

In deep studying, the hunt for effectivity has led to a paradigm shift in how we finetune large-scale fashions. The analysis spearheaded by Soufiane Hayou, Nikhil Ghosh, and Bin Yu from the College of California, Berkeley, introduces a major enhancement to the Low-Rank Adaptation (LoRA) technique, termed LoRA+. This novel method is designed to optimize the finetuning technique of fashions characterised by their huge variety of parameters, which frequently run into the tens or a whole bunch of billions.
Adapting huge fashions to particular duties has been difficult attributable to computational burden. Researchers have navigated this by freezing the unique weights of the mannequin and adjusting solely a small subset of parameters via strategies like immediate tuning, adapters, and LoRA. The final, specifically, entails coaching a low-rank matrix added to the pretrained weights, thus lowering the variety of parameters that want adjustment.
As recognized by the UC Berkeley staff, the crux of the inefficiency within the current LoRA technique lies within the uniform studying charge utilized to the adapter matrices A and B. Given the vastness of the mannequin width, greater than a one-size-fits-all method to the educational charge is required, resulting in suboptimal function studying. The introduction of LoRA+ addresses this by implementing differentiated studying charges for matrices A and B, optimized via a set ratio. This nuanced method ensures a tailor-made studying charge that higher fits the size and dynamics of enormous fashions.
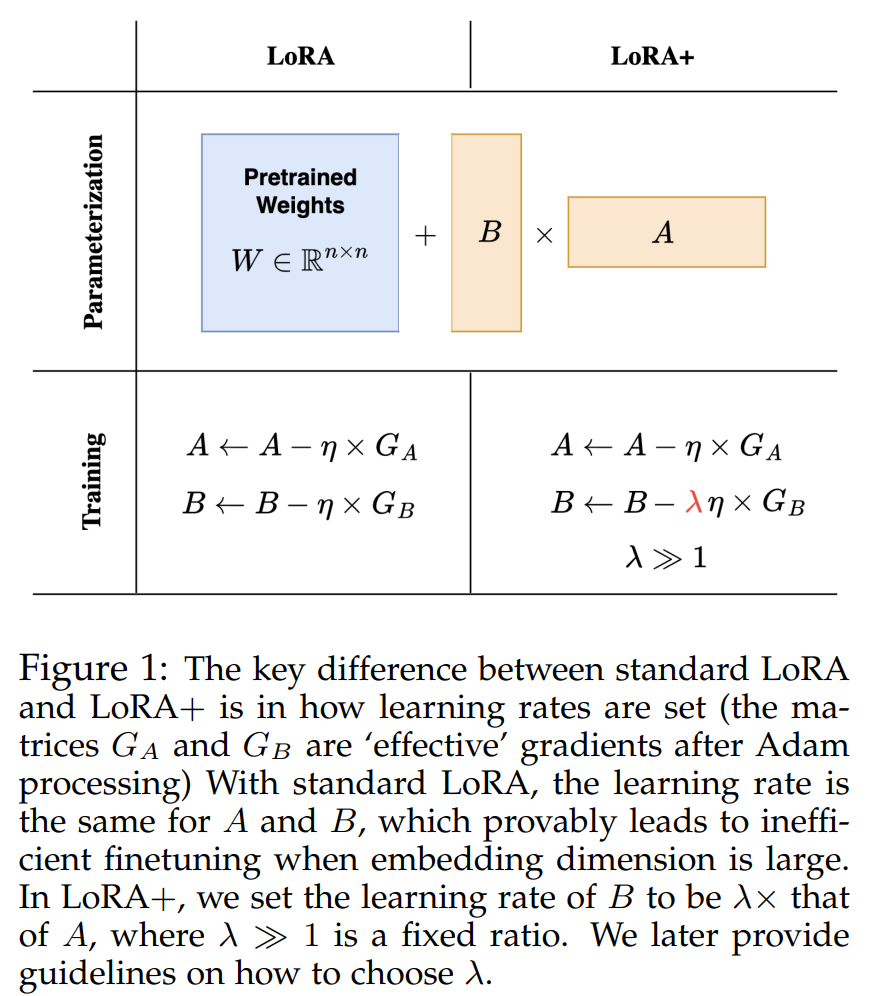
The staff’s rigorous experimentation gives strong backing for the prevalence of LoRA+ over the normal LoRA technique. Via complete testing throughout numerous benchmarks, together with these involving Roberta-base and GPT-2 fashions, LoRA+ persistently showcased enhanced efficiency and finetuning velocity. Notably, the strategy achieved efficiency enhancements starting from 1% to 2% and a finetuning speedup of as much as roughly 2X whereas sustaining the identical computational prices. Such empirical proof underscores the potential of LoRA+ to revolutionize the finetuning course of for giant fashions.
Particularly, when utilized to the Roberta-base mannequin throughout totally different duties, LoRA+ achieved outstanding check accuracies, with a notable enhance in ‘more durable’ duties equivalent to MNLI and QQP in comparison with simpler ones like SST2 and QNLI. This variation in efficiency amplifies the significance of environment friendly function studying, significantly in advanced duties the place the pretrained mannequin’s alignment with the finetuning process is much less easy. Moreover, the Llama-7b mannequin’s adaptation utilizing LoRA+ on the MNLI dataset and the Flan-v2 dataset solidified the strategy’s efficacy, showcasing important efficiency features.
The methodology behind LoRA+, involving setting totally different studying charges for LoRA adapter matrices with a set ratio, isn’t just a technical tweak however a strategic overhaul of the finetuning course of. This method permits for a extra refined adaptation of the mannequin to the specificities of the duty at hand, enabling a stage of customization beforehand unattainable with uniform studying charge changes.
In sum, the introduction of LoRA+ by the analysis staff from UC Berkeley marks a pivotal development in deep studying. By addressing the inefficiencies within the LoRA technique via an progressive adjustment of studying charges, LoRA+ paves the best way for simpler and environment friendly finetuning large-scale fashions. This breakthrough enhances the efficiency and velocity of mannequin adaptation and broadens the horizon for future analysis and purposes in optimizing the finetuning processes of neural networks. The findings from this research, substantiated by rigorous empirical proof, invite a reevaluation of current practices and supply a promising avenue for leveraging the total potential of enormous fashions in numerous purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

boAt Rockerz 255 Pro+ Bluetooth Neckband with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.2(Teal Green)
₹999.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Noise Twist Go Round dial Smartwatch with BT Calling, 1.39" Display, Metal Build, 100+ Watch Faces, IP68, Sleep Tracking, 100+ Sports Modes, 24/7 Heart Rate Monitoring (Jet Black)
₹1,299.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Logitech B170 Wireless Mouse, 2.4 GHz with USB Nano Receiver, Optical Tracking, 12-Months Battery Life, Ambidextrous, PC/Mac/Laptop - Black
₹595.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 5G (Aqua Surge, 8GB RAM, 128GB Storage)
₹24,999.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Expansion 1TB External HDD - USB 3.0 for Windows and Mac with 3 yr Data Recovery Services, Portable Hard Drive (STKM1000400)
₹4,998.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Mpad Mouse Mat 230X190X3mm Gaming Mouse Pad, Non-Slip Rubber Base, Waterproof Surface, Premium-Textured, Compatible with Laser and Optical Mice(Universe Black)
₹99.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹679.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS Zeb-Dash Plus 2.4GHz High Precision Wireless Mouse with up to 1600 DPI, Power Saving Mode, Nano Receiver and Plug & Play Usage - USB
₹203.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 5TB External Hard Drive HDD – USB 3.0 for PC, Mac, PS4, & Xbox - 1-Year Rescue Service (STGX5000400), Black
$129.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Gotega External DVD Drive, USB 3.0 Portable +/-RW , DVD Player for CD ROM Burner Compatible with Laptop Desktop PC Windows Linux OS Apple Mac Black
$19.99 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 7 7800X3D 8-Core, 16-Thread Desktop Processor
$364.00 (as of February 28, 2024 21:15 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)