

Transformers have taken over from recurrent neural networks (RNNs) as the popular structure for pure language processing (NLP). Transformers stand out conceptually as a result of they immediately entry every token in a sequence, not like RNNs that depend on sustaining a recurring state of previous inputs. Decoders have emerged as a distinguished variant inside the realm of transformers. These decoders generally produce output in an auto-regressive method, that means the technology of every token is influenced by the important thing and worth computations of previous tokens.
Researchers from The Hebrew College of Jerusalem and FAIR, AI at Meta, have demonstrated that the auto-regressive nature of transformers aligns with the basic precept of RNNs, which entails preserving a state from one step to the following. They formally redefine decoder-only transformers as multi-state RNNs (MSRNN), presenting a generalized model of conventional RNNs. This redefinition highlights that because the variety of earlier tokens will increase throughout decoding, transformers develop into MSRNNs with infinite states. The researchers additional present that transformers might be compressed into finite MSRNNs by limiting the variety of tokens processed at every step. They introduce TOVA, a compression coverage for MSRNNs, which selects tokens to retain based mostly solely on their consideration scores. The analysis of TOVA is carried out on 4 long-range duties.
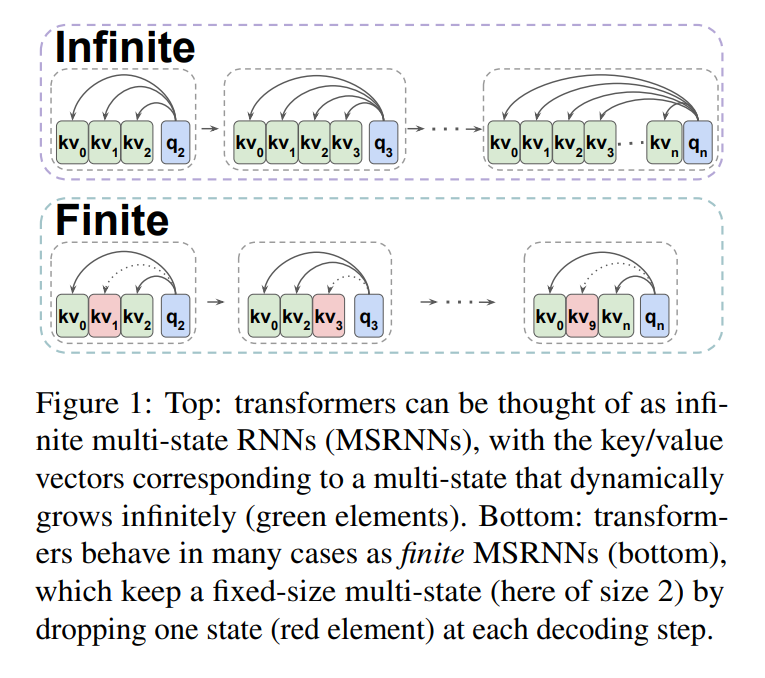
The examine compares transformers and RNNs, demonstrating that decoder-only transformers might be conceptualized as infinite multi-state RNNs, and pretrained transformers might be transformed into finite multi-state RNNs by fixing the scale of their hidden state. It reviews perplexity on the PG-19 check set for language modeling. It makes use of check units from the ZeroSCROLLS benchmark for evaluating long-range understanding, together with long-range summarization and long-range question-answering duties. The examine mentions utilizing the QASPER dataset for lengthy textual content query answering and evaluating generated tales utilizing GPT-4 as an evaluator.
The examine demonstrates that decoder-only transformers might be conceptualized as infinite multi-state RNNs, and pretrained transformers might be transformed into finite multi-state RNNs by fixing the scale of their hidden state. The examine additionally mentions modifying the eye masks to include completely different MSRNN insurance policies, such because the First In First Out (FIFO) technique, to successfully parallel the language modeling activity. The researchers use the GPT-4 mannequin to guage the generated texts and examine the output of the TOVA coverage with the topline mannequin.
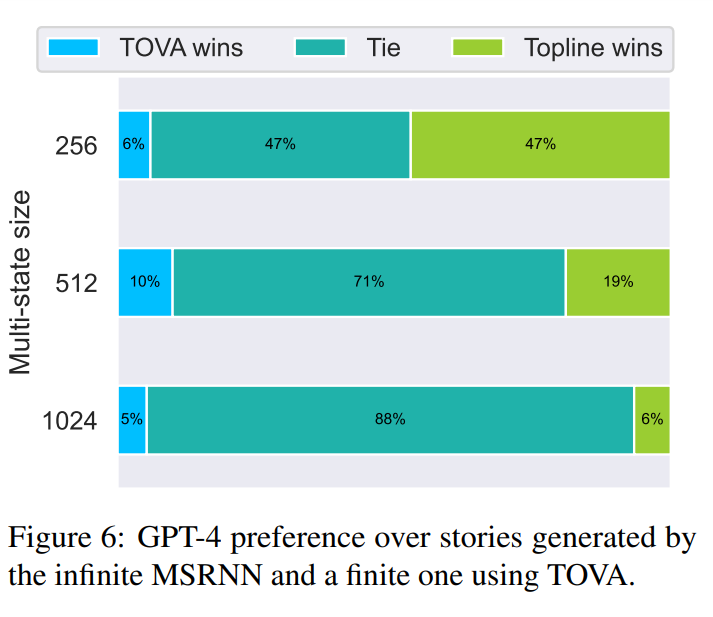
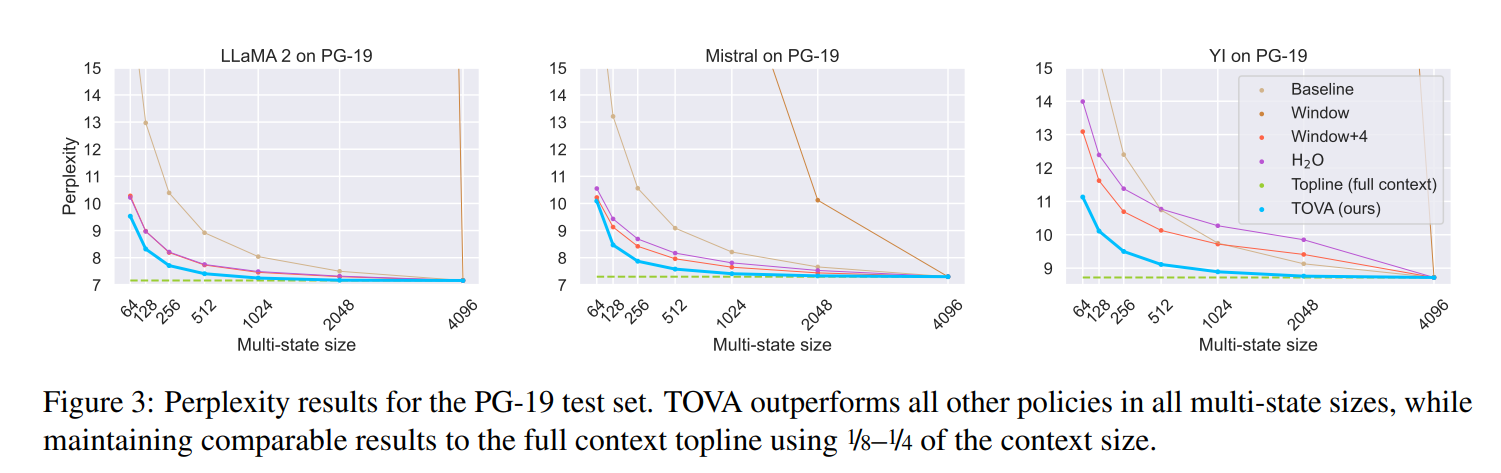
The examine demonstrates that transformer decoder LLMs behave as finite MSRNNs though they’re educated as infinite MSRNNs. The proposed TOVA coverage performs constantly higher than different insurance policies in long-range duties with smaller cache sizes throughout all multi-state sizes and fashions. The experiments present that utilizing TOVA with 1 / 4 and even one-eighth of the total context yields outcomes inside one level of the topline mannequin in language modeling duties. The examine additionally reviews a big discount in LLM cache dimension, as much as 88%, resulting in lowered reminiscence consumption throughout inference. The researchers acknowledge the computational constraints and approximate the infinite MSRNN with a sequence size of 4,096 tokens for extrapolation experiments.
To summarize, the researchers have redefined decoder transformers as multi-state RNNs with an infinite multi-state dimension. When the variety of token representations that transformers can deal with at every step is restricted, it’s the similar as compressing it from infinite to finite MSRNNs. The TOVA coverage, which is an easy compression methodology that selects which tokens to maintain utilizing their consideration scores, has been discovered to outperform present compression insurance policies and performs comparably to the infinite MSRNN mannequin with a lowered multi-state dimension. Though not educated, transformers typically perform as finite MSRNNs in apply. These findings present insights into the inter-working of transformers and their connections to RNNs. Additionally, they’ve sensible worth in decreasing the LLM cache dimension by as much as 88%.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.

HONOR 90 (Emerald Green, 8GB + 256GB) | India's First Eye Risk-Free Display | 200MP Main & 50MP Selfie Camera | Segment First Quad-Curved AMOLED Screen | Without Charger
₹37,999.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C 5G (Starlight Black, 4GB RAM, 128GB Storage) | MediaTek Dimensity 6100+ 5G | 90Hz Display
₹10,998.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z6 Lite 5G (Stellar Green, 6GB RAM, 128GB Storage) with Charger | Qualcomm Snapdragon 4 Gen 1 Processor | 120Hz FHD+ Display | Travel Adaptor Included in The Box
₹12,999.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme narzo N53 (Feather Gold, 4GB+64GB) 33W Segment Fastest Charging | Slim Smartphone | 90 Hz Smooth Display
₹7,999.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 5G (Aqua Surge, 12GB RAM, 256GB Storage)
₹27,999.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
E-COSMOS 5V 1.2W Portable Flexible USB LED Light (Colours May Vary, Small, EC-POF1, Plastic)
₹39.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Wayona Nylon Braided USB to Lightning Fast Charging and Data Sync Cable Compatible for iPhone 13, 12,11, X, 8, 7, 6, 5, iPad Air, Pro, Mini (3 FT Pack of 1, Grey)
₹379.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 20 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Logitech B170 Wireless Mouse, 2.4 GHz with USB Nano Receiver, Optical Tracking, 12-Months Battery Life, Ambidextrous, PC/Mac/Laptop - Black
₹449.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹649.00 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
UnionSine 500GB 2.5" Ultra Slim Portable External Hard Drive HDD-USB 3.0 for PC, Mac, Laptop, PS4, Xbox one,Xbox 360-HD-2510(Black)
$33.78 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ARCTIC MX-6 (4 g) - Ultimate Performance Thermal Paste for CPU, Consoles, Graphics Cards, laptops, Very high Thermal Conductivity, Long Durability, Non-Conductive, CPU Thermal Paste
$7.99 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$67.99 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SanDisk 1TB Portable SSD - Up to 800MB/s, USB-C, USB 3.2 Gen 2, Updated Firmware - External Solid State Drive - SDSSDE30-1T00-G26
$64.99 (as of January 15, 2024 07:26 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)