

Giant language fashions (LLMs) have excelled in pure language duties and instruction following, but they wrestle with non-textual information like photographs and audio. Incorporating speech comprehension may vastly enhance human-computer interplay. Present strategies depend on automated speech recognition (ASR) adopted by LLM processing, lacking non-textual cues. A promising strategy integrates textual LLMs with speech encoders in a single coaching setup. This enables for a extra complete understanding of each speech and textual content, promising richer comprehension in comparison with text-only strategies. Notably, instruction-following multimodal audio-language fashions are gaining traction resulting from their means to generalize throughout duties. Whereas earlier works like SpeechT5, Whisper, VIOLA, SpeechGPT, and SLM present promise, they’re constrained to a restricted vary of speech duties.
Multi-task studying entails leveraging shared representations throughout numerous duties to boost generalization and effectivity. Fashions like T5 and SpeechNet make use of this strategy for textual content and speech duties, attaining vital outcomes. Nevertheless, multimodal giant language fashions integrating audio have garnered much less consideration. Latest efforts like SpeechGPT and Qwen-Audio goal to bridge this hole, showcasing capabilities in numerous audio duties. SpeechVerse innovatively combines multi-task studying and instruction finetuning to realize superior efficiency in audio-text duties.
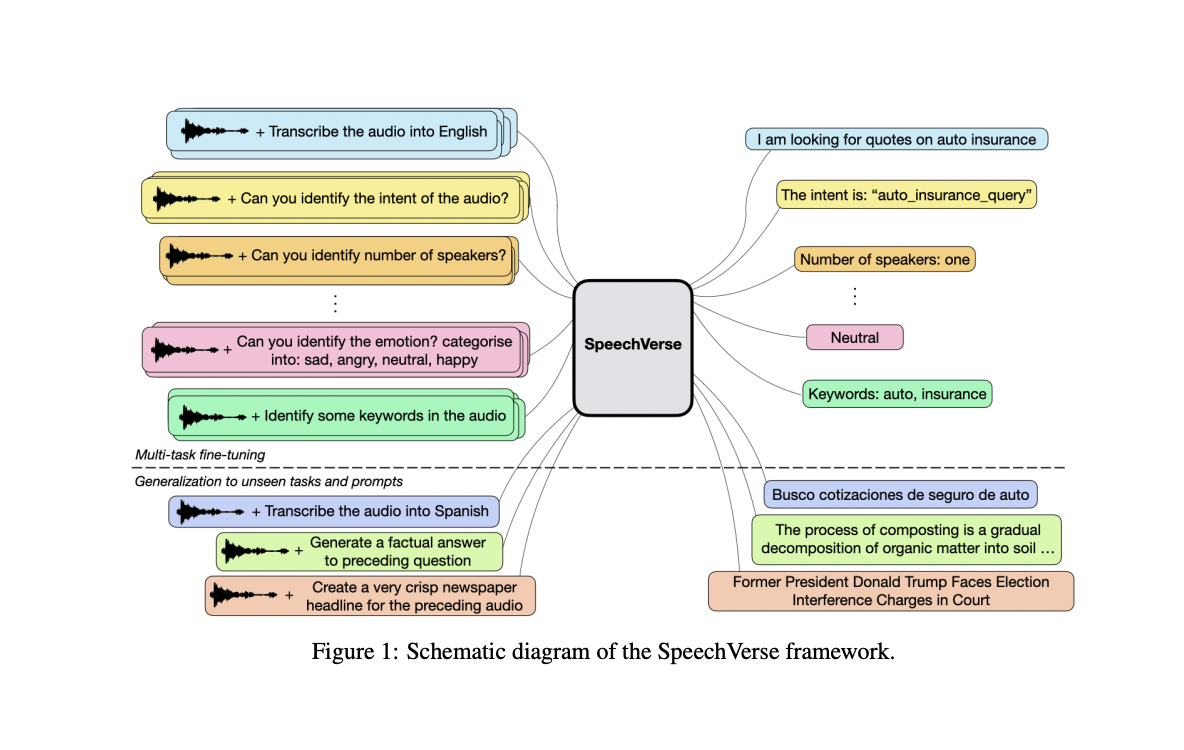
Amazon researchers introduce SpeechVerse, a multi-task framework with supervised instruction finetuning for numerous speech duties. In contrast to SpeechGPT, it makes use of steady representations from pre-trained speech fashions for text-only output duties. Compared to Qwen-Audio, which requires hierarchical tagging and a large-scale audio encoder, SpeechVerse incorporates multi-task studying and finetuning with out task-specific tagging, enabling generalization to unseen duties by pure language directions.
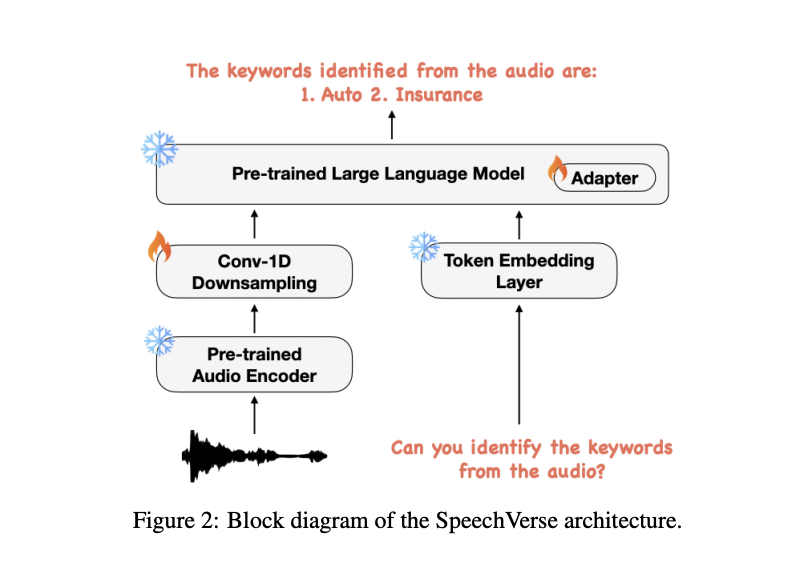
The multimodal mannequin structure of SpeechVerse includes an audio encoder, a convolution downsampling module, and an LLM. The audio encoder extracts semantic options from audio utilizing a pre-trained mannequin, producing a unified illustration. The downsampling module adjusts the audio options for compatibility with LLM token sequences. The LLM processes textual content and audio enter, combining downsampled audio options with token embeddings. Curriculum studying with parameter-efficient finetuning optimizes coaching, freezing pre-trained elements to effectively deal with numerous speech duties.
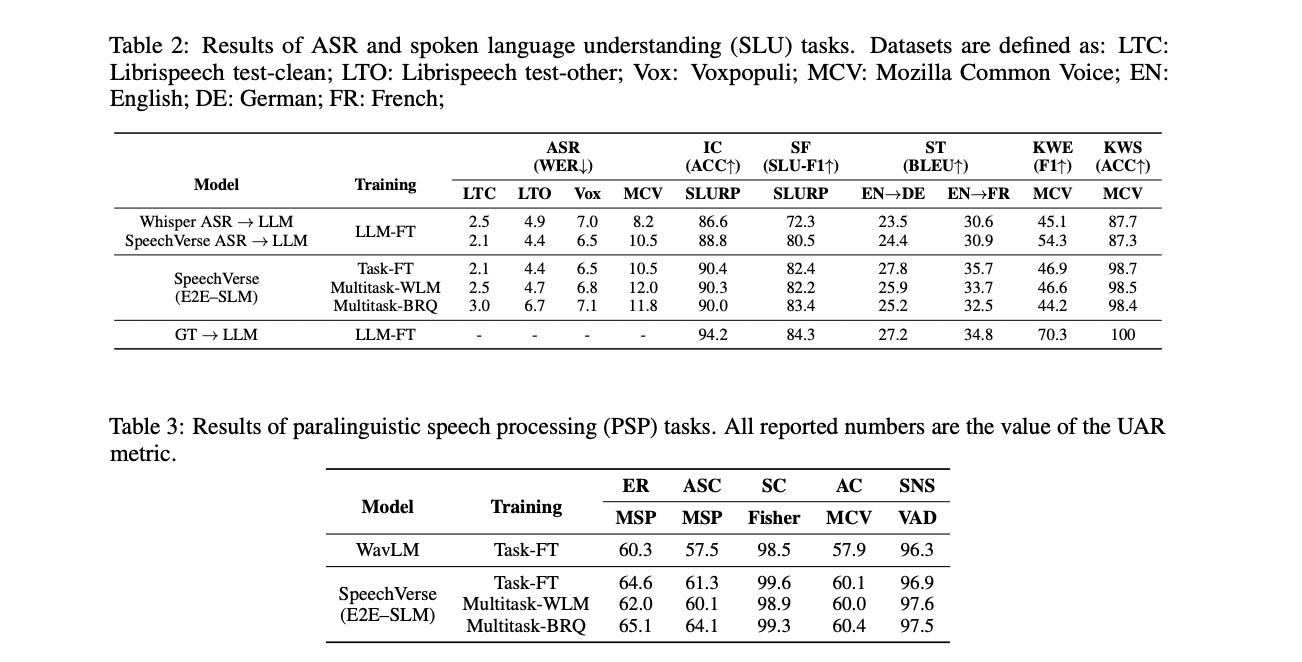
The analysis of end-to-end skilled joint speech and language fashions (E2E-SLM) utilizing the SpeechVerse framework covers 11 duties spanning numerous domains and datasets. ASR benchmarks reveal the efficacy of SpeechVerse’s core speech understanding, with task-specific pre-trained ASR fashions exhibiting promising outcomes. For SLU duties, end-to-end skilled fashions outperform cascaded pipelines usually, demonstrating the effectiveness of SpeechVerse. SpeechVerse fashions additionally exhibit aggressive or superior efficiency in comparison with state-of-the-art fashions throughout numerous duties like ASR, ST, IC, SF, and ER.
To recapitulate, SpeechVerse is launched by Amazon researchers, a multimodal framework enabling LLMs to execute numerous speech processing duties by pure language directions. Using supervised instruction finetuning and mixing representations from pre-trained speech and textual content fashions, SpeechVerse displays robust zero-shot generalization on unseen duties. Comparative evaluation towards standard baselines underscores SpeechVerse’s superior efficiency on 9 out of 11 duties, showcasing its sturdy instruction-following functionality. The mannequin demonstrates resilience throughout out-of-domain datasets, unseen prompts, and novel duties, highlighting the effectiveness of the proposed coaching strategy in fostering generalizability.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 42k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.