column_name from eval_df
extra_metrics=[answer_relevance_metric]
)To additional refine efficiency, you can too alter the choose mannequin and immediate for these out-of-the-box GenAI metrics. Under is a screenshot of the MLflow UI that helps you shortly examine GenAI metrics visually within the Analysis tab:
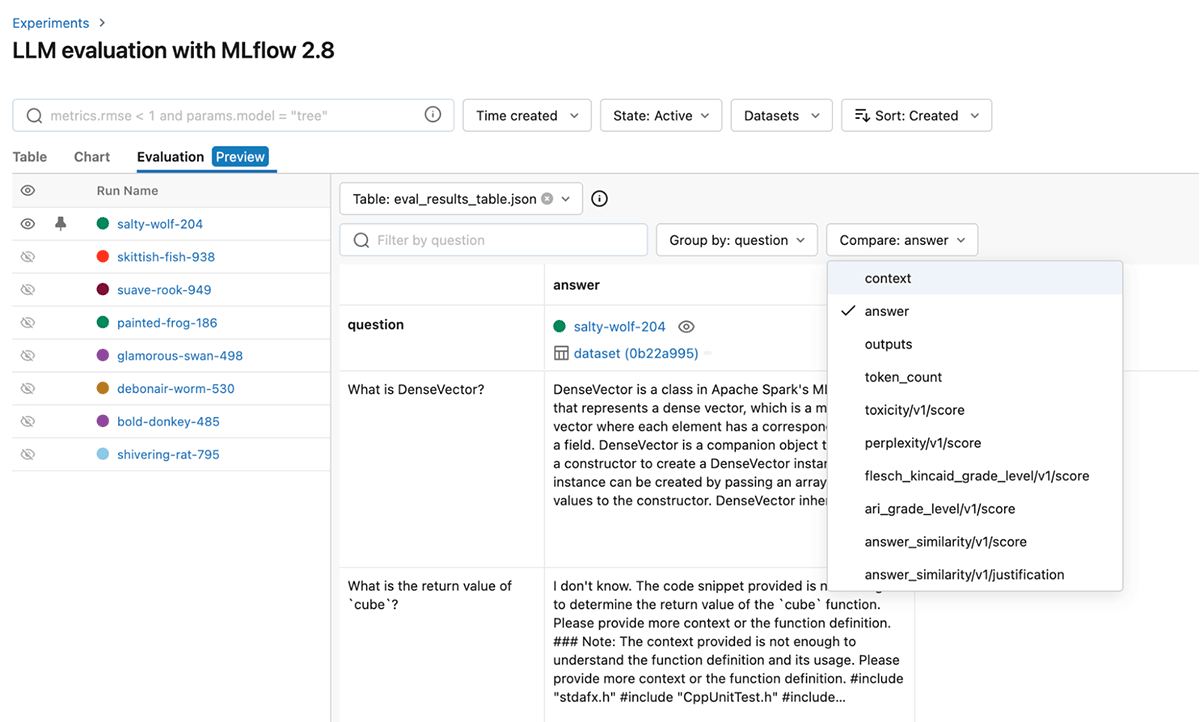
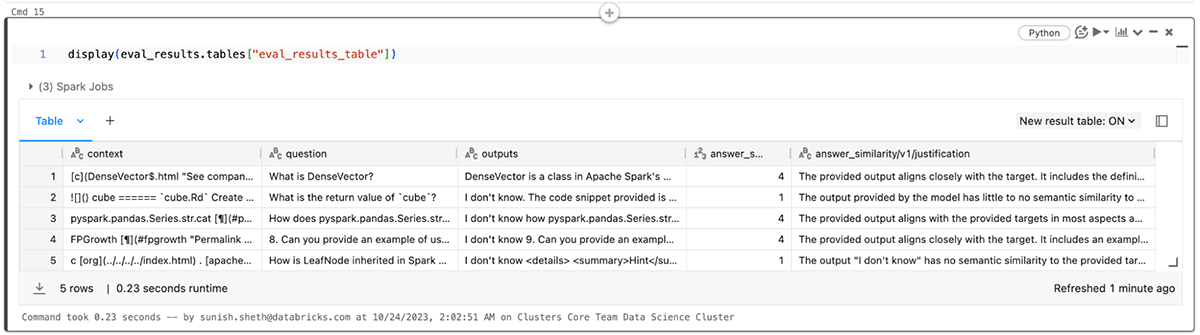
It’s also possible to view ends in the corresponding eval_results_table.json or load them as a Pandas dataframe for additional evaluation.
Making use of LLM Analysis to RAG Functions: Half 2
Within the subsequent spherical of our investigations, we revisited our manufacturing utility of the Databricks Documentation AI Assistant to see if we might enhance efficiency by bettering the standard of the enter information. From this investigation, we developed a workflow to robotically cleanup information that achieved increased correctness and readability of chatbot solutions in addition to diminished the variety of tokens to cut back value and and enhance pace.
Knowledge cleansing for efficient auto-evaluation for RAG Functions
We explored the impression of information high quality on chatbot response efficiency in addition to varied information cleansing strategies to enhance efficiency. We consider these discovering generalize and may also help your group successfully consider RAG-based chatbots:
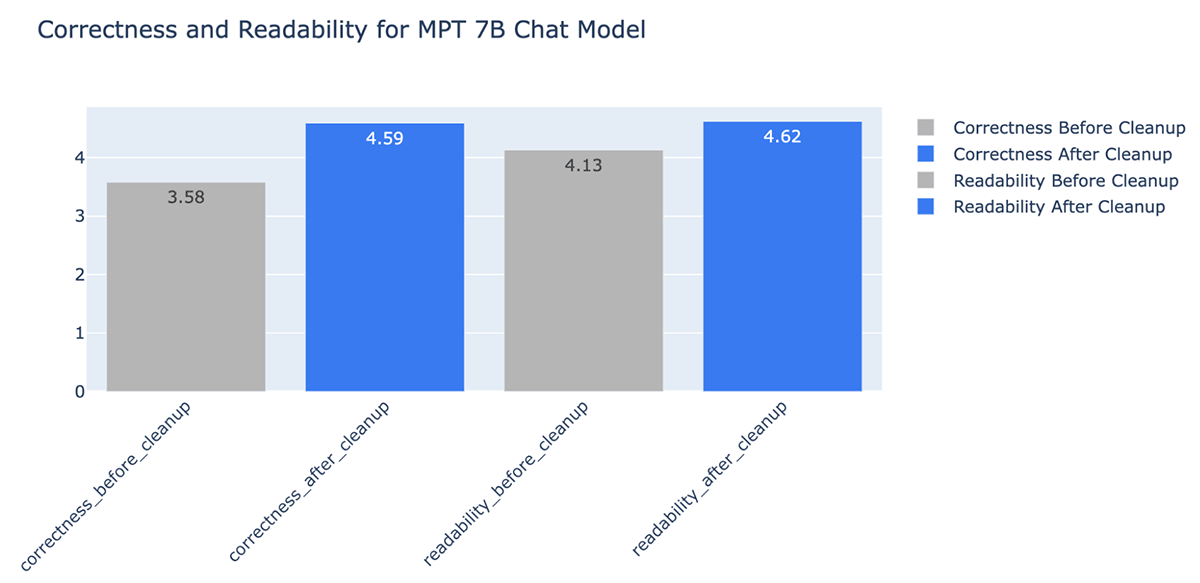
- Knowledge cleansing improved the correctness of the LLM generated solutions by as much as +20% (from 3.58 to 4.59 for grading scale 1~5)
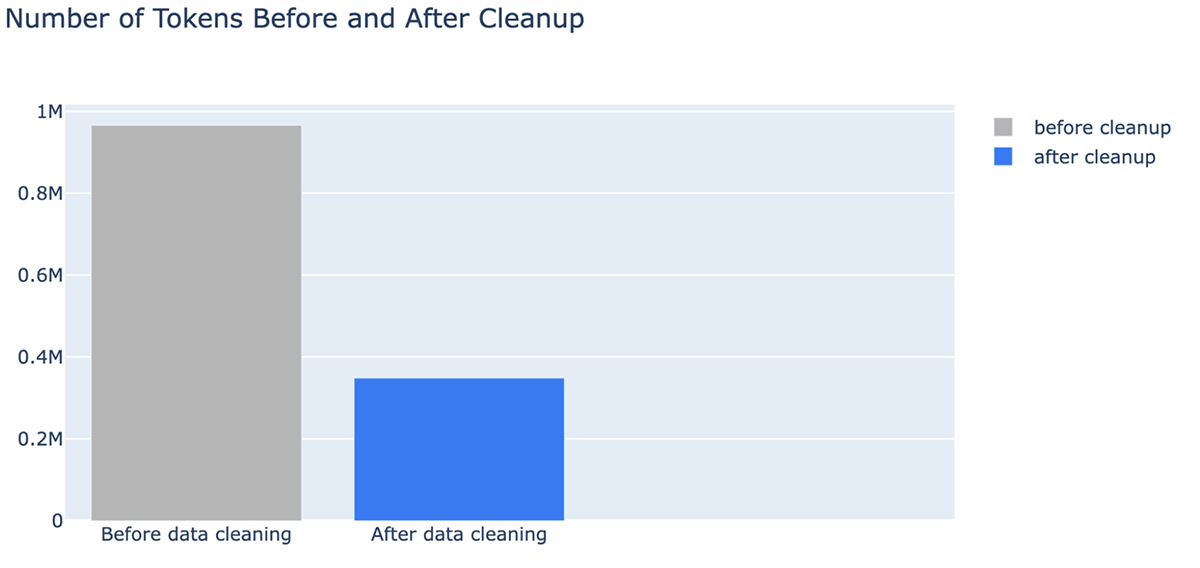
- An surprising profit of information cleansing is that it will possibly decrease prices by needing fewer tokens. Knowledge cleansing diminished the variety of tokens for the context by as much as -64% (from 965538 tokens within the listed information to 348542 tokens after cleansing)
- Totally different LLMs behave higher with totally different information cleansing code
Knowledge challenges with RAG purposes
There are varied enter information sorts for RAG purposes: web site pages, PDF, Google Doc, Wiki pages and many others. Essentially the most often used information sorts we have seen from trade and from our prospects are web sites and PDFs. Our Databricks Doc AI Assistant makes use of the official Databricks documentation, Data Base, and Spark documentation pages as its information sources. Whereas documentation web sites are human-readable, the format could also be exhausting for an LLM to know. Under is an instance:
| Rendered for Human | Rendered for LLM |
|---|---|
 |
 |
Right here the Markdown format and code snippet language choices present an easy-to-understand UI for presenting corresponding examples for every language. Nevertheless, as soon as this UI is transformed into solely Markdown format for an LLM, the content material will get transformed into a number of repeating code blocks making it exhausting to know. Consequently, once we requested mpt-7b-chat the query “How do you configure a unique default catalog identify?” given the context, it offers reply as ““` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “`”, which is the repetition of the code block image. In different circumstances, the LLM fails to comply with the directions and begins to repeat the questions. Equally, a webpage would possibly include varied icons, pictures, and particular symbols to be utilized by the browser for rendering a greater UI, which additionally confuses LLMs. Word, another strategy is to alter the immediate to disregard the formatting markup. Nevertheless, we anticipate to additional tune the immediate for the actual utility, and we would slightly keep away from making it overly difficult and introducing instability.
Knowledge cleansing improves efficiency
We wrote a fast workflow that leveraged LLM-as-judge and iteratively found out the cleanup code to take away extraneous formatting tokens from Markdown information and webpages. Under is an instance of what a single doc appears like earlier than and after cleanup, illustrating that the doc retains each its construction and which means:

It’s also possible to clearly see that doc cleanup can dramatically cut back the variety of tokens utilized in an LLM context window, saving prices and time. After information cleansing, we noticed enhancements within the reply from MPT-7B-Chat:
| Query | Reply earlier than cleansing | Reply after cleansing |
|---|---|---|
| What’s the syntax to create a schema utilizing Spark SQL? | “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` | To create a schema utilizing Spark SQL, you should utilize the next syntax: CREATE SCHEMA [schema_name] You may specify the situation of the schema utilizing the LOCATION clause, and you can too present a de… |
| What are the frequent Outcomes per Object for S3, ADLS Gen2, and GCS storage? | What are the frequent Outcomes per Object for S3, ADLS Gen2, and GCS storage? “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` “` | The frequent Outcomes per Object for S3, ADLS Gen2, and GCS storage are: 1 (base listing) 365 (per day) 24 hours) 8761 That is the full variety of API calls object storage that might be made per day, ba… |
| How do you pin a persona to the sidebar? | Thanks in your assist! | To pin a persona to the sidebar, you’ll be able to click on on the persona icon under the Databricks brand, choose the specified persona, and click on the “Pin persona” button. This may make sure that the chosen individual… |
| What APIs can be found in Databricks? | reply reply: There are three SQL warehouse sorts out there in Databricks: Serverless, Professional, and Basic. The default SQL warehouse kind is Professional, however it may be set to Serverless or Basic utilizing | There are a number of APIs out there in Databricks for information warehousing, together with the SQL warehouse API, the queries API, the visualizations API, and the dashboards API. These APIs present a variety of fu… |
Strive MLflow 2.8 in the present day for auto-evaluation
In Half 2 of our evaluation, we used MLflow 2.8 to guage RAG purposes with LLM-as-a-judge. Now with information cleansing and auto-evaluation, you’ll be able to shortly and effectively examine and distinction varied LLMs to navigate via your RAG utility necessities. Some sources that can assist you get began: