

The research diverges from earlier approaches by concentrating on aligning lengthy context, particularly by fine-tuning language fashions to interpret prolonged consumer prompts. Challenges embrace the absence of in depth datasets for supervised fine-tuning, difficulties in dealing with various size distributions effectively throughout a number of GPUs, and the need for strong benchmarks to evaluate the fashions’ capabilities with real-world queries. The goal is to reinforce LLMs’ capability to deal with prolonged contexts by fine-tuning them based mostly on comparable enter sequence lengths.
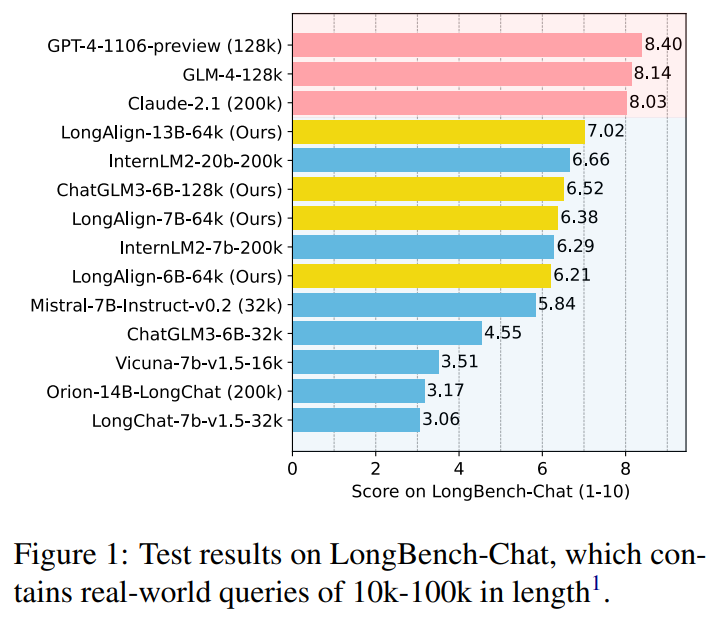
Researchers from Tsinghua College and Zhipu.AI have developed LongAlign, a complete strategy for aligning LLMs to deal with lengthy contexts successfully. They assemble a various, lengthy instruction-following dataset utilizing Self-Instruct, protecting duties from varied sources. To deal with coaching inefficiencies resulting from various size distributions, they make use of packing and sorted batching methods and a loss weighting technique to stability contributions. Additionally they introduce LongBench-Chat, an analysis benchmark comprising open-ended questions of 10k-100k size.
Lengthy-context scaling seeks to increase the context size of present LLMs for dealing with long-context duties. Strategies fall into two classes: these requiring fine-tuning on longer sequences and those who don’t. Non-fine-tuning strategies use sliding window consideration or token compression methods however don’t match fine-tuned efficiency. Wonderful-tuned approaches contain extending place encoding and continuous retraining. Aligning the mannequin with instruction-following information, termed supervised fine-tuning, is essential for efficient interplay in chat interfaces. Challenges embrace information, coaching, and analysis strategies. Whereas some work offers lengthy instruction information, it wants extra thorough evaluation.
The LongAlign recipe affords a complete strategy for successfully dealing with lengthy contexts in LLMs. It entails establishing a various lengthy instruction-following dataset utilizing Self-Instruct, adopting environment friendly coaching methods like packing and sorted batching, and introducing the LongBench-Chat benchmark for analysis. LongAlign addresses challenges by introducing a loss weighting technique throughout packing coaching, which balances loss contributions throughout totally different sequences. Findings present that packing and sorted batching improve coaching effectivity twofold whereas sustaining good efficiency, and loss weighting considerably improves efficiency on lengthy instruction duties throughout packing coaching.
Experiments exhibit that LongAlign improves LLM efficiency on long-context duties by as much as 30% with out compromising proficiency on shorter duties. Moreover, they discover that information amount and variety considerably influence efficiency, whereas lengthy instruction information enhances long-context process efficiency with out affecting short-context dealing with. The coaching methods speed up coaching with out compromising efficiency, with the loss weighting method additional bettering long-context efficiency by 10%. LongAlign achieves improved efficiency on lengthy instruction duties by way of the packing and sorted batching methods, which double the coaching effectivity whereas sustaining good efficiency.
In conclusion, the research goals to optimize lengthy context alignment, specializing in information, coaching strategies, and analysis. LongAlign makes use of Self-Instruct to create various lengthy instruction information and fine-tune fashions effectively by way of packing, loss weighting, or sorted batching. The LongBench-Chat benchmark assesses instruction-following capability in sensible long-context situations. Managed experiments spotlight the importance of information amount, range, and applicable coaching strategies for reaching optimum efficiency. LongAlign outperforms present strategies by as much as 30% in lengthy context duties whereas sustaining proficiency briefly duties. The open sourcing of LongAlign fashions, code, and information promotes additional analysis and exploration on this discipline.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.

CP PLUS 3 MP Full HD Smart Wi-fi CCTV Camera | 360° Pan & Tilt | View & Talk | Motion Alert | Night Vision | SD Card (Up to 128 GB) | Alexa & OK Google | 2-Way Talk | IR Distance 10Mtr | CP-E35A
₹1,299.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Ninja Call Pro Plus 1.83" Smart Watch with Bluetooth Calling, AI Voice Assistance, 100 Sports Modes IP67 Rating, 240 * 280 Pixel High Resolution
₹1,199.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TECNO POP 8 (Gravity Black,(8GB*+64GB)| 90Hz Punch Hole Display with Dynamic Port & Dual Speakers with DTS| 5000mAh Battery |10W Type-C| Side Fingerprint Sensor| Octa-Core Processor
₹6,599.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes 200 Plus TWS Earbuds w/ 100 Hours Playback, Quad Mics ENx Technology, 13mm Drivers, Beast Mode(50ms Low Latency), ASAP Charge(5 Mins=60 Mins), IWP Tech w/BT v5.3 & IPX5(Carbon Black)
₹1,599.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 Lite 5G (Chromatic Gray, 8GB RAM, 256GB Storage)
₹19,999.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP 680 Original Ink Advantage Cartridge (Black)
₹886.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Expansion 1TB External HDD - USB 3.0 for Windows and Mac with 3 yr Data Recovery Services, Portable Hard Drive (STKM1000400)
₹4,973.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,299.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L 1.2M POR-1401 Fast Charging 3A 8 Pin USB Cable with Charge & Sync Function (White)
₹129.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 25 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG T7 Shield 4TB Portable SSD - 1050MB/s, Rugged, Water & Dust Resistant, for Content Creators - Black
$249.99 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM750e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$79.99 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermal Grizzly Kryonaut, High Performance Thermal Paste for Cooling All Processors, Graphics Cards and Heat Sinks in Computers and Consoles -1.0 Gram
$8.99 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
UnionSine 500GB 2.5" Ultra Slim Portable External Hard Drive HDD-USB 3.0 for PC, Mac, Laptop, PS4, Xbox one,Xbox 360-HD-2510(Black)
$33.78 (as of February 14, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)