

Massive language fashions (LLMs) are advancing the automation of laptop code era in synthetic intelligence. These refined fashions, skilled on in depth datasets of programming languages, have proven exceptional proficiency in crafting code snippets from pure language directions. Regardless of their prowess, aligning these fashions with the nuanced necessities of human programmers stays a big hurdle. Whereas efficient to a level, conventional strategies typically fall brief when confronted with complicated, multi-faceted coding duties, resulting in outputs that, though syntactically appropriate, could solely partially seize the meant performance.
Enter StepCoder, an modern reinforcement studying (RL) framework designed by analysis groups from Fudan NLPLab, Huazhong College of Science and Expertise, and KTH Royal Institute of Expertise to sort out the nuanced challenges of code era. At its core, StepCoder goals to refine the code creation course of, making it extra aligned with human intent and considerably extra environment friendly. The framework distinguishes itself via two most important elements: the Curriculum of Code Completion Subtasks (CCCS) and Advantageous-Grained Optimization (FGO). Collectively, these mechanisms tackle the dual challenges of exploration within the huge area of potential code options and the exact optimization of the code era course of.
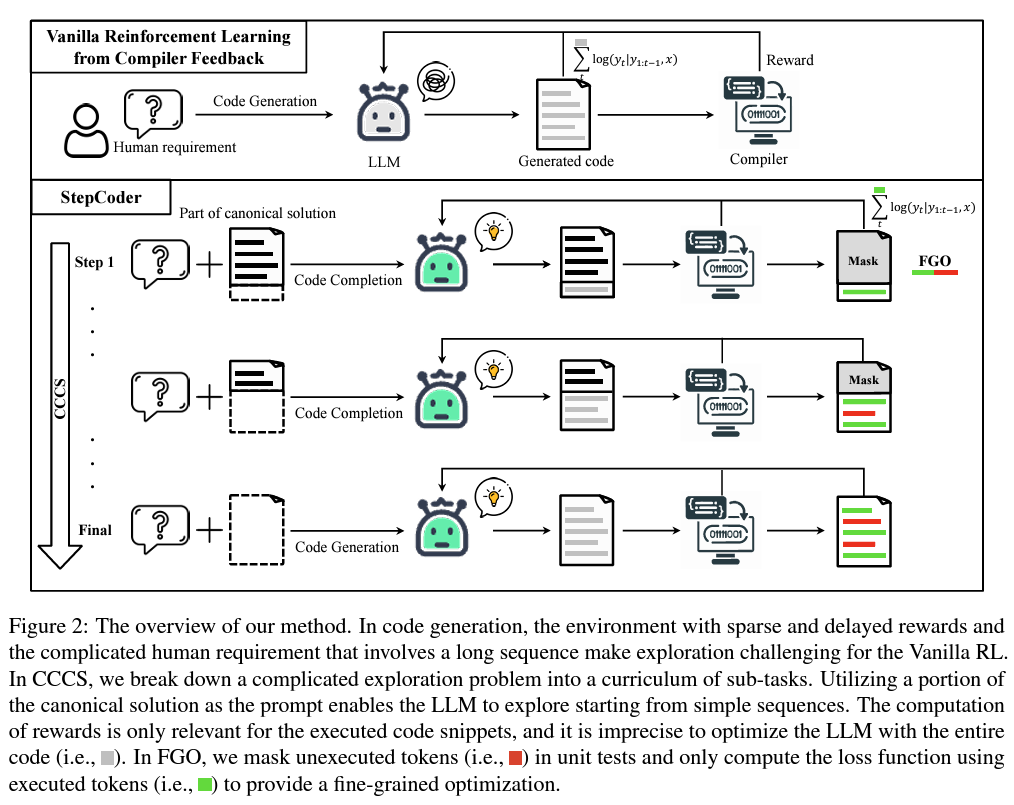
CCCS revolutionizes exploration by segmenting the daunting process of producing lengthy code snippets into manageable subtasks. This systematic breakdown simplifies the mannequin’s studying curve, enabling it to sort out more and more complicated coding necessities step by step with larger accuracy. Because the mannequin progresses, it navigates from finishing less complicated chunks of code to synthesizing complete applications based mostly solely on human-provided prompts. This step-by-step escalation makes the exploration course of extra tractable and considerably enhances the mannequin’s functionality to generate purposeful code from summary necessities.
The FGO part enhances CCCS by honing in on the optimization course of. It leverages a dynamic masking method to focus the mannequin’s studying on executed code segments, disregarding irrelevant parts. This focused optimization ensures that the training course of is instantly tied to the purposeful correctness of the code, as decided by the outcomes of unit exams. The result’s a mannequin that generates syntactically appropriate code and is functionally sound and extra intently aligned with the programmer’s intentions.
The efficacy of StepCoder was rigorously examined in opposition to current benchmarks, showcasing superior efficiency in producing code that met complicated necessities. The framework’s capability to navigate the output area extra effectively and produce functionally correct code units a brand new customary in automated code era. Its success lies within the technological innovation it represents and its method to studying, which intently mirrors the incremental nature of human talent acquisition.
This analysis marks a big milestone in bridging the hole between human programming intent and machine-generated code. StepCoder’s novel method to tackling the challenges of code era highlights the potential for reinforcement studying to rework how we work together with and leverage synthetic intelligence in programming. As we transfer ahead, the insights gleaned from this examine provide a promising path towards extra intuitive, environment friendly, and efficient instruments for code era, paving the way in which for developments that might redefine the panorama of software program growth and synthetic intelligence.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

Redmi 12 5G Jade Black 6GB RAM 128GB ROM
₹12,999.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 25 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Gladiator 1.96" Biggest Display Smart Watch with Bluetooth Calling, Voice Assistant &123 Sports Modes, 8 Unique UI Interactions, SpO2, 24/7 Heart Rate Tracking (Black)
₹1,549.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus 12 (Flowy Emerald, 12 GB RAM, 256GB)
₹64,999.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Buds 3 Truly Wireless Bluetooth Earbuds with Upto 49dB Smart Adaptive Noise Cancellation,Hi-Res Sound Quality,Sliding Volume Control,10mins for 7Hours Fast Charging with Upto 44Hrs Playback
₹5,499.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP 680 Original Ink Advantage Cartridge (Black)
₹886.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,299.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP X1000 Wired USB Mouse with 3 Handy Buttons, Fast-Moving Scroll Wheel and Optical Sensor works on most Surfaces, 3 years warranty
₹279.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link TL-WA850RE Single_Band 300Mbps RJ45 Wireless Range Extender, Broadband/Wi-Fi Extender, Wi-Fi Booster/Hotspot with 1 Ethernet Port, Plug and Play, Built-in Access Point Mode, White
₹1,299.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
amazon basics Type A to Micro USB Braided Cable | 3A/18W Fast Charging and 480 Mbps Data Transfer Speed | 1.2m, Tangle Free Cable
₹109.00 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 7 7800X3D 8-Core, 16-Thread Desktop Processor
$385.86 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 1TB Portable External Hard Drive USB 3.0, Black - HDTB510XK3AA
$49.99 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CORSAIR 4000D AIRFLOW Tempered Glass Mid-Tower ATX Case - High-Airflow - Cable Management System - Spacious Interior - Two Included 120 mm Fans - Black
$79.99 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 11, 2024 21:38 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)