

In recent times, LMMs have quickly expanded, leveraging CLIP as a foundational imaginative and prescient encoder for strong visible representations and LLMs as versatile instruments for reasoning throughout numerous modalities. Nevertheless, whereas LLMs have grown to over 100 billion parameters, the imaginative and prescient fashions they depend on have to be larger, hindering their potential. Scaling up contrastive language-image pretraining (CLIP) is crucial to boost each imaginative and prescient and multimodal fashions, bridging the hole and enabling simpler dealing with of numerous knowledge varieties.
Researchers from the Beijing Academy of Synthetic Intelligence and Tsinghua College have unveiled EVA-CLIP-18B, the most important open-source CLIP mannequin but, boasting 18 billion parameters. Regardless of coaching on simply 6 billion samples, it achieves a powerful 80.7% zero-shot top-1 accuracy throughout 27 picture classification benchmarks, surpassing prior fashions like EVA-CLIP. Notably, this development is achieved with a modest dataset of two billion image-text pairs, brazenly obtainable and smaller than these utilized in different fashions. EVA-CLIP-18B showcases the potential of EVA-style weak-to-strong visible mannequin scaling, with hopes of fostering additional analysis in imaginative and prescient and multimodal basis fashions.
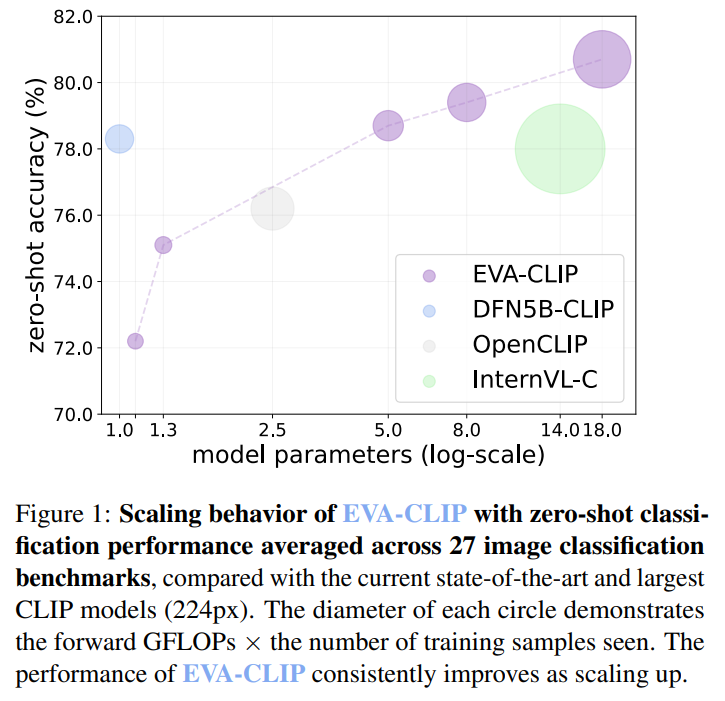
EVA-CLIP-18B is the most important and strongest open-source CLIP mannequin, with 18 billion parameters. It outperforms its predecessor EVA-CLIP (5 billion parameters) and different open-source CLIP fashions by a big margin when it comes to zero-shot top-1 accuracy on 27 picture classification benchmarks. The rules of EVA and EVA-CLIP information the scaling-up process of EVA-CLIP-18B. The EVA philosophy follows a weak-to-strong paradigm, the place a small EVA-CLIP mannequin serves because the imaginative and prescient encoder initialization for a bigger EVA-CLIP mannequin. This iterative scaling course of stabilizes and accelerates the coaching of bigger fashions.
EVA-CLIP-18B, an 18-billion-parameter CLIP mannequin, is skilled on a 2 billion image-text pairs dataset from LAION-2B and COYO-700M. Following the EVA and EVA-CLIP rules, it employs a weak-to-strong paradigm, the place a smaller EVA-CLIP mannequin initializes a bigger one, stabilizing and expediting coaching. Analysis throughout 33 datasets, together with picture and video classification and image-text retrieval, demonstrates its efficacy. The scaling course of entails distilling information from a small EVA-CLIP mannequin to a bigger EVA-CLIP, with the coaching dataset principally fastened to showcase the effectiveness of the scaling philosophy. Notably, the method yields sustained efficiency good points, exemplifying the effectiveness of progressive weak-to-strong scaling.
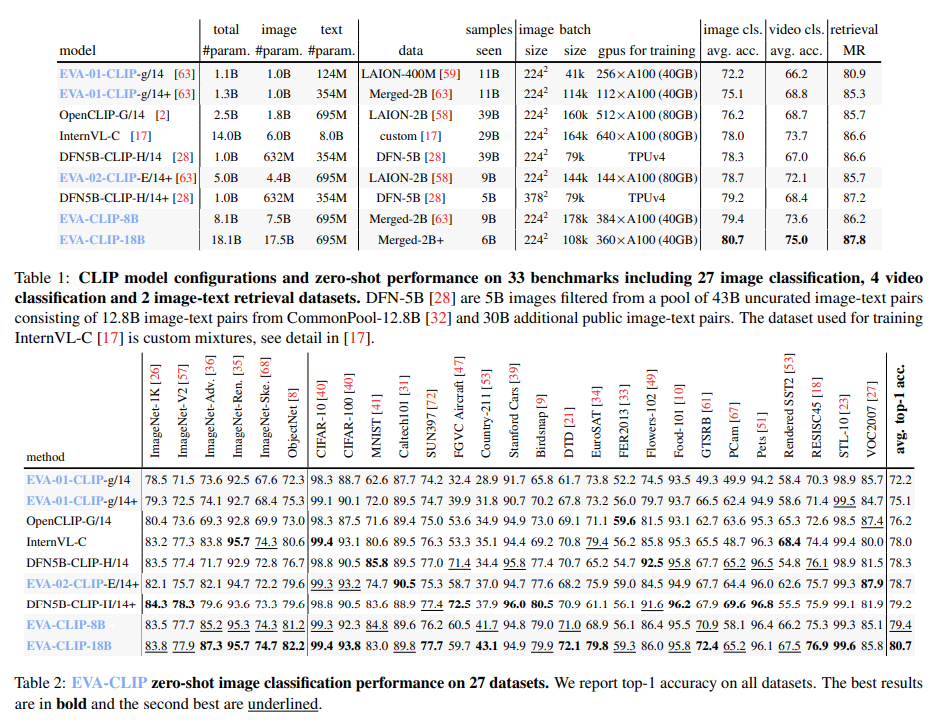
EVA-CLIP-18B, boasting 18 billion parameters, showcases excellent efficiency throughout numerous image-related duties. It achieves a powerful 80.7% zero-shot top-1 accuracy throughout 27 picture classification benchmarks, surpassing its predecessor and different CLIP fashions by a big margin. Furthermore, linear probing on ImageNet-1K outperforms rivals like InternVL-C with a mean top-1 accuracy of 88.9. Zero-shot image-text retrieval on Flickr30K and COCO datasets achieves a mean recall of 87.8, considerably surpassing rivals. EVA-CLIP-18B displays robustness throughout completely different ImageNet variants, demonstrating its versatility and excessive efficiency throughout 33 broadly used datasets.
In conclusion, EVA-CLIP-18B is the most important and highest-performing open-source CLIP mannequin, boasting 18 billion parameters. Making use of EVA’s weak-to-strong imaginative and prescient scaling precept achieves distinctive zero-shot top-1 accuracy throughout 27 picture classification benchmarks. This scaling method constantly improves efficiency with out reaching saturation, pushing the boundaries of imaginative and prescient mannequin capabilities. Notably, EVA-CLIP-18B displays robustness in visible representations, sustaining efficiency throughout numerous ImageNet variants, together with adversarial ones. Its versatility and effectiveness are demonstrated throughout a number of datasets, spanning picture classification, image-text retrieval, and video classification duties, marking a big development in CLIP mannequin capabilities.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.

Redmi 13C (Starshine Green, 6GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹8,999.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt BassHeads 100 in-Ear Wired Headphones with Mic (Black)
₹369.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C 5G (Startrail Silver, 4GB RAM, 128GB Storage) | MediaTek Dimensity 6100+ 5G | 90Hz Display
₹10,999.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 3A Fast Charging 1.5m Braided Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, 480Mbps Data Sync, Quick Charge 3.0 (RCT15A, Black)
₹199.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes Atom 81 TWS Earbuds with Upto 50H Playtime, Quad Mics ENx™ Tech, 13MM Drivers,Super Low Latency(50ms), ASAP™ Charge, BT v5.3(Opal Black)
₹1,099.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF 25 Pieces Highly Flexible Silicone Cable Protectors, Charger Cable Protector, Charger Protector, Wire Protector, Cable Protector, Charging Cable Protector (Colorful)
₹99.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹299.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
amazon basics Type A to Micro USB Braided Cable | 3A/18W Fast Charging and 480 Mbps Data Transfer Speed | 1.2m, Tangle Free Cable
₹109.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Konnect L 1.2M POR-1401 Fast Charging 3A 8 Pin USB Cable with Charge & Sync Function (White)
₹129.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Sounce Fast Phone Charging Cable & Data Sync USB Cable Compatible for iPhone 13, 12,11, X, 8, 7, 6, 5, iPad Air, Pro, Mini & iOS Devices
₹199.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ARCTIC MX-6 (4 g) - Ultimate Performance Thermal Paste for CPU, Consoles, Graphics Cards, laptops, Very high Thermal Conductivity, Long Durability, Non-Conductive, CPU Thermal Paste
$6.15 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG SSD T7 Portable External Solid State Drive 1TB, Up to USB 3.2 Gen 2, Reliable Storage for Gaming, Students, Professionals, MU-PC1T0T/AM, Gray
$94.99 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
WD 5TB Elements Portable HDD, External Hard Drive, USB 3.0 for PC & Mac, Plug and Play Ready - WDBU6Y0050BBK-WESN
$129.99 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)