

We launched Ray help public preview final yr and since then, tons of of Databricks clients have been utilizing it for number of use instances comparable to multi-model hierarchical forecasting, LLM finetuning, and Reinforcement studying. At present, we’re excited to announce the final availability of Ray help on Databricks. Ray is now included as a part of the Machine Studying Runtime ranging from model 15.0 onwards, making it a first-class providing on Databricks. Clients can begin a Ray cluster with none further installations, permitting you to get began utilizing this highly effective framework inside the built-in suite of merchandise that Databricks has to supply, comparable to Unity Catalog, Delta Lake, MLflow, and Apache Spark
A Harmonious Integration: Ray and Spark on Databricks
The final availability of Ray on Databricks expands the selection of operating distributed ML AI workloads on Databricks and new Python workloads. It creates a cohesive ecosystem the place logical parallelism and information parallelism thrive collectively. Ray enhances Databricks’ choices by providing an extra, various logical parallelism strategy to processing Python code that isn’t as closely depending on information partitioning as ML workloads which can be optimized for Spark are.
One of the vital thrilling elements of this integration lies within the interoperability with Spark DataFrames. Historically, transitioning information between completely different processing frameworks might be cumbersome and resource-intensive, typically involving pricey write-read cycles. Nevertheless, with Ray on Databricks, the platform facilitates direct, in-memory information transfers between Spark and Ray, eliminating the necessity for intermediate storage or costly information translation processes. This interoperability ensures that information may be manipulated effectively in Spark after which handed seamlessly to Ray, all with out leaving the data-efficient and computationally wealthy setting of Databricks.
“At Marks & Spencer, forecasting is on the coronary heart of our enterprise, enabling use instances comparable to stock planning, gross sales probing, and provide chain optimization. This requires strong and scalable pipelines to ship our use instances. At M&S, we have harnessed the facility of Ray on Databricks to experiment and ship production-ready pipelines from mannequin tuning, coaching, and prediction. This has enabled us to confidently ship end-to-end pipelines utilizing Spark’s scalable information processing capabilities with Ray’s scalable ML workloads.”
— Joseph Sarsfield, Senior ML Engineer, Marks and Spencer
Empowering New Functions with Ray on Databricks
The combination between Ray and Databricks opens doorways to a myriad of purposes, every benefiting from the distinctive strengths of each frameworks:
- Reinforcement Studying: Deploying superior fashions for autonomous autos and robotics, benefiting from Ray’s distributed computing utilizing RLlib.
- Distributed Customized Python Functions: Scaling customized Python purposes throughout clusters for duties requiring advanced computation.
- Deep Studying Coaching: Providing environment friendly options for deep studying duties in laptop imaginative and prescient and language fashions, leveraging Ray’s distributed nature.
- Excessive-Efficiency Computing (HPC): Addressing large-scale duties like genomics, physics, and monetary calculations with Ray’s capability for high-performance computing workloads.
- Distributed Conventional Machine Studying: Enhancing the distribution of conventional machine studying fashions, like scikit-learn or forecasting fashions, throughout clusters.
- Enhancing Python Workflows: Distributing customized Python duties beforehand restricted to single nodes, together with these requiring advanced orchestration or communication between duties.
- Hyperparameter Search: Offering alternate options to Hyperopt for hyperparameter tuning, using Ray Tune for extra environment friendly searches.
- Leveraging the Ray Ecosystem: Integrating with the expansive ecosystem of open-source libraries and instruments inside Ray, enriching the event setting.
- Massively Parallel Knowledge Processing: Combining Spark and Ray to enhance upon UDFs or foreach batch features – very best for processing non-tabular information like audio or video.
Beginning a Ray Cluster
Initiating a Ray cluster on Databricks is remarkably easy, requiring just a few traces of code. This seamless initiation, coupled with Databricks’ scalable infrastructure, ensures that purposes transition easily from improvement to manufacturing, leveraging each the computational energy of Ray and the information processing capabilities of Spark on Databricks.
Ranging from Databricks Machine Studying Runtime 15.0, Ray is pre-installed and totally arrange on the cluster. You can begin a Ray cluster utilizing the next code as steerage (relying in your cluster configuration, it would be best to modify these arguments to suit the accessible sources in your cluster):
from ray.util.spark import setup_ray_cluster, shutdown_ray_cluster
setup_ray_cluster(
num_worker_nodes=2,
num_cpus_per_node=4,
autoscale = True,
collect_log_to_path="/dbfs/path/to/ray_collected_logs"
)
# Cross any customized configuration to ray.init()
ray.init(ignore_reinit_error=True)This strategy begins a Ray cluster on prime of the extremely scalable and managed Databricks Spark cluster. As soon as began and accessible, this Ray cluster can seamlessly combine with the opposite Databricks options, infrastructure, and instruments that Databricks gives. You may as well leverage enterprise options comparable to dynamic autoscaling, launching a mix of on-demand and spot situations, and cluster insurance policies. You may simply change from an interactive cluster throughout code authoring to a job cluster for long-running jobs.
To go from operating Ray on a laptop computer to hundreds of nodes on the cloud is only a matter of including just a few traces of code utilizing the previous setup_ray_cluster operate. Databricks manages the scalability of the Ray cluster by way of the underlying Spark cluster and is so simple as altering the variety of specified employee nodes and sources devoted to the Ray cluster.
“Over the previous yr and a half, we’ve also used Ray in our software. Our expertise with Ray has been overwhelmingly constructive, because it has constantly delivered dependable efficiency with none surprising errors or points. Its affect on our software’s velocity efficiency has been notably noteworthy, with the implementation of Ray Cluster in Databricks taking part in an important position in lowering processing occasions by at the very least half. In some situations, we’ve noticed a powerful enchancment of over 4X. All of this with none further value. Furthermore, the Ray Dashboard has been invaluable in offering insights into reminiscence consumption for every activity, permitting us to ensure we’ve the optimized configuration for our software”
— Juliana Negrini de Araujo, Senior Machine Studying Engineer, Cummins
Enhancing Knowledge Science on Databricks: Ray with MLflow and Unity Catalog
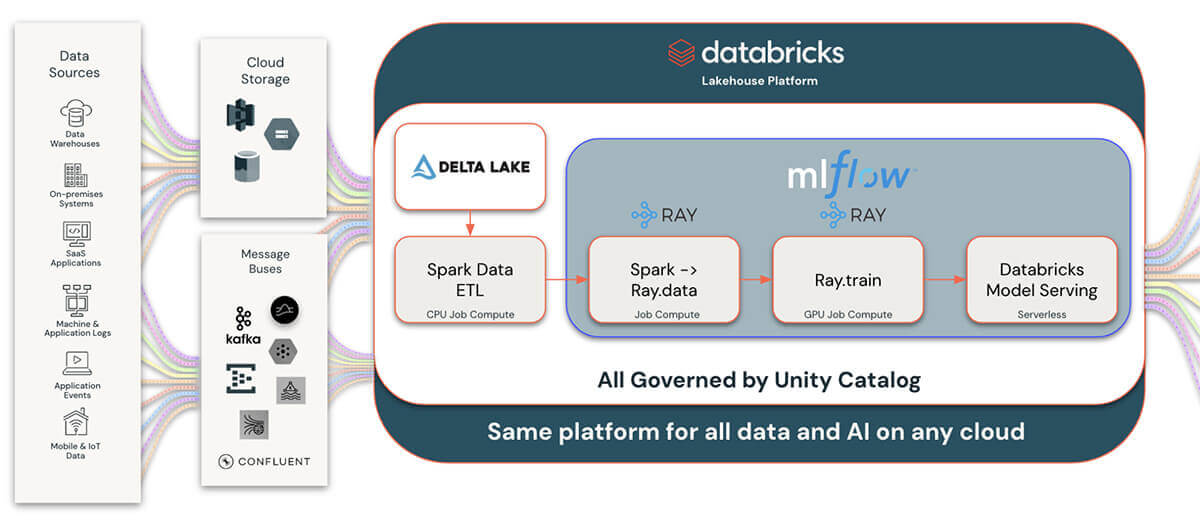
Databricks enhances information science workflows by integrating Ray with three key managed providers: MLflow for lifecycle administration, Unity Catalog for information governance, and Mannequin Serving for MLOps. This integration streamlines the monitoring, optimizing, and deploying of machine studying fashions developed with Ray, leveraging MLflow for seamless mannequin lifecycle administration. Knowledge scientists can effectively monitor experiments, handle mannequin variations, and deploy fashions into manufacturing, all inside Databricks’ unified platform.
Unity Catalog additional helps this ecosystem by providing strong information governance, enabling clear lineage, and sharing machine studying artifacts created with Ray. This ensures information high quality and compliance throughout all property, fostering efficient collaboration inside safe and controlled environments.
Combining Unity Catalog and our Delta Lake integration with Ray permits for a lot wider and extra complete integration with the remainder of the information and AI panorama. This provides Ray customers and builders an unparalleled skill to combine with extra information sources than ever. Writing information that’s generated from Ray purposes to Delta Lake and Unity Catalog additionally permits for connecting to the huge ecosystem of knowledge and enterprise intelligence instruments.
This mix of Ray, MLflow, Unity Catalog, and Databricks Mannequin Serving on Databricks simplifies and accelerates the deployment of superior information science options, offering a complete, ruled platform for innovation and collaboration in machine studying tasks.
Get Began with Ray on Databricks
The collaboration of Ray and Databricks is greater than a mere integration; it presents a good coupling of two frameworks that not solely excel at their respective strengths however, when built-in collectively, provide a uniquely highly effective answer to your AI improvement wants. This integration not solely permits builders and information scientists to faucet into the huge capabilities of Databricks’ platform, together with MLflow, Delta Lake, and Unity Catalog but additionally to combine with Ray’s computational effectivity and suppleness seamlessly. To study extra, see the total information to utilizing Ray on Databricks.

Apple iPhone 13 (128GB) - Starlight
₹49,499.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord Buds 2r True Wireless in Ear Earbuds with Mic, 12.4mm Drivers, Playback:Upto 38hr case,4-Mic Design, IP55 Rating [Deep Grey]
₹1,999.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme Buds 2 Wired in Ear Earphones with Mic (Black)
₹599.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Apple 20W USB-C Power Adapter (for iPhone, iPad & AirPods)
₹1,699.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C (Stardust Black, 6GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹8,699.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,399.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 101 Wired Optical Mouse with 1200 DPI, Plug & Play, Hi-Optical Tracking, 1.25M Cable Length, 30 Million Click Life(Black)
₹117.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Portronics Toad 23 Wireless Optical Mouse with 2.4GHz, USB Nano Dongle, Optical Orientation, Click Wheel, Adjustable DPI(Black)
₹296.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Logitech B170 Wireless Mouse, 2.4 GHz with USB Nano Receiver, Optical Tracking, 12-Months Battery Life, Ambidextrous, PC/Mac/Laptop - Black
₹595.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹649.00 (as of April 25, 2024 16:03 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
UnionSine 1TB Ultra Slim Portable External Hard Drive HDD-USB 3.0 for PC, Mac, Laptop, PS4, Xbox one,Xbox 360-Super Fast Transmission-HD-2510(Black)
$46.61 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair RM1000e (2023) Fully Modular Low-Noise Power Supply - ATX 3.0 & PCIe 5.0 Compliant - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black
$139.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Samsung 990 EVO SSD 1TB, PCIe Gen 4x4, Gen 5x2 M.2 2280 NVMe Internal Solid State Drive, Speeds Up to 5,000MB/s, Upgrade Storage for PC Computer, Laptop, MZ-V9E1T0B/AM, Black
$89.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$69.99 (as of April 23, 2024 16:02 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)