

Giant language fashions, or LLMs, have remodeled how machines perceive and generate textual content, making interactions more and more human-like. These fashions are on the forefront of technological developments, tackling complicated duties from answering inquiries to summarizing huge quantities of textual content. Regardless of their prowess, a urgent query looms over their reasoning skills: How dependable and constant are they of their logic and conclusions?
A specific space of concern is self-contradictory reasoning, a state of affairs the place the mannequin’s logic doesn’t align with its conclusions. This discrepancy raises doubts in regards to the soundness of the fashions’ reasoning capabilities, even once they churn out right solutions. Conventional analysis metrics centered closely on outcomes like accuracy fall in need of scrutinizing the reasoning course of. This oversight implies that a mannequin is perhaps rewarded for the precise solutions, which had been arrived at via flawed logic, thereby masking the underlying points in reasoning consistency.
Researchers from the College of Southern California have launched a novel method to scrutinize and detect situations of self-contradictory reasoning in LLMs to deal with this hole. This technique goes past surface-level efficiency indicators, delving into the fashions’ reasoning processes to determine inconsistencies. It categorizes these inconsistencies, providing a granular view of the place and the way fashions’ logic falters. This method is a big leap ahead, promising a extra holistic analysis of LLMs by spotlighting the alignment, or lack thereof, between their reasoning and predictions.
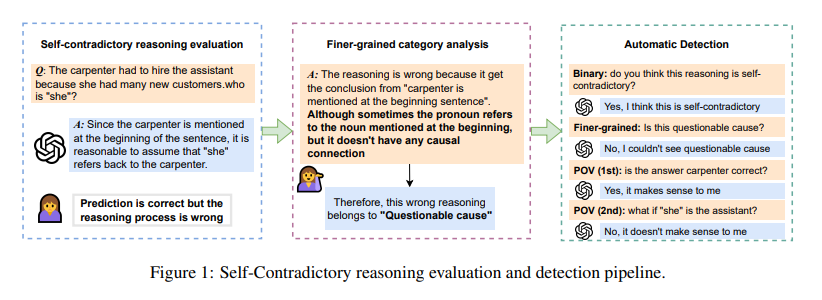
The methodology assesses reasoning throughout varied datasets, pinpointing inconsistencies that earlier metrics would possibly overlook. This analysis is essential in understanding how a lot fashions will be trusted to make logical, constant conclusions. Significantly, the examine harnesses the facility of GPT-4, amongst different fashions, to probe the depths of reasoning high quality. It fastidiously examines completely different reasoning errors, classifying them into distinct classes. This classification illuminates the precise areas the place fashions battle and units the stage for focused enhancements in mannequin coaching and analysis practices.
Regardless of attaining excessive accuracy on quite a few duties, LLMs, together with GPT-4, exhibit a propensity for self-contradictory reasoning. This alarming commentary signifies that fashions typically resort to incorrect or incomplete logic pathways to reach at right solutions. Such a paradox underscores a vital flaw in relying solely on outcome-based analysis metrics like accuracy, which may obscure the underlying reasoning high quality of LLMs. This discovery requires a paradigm shift in how we assess and perceive the capabilities of those superior fashions.
The examine’s efficiency analysis and detection of self-contradictory reasoning spotlight the pressing want for extra nuanced and complete analysis frameworks. These frameworks should prioritize the integrity of reasoning processes, guaranteeing that fashions are correct, logically sound, and dependable. The analysis factors to a big hole in present analysis strategies, advocating for a holistic method that considers the correctness of solutions and the logical coherence of the reasoning resulting in these solutions.
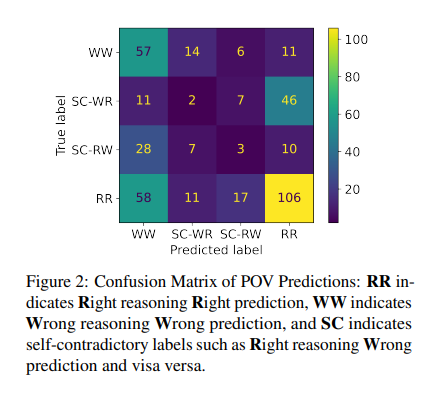
In conclusion, this analysis casts a highlight on the vital concern of self-contradictory reasoning in LLMs, urging a reevaluation of how we gauge these fashions’ capabilities. Proposing an in depth framework for assessing reasoning high quality paves the way in which for extra dependable and constant AI methods. This endeavor is about critiquing present fashions and laying the groundwork for future developments. It’s a name to motion for researchers and builders to prioritize logical consistency and reliability within the subsequent technology of LLMs, guaranteeing they’re highly effective and reliable.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our Telegram ChannelYou may additionally like our FREE AI Programs….
Hiya, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m enthusiastic about know-how and need to create new merchandise that make a distinction.

Apple iPhone 13 (128GB) - Blue
₹49,200.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple 20W USB-C Power Adapter (for iPhone, iPad & AirPods)
₹1,599.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Noise Twist Go Round dial Smartwatch with BT Calling, 1.39" Display, Metal Build, 100+ Watch Faces, IP68, Sleep Tracking, 100+ Sports Modes, 24/7 Heart Rate Monitoring (Jet Black)
₹1,299.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Bullets Z2 Bluetooth Wireless in Ear Earphones with Mic, Bombastic Bass - 12.4 Mm Drivers, 10 Mins Charge - 20 Hrs Music, 30 Hrs Battery Life (Magico Black)
₹1,499.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth Neckband with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.2(Teal Green)
₹999.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP v236w USB 2.0 64GB Pen Drive, Metal, Silver
₹429.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 60W Fast Charging 1.5M Braided Type C to Type C Cable for Smartphones, Tablets, Laptops & other Type C devices, PD Technology, 480Mbps Data Sync (RCTT15, Black)
₹199.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000DPI, LED Tracking, Scrolling Wheel, Plug and Play
₹269.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹899.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 4TB Portable External Hard Drive USB 3.0, Black - HDTB540XK3CA
$99.59 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Rioddas External CD/DVD Drive for Laptop USB 3.0 CD/DVD Player Portable +/-RW Burner CD ROM Reader Rewriter Writer Disk Duplicator Compatible with Laptop Desktop PC Windows Apple Mac Pro Macbook Linux
$19.99 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Crucial RAM 16GB DDR4 3200MHz CL22 (or 2933MHz or 2666MHz) Laptop Memory CT16G4SFRA32A
$36.99 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CORSAIR 4000D AIRFLOW Tempered Glass Mid-Tower ATX Case - High-Airflow - Cable Management System - Spacious Interior - Two Included 120 mm Fans - Black
$89.99 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)