
")
Transformer-based neural networks have proven nice potential to deal with a number of duties like textual content era, enhancing, and question-answering. In lots of instances, fashions that use extra parameters present higher efficiency measured by perplexity and excessive accuracies of finish duties. That is the primary purpose for the event of bigger fashions in industries. Nonetheless, bigger fashions generally end in a foul efficiency, for instance, the 2B mannequin MiniCPM reveals comparable capabilities to bigger language fashions, similar to Llama2-7B, Mistral-7B, Gemma-7B, and Llama-13B. Furthermore, the scale of high-quality information accessible could not preserve tempo because the computational sources for coaching bigger fashions improve.
Present strategies to beat such shortcomings embody Scaling legal guidelines, Power-based fashions, and Hopfield fashions. In scaling legal guidelines, the efficiency of fashions will increase when there’s a scale-up within the fashions’ measurement and quantity of coaching information. Power-based fashions have turn into well-known as a basic modeling device in several areas of machine studying over the previous few many years. The principle concept of this methodology is to mannequin the neural community utilizing a parameterized chance density perform to current the distribution when it comes to a learnable power perform. The final one is the Hopfield mannequin, wherein the classical Hopfield networks had been developed for instance of associative reminiscence.
Researchers from Central Analysis Institute, 2012 Laboratories Huawei Applied sciences Co., Ltd. launched a theoretical framework centered on the memorization course of and efficiency dynamics of transformer-based language fashions (LMs). Researchers carried out a sequence of experiments utilizing GPT-2 throughout completely different information sizes to beat the indicators of saturation and, on the similar time, educated vanilla Transformer fashions on a dataset consisting of 2M tokens. The outcomes of those experiments validated the theoretical outcomes, providing vital theoretical insights on the optimum cross-entropy-loss that may information and enhance decision-making in mannequin coaching.
A 12-layer transformer LM is educated utilizing the GPT-2 small tokenizer and structure on the OpenWebText dataset. This dataset is just like the WebText dataset used for unique GPT-2 mannequin coaching, which accommodates 9B tokens from 8,013,769 paperwork. Utilizing completely different quantities of knowledge, three fashions are educated the place a subset containing the primary 1% (90M) and 0.1% (9M) of the OpenWebText information is created. Additional, vanilla transformer fashions are educated utilizing a small quantity of high-quality information that accommodates pairs of English sentences in declarative formation and is context-free with a vocabulary measurement of 68 phrases, the place the duty is to transform declarative sentences into questions.
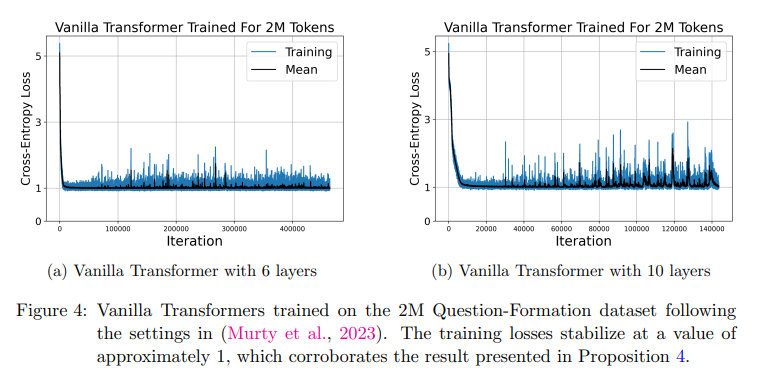
The coaching with 0.1% (9M) of the OpenWebText information exhibits over-fitting, and the coaching loss disappears over iterations. This occurs as a result of the coaching samples aren’t well-separated attributable to which the mannequin power decreases to a sum of some delta features. When the mannequin measurement is concerning the order O(D2) and educated on 90M tokens, the mannequin can obtain related coaching and validation loss in comparison with the setting with 9B tokens. Two vanilla Transformers of 6 and 10 layers are educated utilizing a batch measurement of 8, and the coaching losses stabilize at a price of round 1 as predicted in Proposition.
In conclusion, researchers introduced a theoretical framework centered on the memorization course of and efficiency dynamics of transformer-based language fashions LMs. On this paper, transformer-based networks are modeled utilizing associative reminiscence, and cross-entropy loss is highlighted for mannequin and information sizes. Additionally, experiments are carried out by (a) using GPT-2 of various information sizes and (b) coaching vanilla Transformer fashions on a dataset of 2M tokens. Lastly, a world power perform is created for the layered construction of the transformer fashions utilizing the majorization-minimization method.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 42k+ ML SubReddit

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.