

Audio classification has developed considerably with the adoption of deep studying fashions. Initially dominated by Convolutional Neural Networks (CNNs), this discipline has shifted in the direction of transformer-based architectures, which supply improved efficiency and the flexibility to deal with numerous duties by way of a unified method. Transformers surpass CNNs in efficiency, making a paradigm shift in deep studying, particularly for features requiring intensive contextual understanding and dealing with various enter information varieties.
The first problem in audio classification is the computational complexity related to transformers, significantly as a consequence of their self-attention mechanism, which scales quadratically with the sequence size. This makes it inefficient for processing lengthy audio sequences, necessitating various strategies to keep up efficiency whereas decreasing computational load. Addressing this situation is essential for creating fashions that may effectively deal with audio information’s rising quantity and complexity in numerous purposes, from speech recognition to environmental sound classification.
Presently, essentially the most outstanding methodology for audio classification is the Audio Spectrogram Transformer (AST). ASTs make the most of self-attention mechanisms to seize the worldwide context in audio information however endure from excessive computational prices. State house fashions (SSMs) have been explored as a possible various, providing linear scaling with sequence size. SSMs, akin to Mamba, have proven promise in language and imaginative and prescient duties by changing self-attention with time-varying parameters to seize international context extra effectively. Regardless of their success in different domains, SSMs have but to be broadly adopted in audio classification, presenting a possibility for innovation on this space.

Researchers from the Korea Superior Institute of Science and Know-how launched Audio Mamba (AuM), a novel self-attention-free mannequin primarily based on state house fashions for audio classification. This mannequin processes audio spectrograms effectively utilizing a bidirectional method to deal with lengthy sequences with out the quadratic scaling related to transformers. The AuM mannequin goals to remove the computational burden of self-attention, leveraging SSMs to keep up excessive efficiency whereas enhancing effectivity. By addressing the inefficiencies of transformers, AuM affords a promising various for audio classification duties.
Audio Mamba’s structure entails changing enter audio waveforms into spectrograms, that are then divided into patches. These patches are reworked into embedding tokens and processed utilizing bidirectional state house fashions. The mannequin operates in each ahead and backward instructions, capturing the worldwide context effectively and sustaining linear time complexity, thus enhancing processing velocity and reminiscence utilization in comparison with ASTs. The structure incorporates a number of revolutionary design selections, such because the strategic placement of a learnable classification token in the course of the sequence and using positional embeddings to boost the mannequin’s capability to grasp the spatial construction of the enter information.
Audio Mamba demonstrated aggressive efficiency throughout numerous benchmarks, together with AudioSet, VGGSound, and VoxCeleb. The mannequin achieved comparable or higher outcomes than AST, significantly excelling in duties involving lengthy audio sequences. For instance, within the VGGSound dataset, Audio Mamba outperformed AST with a considerable accuracy enchancment of over 5%, reaching 42.58% accuracy in comparison with AST’s 37.25%. On the AudioSet dataset, AuM achieved a imply common precision (mAP) of 32.43%, surpassing AST’s 29.10%. These outcomes spotlight AuM’s capability to ship excessive efficiency whereas sustaining computational effectivity, making it a sturdy answer for numerous audio classification duties.
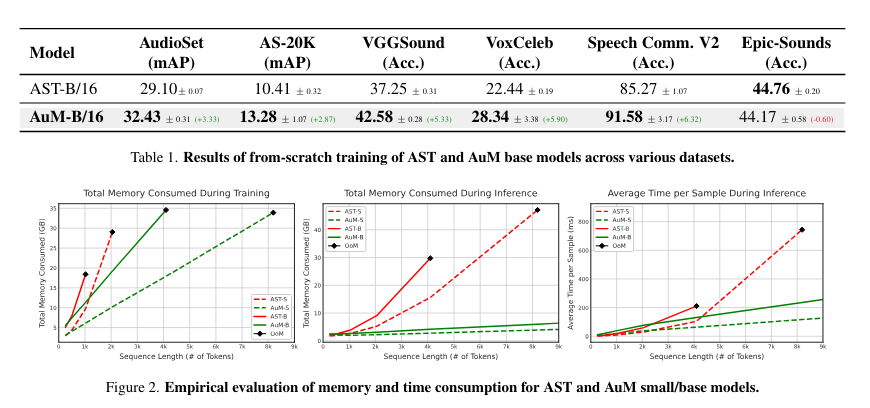
The analysis confirmed that AuM requires considerably much less reminiscence and processing time. As an example, throughout coaching with 20-second audio clips, AuM consumed reminiscence equal to AST’s smaller mannequin whereas delivering superior efficiency. Moreover, AuM’s inference time was 1.6 instances sooner than AST’s at a token rely 4096, demonstrating its effectivity in dealing with lengthy sequences. This discount in computational necessities with out compromising accuracy signifies that AuM is well-suited for real-world purposes the place useful resource constraints are a crucial consideration.
In abstract, the introduction of Audio Mamba marks a big development in audio classification by addressing the constraints of self-attention in transformers. The mannequin’s effectivity and aggressive efficiency spotlight its potential as a viable various for processing lengthy audio sequences. Researchers consider that Audio Mamba’s method may pave the best way for future audio and multimodal studying purposes developments. The flexibility to deal with prolonged audio is more and more essential, particularly with the rise of self-supervised multimodal studying and era that leverages in-the-wild information and computerized speech recognition. Moreover, AuM may very well be employed in self-supervised studying setups like Audio Masked Auto Encoders or multimodal studying duties akin to Audio-Visible pretraining or Contrastive Language-Audio Pretraining, contributing to the development of the audio classification discipline.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

OnePlus Nord 3 5G (Misty Green, 8GB RAM, 128GB Storage)
₹19,999.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C 5G (Startrail Green, 4GB RAM, 128GB Storage) | MediaTek Dimensity 6100+ 5G | 90Hz Display
₹10,499.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme Buds T300 TWS Earbuds with 40H Play time,30dB ANC, 360° Spatial Audio with Dolby Atmos, 12.4 mm Dynamic Bass Boost Driver, IP55 Water & Dust Resistant, BT v5.3 (Stylish Black)
₹1,999.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z9x 5G (Tornado Green, 8GB RAM, 128GB Storage) | Snapdragon 6 Gen 1 with 560K+ AnTuTu Score | 6000 mAh Battery with 7.99mm Slim Design | 44W FlashCharge
₹15,999.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord 3 5G (Tempest Gray, 8GB RAM, 128GB Storage)
₹19,999.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect X USB to Type C Cable with 3A Output, Fast Charging & Data Transfer, Nylon Braided, Aluminium Alloy Shell, 1M Length compatible with Type C Smartphones(White)
₹135.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹299.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,399.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹174.00 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Samsung 990 EVO SSD 1TB, PCIe Gen 4x4, Gen 5x2 M.2 2280 NVMe Internal Solid State Drive, Speeds Up to 5,000MB/s, Upgrade Storage for PC Computer, Laptop, MZ-V9E1T0B/AM, Black
$84.99 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 7 7800X3D 8-Core, 16-Thread Desktop Processor
$339.99 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$99.99 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 2TB Portable External Hard Drive USB 3.0, Black - HDTB520XK3AA
$69.90 (as of June 7, 2024 11:46 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)