

The rising availability of digital textual content in various languages and scripts presents a big problem for pure language processing (NLP). Multilingual pre-trained language fashions (mPLMs) usually battle to deal with transliterated information successfully, resulting in efficiency degradation. Addressing this situation is essential for bettering cross-lingual switch studying and making certain correct NLP purposes throughout varied languages and scripts, which is important for world communication and data processing.
Present strategies, together with fashions like XLM-R and Glot500, carry out effectively with textual content of their authentic scripts however battle considerably with transliterated textual content as a consequence of ambiguities and tokenization points. These limitations degrade their efficiency in cross-lingual duties, making them much less efficient when dealing with textual content transformed into a standard script similar to Latin. The shortcoming of those fashions to precisely interpret transliterations poses a big barrier to their utility in multilingual settings.
Researchers from the Middle for Data and Language Processing, LMU Munich, and Munich Middle for Machine Studying (MCML) launched TRANSMI, a framework designed to boost mPLMs for transliterated information with out requiring further coaching. TRANSMI modifies current mPLMs utilizing three merge modes—Min-Merge, Common-Merge, and Max-Merge—to include transliterated subwords into their vocabularies, thereby addressing transliteration ambiguities and bettering cross-lingual process efficiency.
TRANSMI integrates new subwords tailor-made for transliterated information into the mPLMs’ vocabularies, significantly excelling within the Max-Merge mode for high-resource languages. The framework is examined utilizing datasets that embrace transliterated variations of texts in scripts similar to Cyrillic, Arabic, and Devanagari, exhibiting that TRANSMI-modified fashions outperform their authentic variations in varied duties like sentence retrieval, textual content classification, and sequence labeling. This modification ensures that fashions retain their authentic capabilities whereas adapting to the nuances of transliterated textual content, thus enhancing their total efficiency in multilingual NLP purposes.
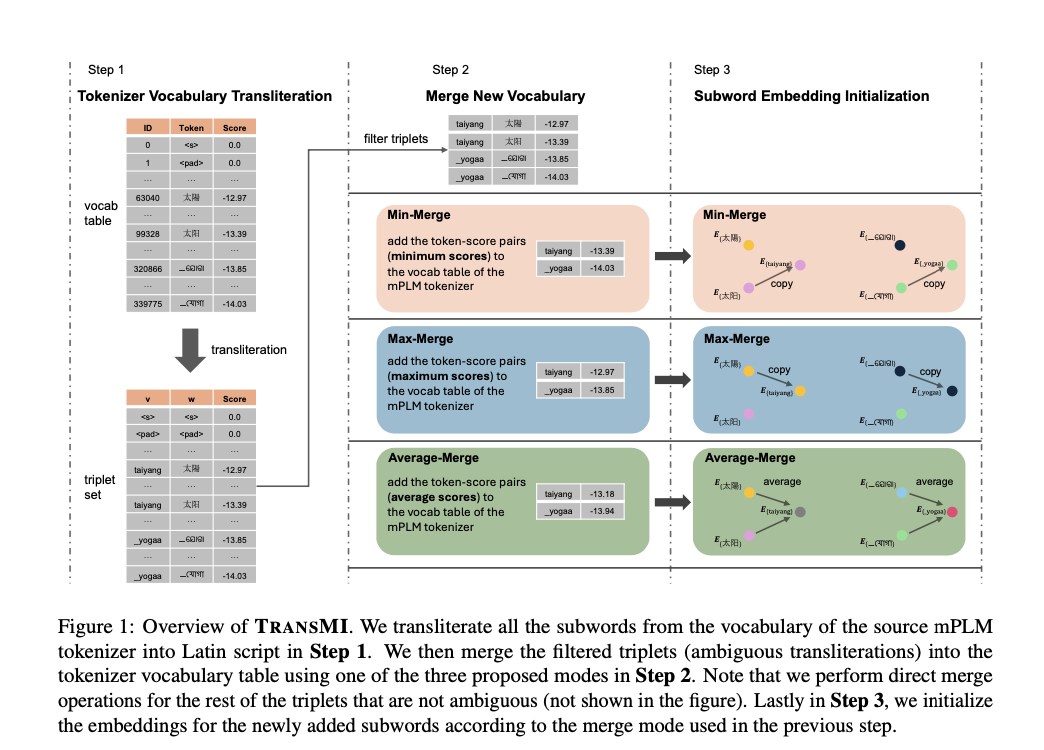
The datasets used to validate TRANSMI span a wide range of scripts, offering a complete evaluation of its effectiveness. For instance, the FURINA mannequin utilizing Max-Merge mode exhibits vital enhancements in sequence labeling duties, demonstrating TRANSMI’s functionality to deal with phonetic scripts and mitigate points arising from transliteration ambiguities. This method ensures that mPLMs can course of a variety of languages extra precisely, enhancing their utility in multilingual contexts.
The outcomes point out that TRANSMI-modified fashions obtain increased accuracy in comparison with their unmodified counterparts. For example, the FURINA mannequin with Max-Merge mode demonstrates notable efficiency enhancements in sequence labeling duties throughout totally different languages and scripts, showcasing clear good points in key efficiency metrics. These enhancements spotlight TRANSMI’s potential as an efficient instrument for enhancing multilingual NLP fashions, making certain higher dealing with of transliterated information and resulting in extra correct cross-lingual processing.
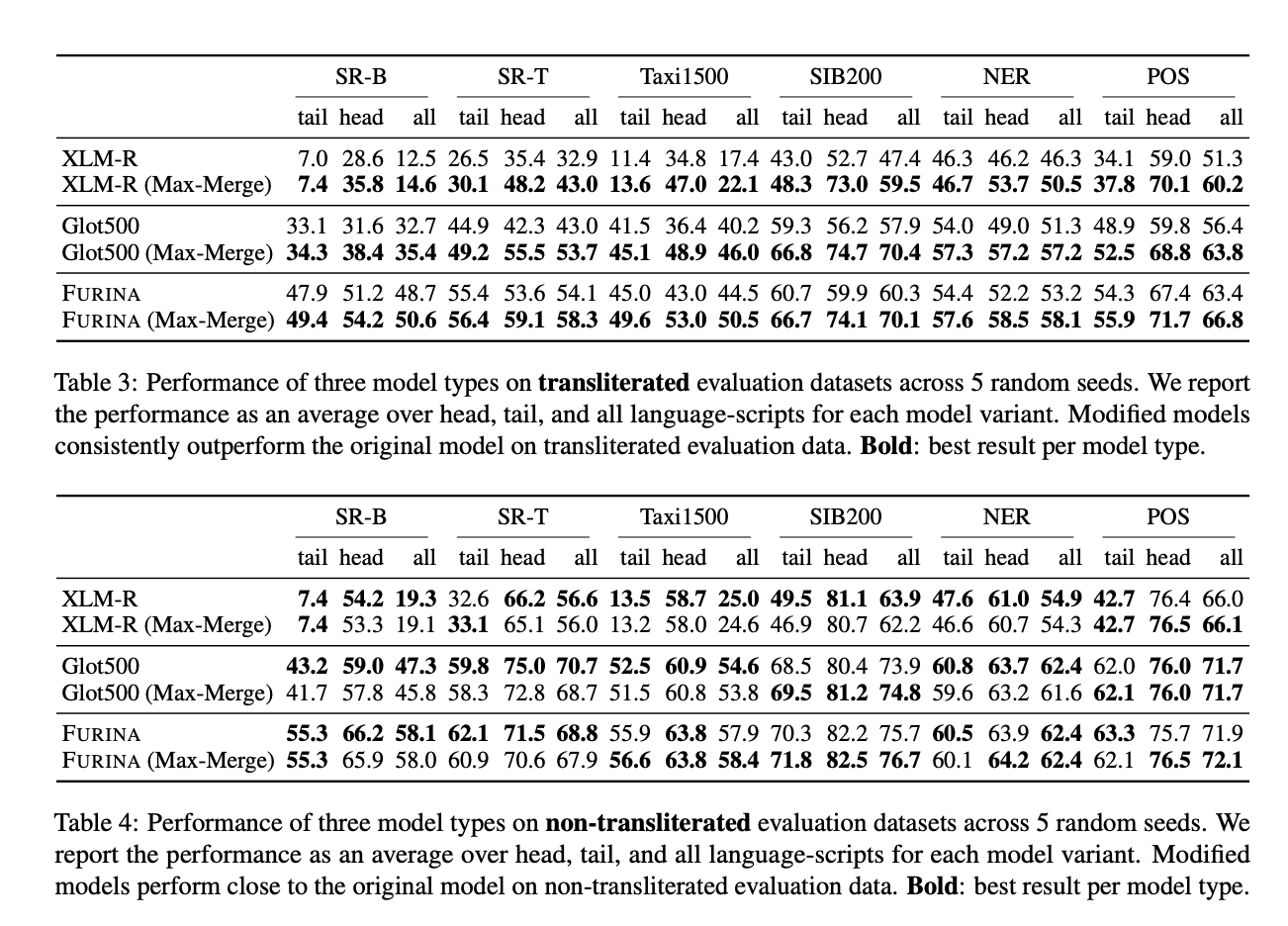
In conclusion, TRANSMI addresses the crucial problem of bettering mPLMs’ efficiency on transliterated information by modifying current fashions with out further coaching. This framework enhances mPLMs’ skill to course of transliterations, resulting in vital enhancements in cross-lingual duties. TRANSMI presents a sensible and progressive resolution to a posh drawback, offering a robust basis for additional developments in multilingual NLP and bettering world communication and data processing.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.