

The exploration into refining the reasoning of huge language fashions (LLMs) marks a big stride in synthetic intelligence analysis, spearheaded by a staff from FAIR at Meta alongside collaborators from Georgia Institute of Know-how and StabilityAI. These researchers have launched into an formidable journey to boost LLMs’ potential to self-improve their reasoning processes on difficult duties corresponding to arithmetic, science, and coding with out counting on exterior inputs.
Historically, LLMs, regardless of their sophistication, usually want to enhance in figuring out exactly when and the way their reasoning wants refinement. This hole led to the event of End result-based Reward Fashions (ORMs), instruments designed to foretell the accuracy of a mannequin’s ultimate reply, hinting at when an adjustment is important. But, a important commentary made by the staff was ORMs’ limitations: they have been discovered to be overly cautious, prompting pointless refinements even when the mannequin’s reasoning steps have been heading in the right direction. This inefficiency prompted a deeper inquiry into extra focused refinement methods.
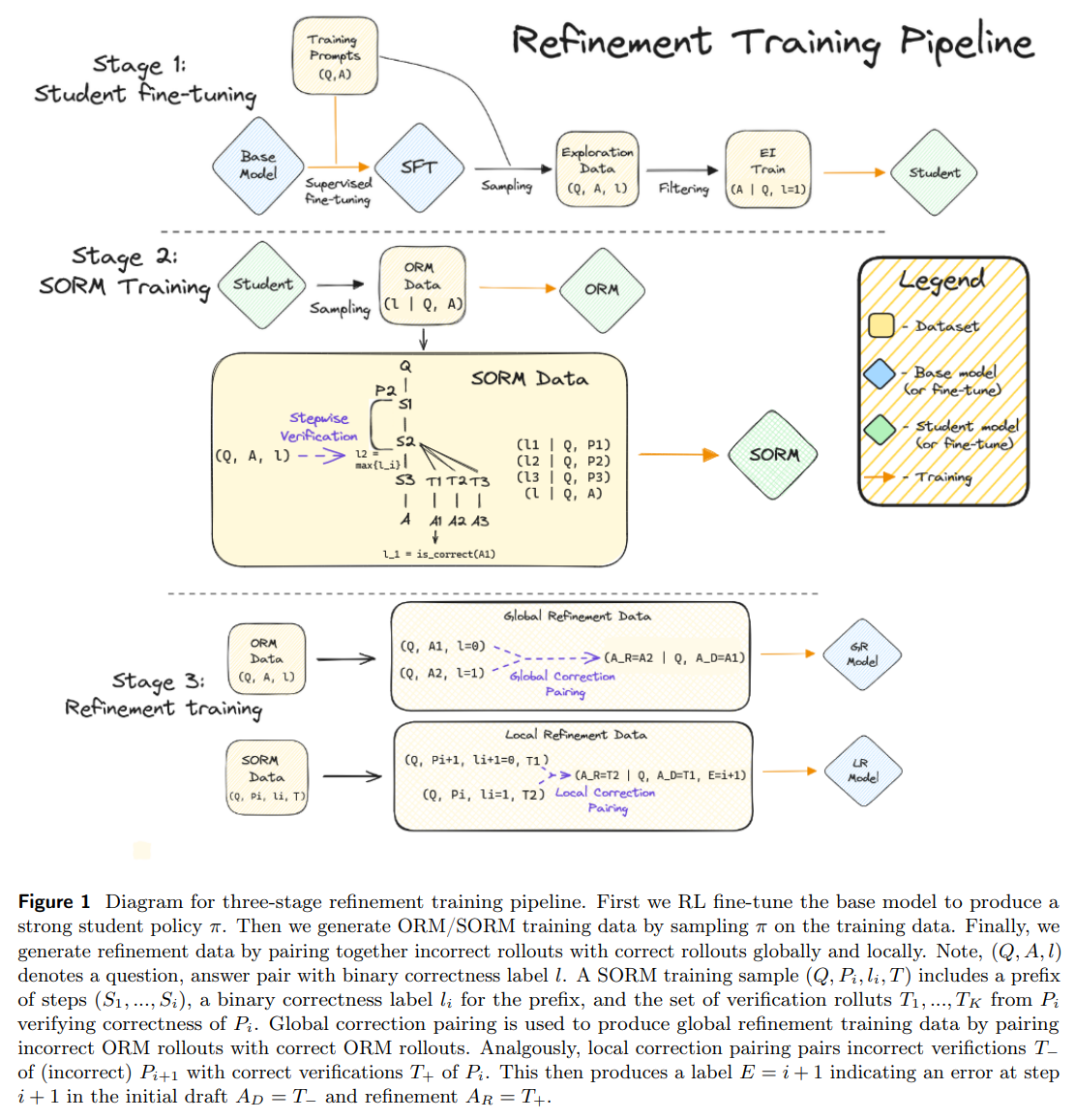
Meet Stepwise ORMs (SORMs), the novel proposition by the analysis staff. Not like their predecessors, SORMs are adept at scrutinizing the correctness of every reasoning step, leveraging artificial information for coaching. This precision permits for a extra nuanced strategy to refinement, distinguishing precisely between legitimate and misguided reasoning steps, thereby streamlining the refinement course of.
The methodology employed by the staff includes a twin refinement mannequin: international and native. The worldwide mannequin assesses the query and a preliminary resolution to suggest a refined reply, whereas the native mannequin zeroes in on particular errors highlighted by a critique. This bifurcation permits for a extra granular strategy to correction, addressing each broad and pinpoint inaccuracies in reasoning. Coaching information for each fashions is synthetically generated, making certain a sturdy basis for the system’s studying course of.
The fruits of this analysis is a placing enchancment in LLM reasoning accuracy. The staff documented a outstanding uplift in efficiency metrics by way of rigorous testing, significantly evident in making use of their methodology to the LLaMA-2 13B mannequin. On a difficult math downside generally known as GSM8K, the accuracy leaped from 53% to a powerful 65% when the fashions have been utilized in a mixed global-local refinement technique, underscored by the ORM’s function as a decision-maker in choosing essentially the most promising resolution.
This breakthrough signifies an development in LLM refinement strategies and the broader context of AI’s problem-solving capabilities. The analysis illuminates a path towards extra autonomous, environment friendly, and clever programs by delineating when and the place refinements are wanted and implementing a strategic correction methodology. The success of this strategy, evidenced by the substantial enchancment in problem-solving accuracy, is a testomony to the potential of artificial coaching and the modern use of reward fashions.
Moreover, the analysis gives a blueprint for future explorations into LLM refinement, suggesting avenues for refining the fashions’ error identification processes and enhancing the sophistication of correction methods. With this basis, the opportunity of LLMs attaining near-human and even superior reasoning talents on advanced duties is introduced nearer to actuality.
The work carried out by the staff from FAIR at Meta, together with their educational collaborators, stands as a beacon of innovation in AI analysis. It propels the capabilities of LLMs ahead and opens up new horizons for the appliance of AI in fixing a few of the most perplexing issues dealing with numerous scientific and technological fields at present. This analysis, subsequently, isn’t just a milestone in AI improvement however a stepping stone in direction of the way forward for clever computing.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

Amazon Basics 3110 Aluminium Lightweight Tripod with Mobile Phone Holder, 3-Way Pan Head | for All Smart Phones, Cameras, Ring Lights, Panel Reflectors, Umbrellas & Flashlights with Carry Bag, 110 cm
₹299.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CP PLUS 3 MP Full HD Smart Wi-fi CCTV Camera | 360° Pan & Tilt | View & Talk | Motion Alert | Night Vision | SD Card (Up to 128 GB) | Alexa & OK Google | 2-Way Talk | IR Distance 10Mtr | CP-E35A
₹1,299.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt BassHeads 100 in-Ear Wired Headphones with Mic (Black)
(as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth in Ear Earphones with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.0(Cosmic Grey)
₹999.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Newly Launched Rockerz 255 ANC Bluetooth Neckband w/ 100 HRS Playback, Spatial Audio, 32dB ANC, ASAP Charge(10Mins=24HRS), 3 Mics AI ENx Tech,13mm Drivers & Dual EQ Modes(Raven Black)
₹1,899.00 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 60W Fast Charging 1.5M Braided Type C to Type C Cable for Smartphones, Tablets, Laptops & Other Type C Devices, PD Technology, 480Mbps Data Sync (RCTT15, Black)
₹199.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 60W / 3A Fast Charging 1.5m Braided Micro USB Cable for Smartphones, Tablets, Laptops & other Micro USB devices, 480Mbps Data Sync, Quick Charge 3.0 (RCM15, Black)
₹149.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Ruffpad 8.5E Re-Writable LCD Writing Pad with Screen 21.5cm (8.5-inch) for Drawing, Playing, Handwriting Gifts for Kids & Adults, India's first notepad to save and share your child's first creatives via Ruffpad app on your Smartphone(Black)
₹199.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Expansion 1TB External HDD - USB 3.0 for Windows and Mac with 3 yr Data Recovery Services, Portable Hard Drive (STKM1000400)
₹4,998.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link TL-WA850RE Single_Band 300Mbps RJ45 Wireless Range Extender, Broadband/Wi-Fi Extender, Wi-Fi Booster/Hotspot with 1 Ethernet Port, Plug and Play, Built-in Access Point Mode, White
₹1,299.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
WD 5TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0050BBK-WESN
$129.99 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG T7 Shield 4TB Portable SSD - 1050MB/s, Rugged, Water & Dust Resistant, for Content Creators - Black
$249.99 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$67.99 (as of February 29, 2024 21:16 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)