

Picture by Creator
One of many fields that underpins information science is machine studying. So, if you wish to get into information science, understanding machine studying is without doubt one of the first steps you might want to take.
However the place do you begin? You begin by understanding the distinction between the 2 important sorts of machine studying algorithms. Solely after that, we will speak about particular person algorithms that must be in your precedence record to be taught as a newbie.
The primary distinction between the algorithms relies on how they be taught.

Picture by Creator
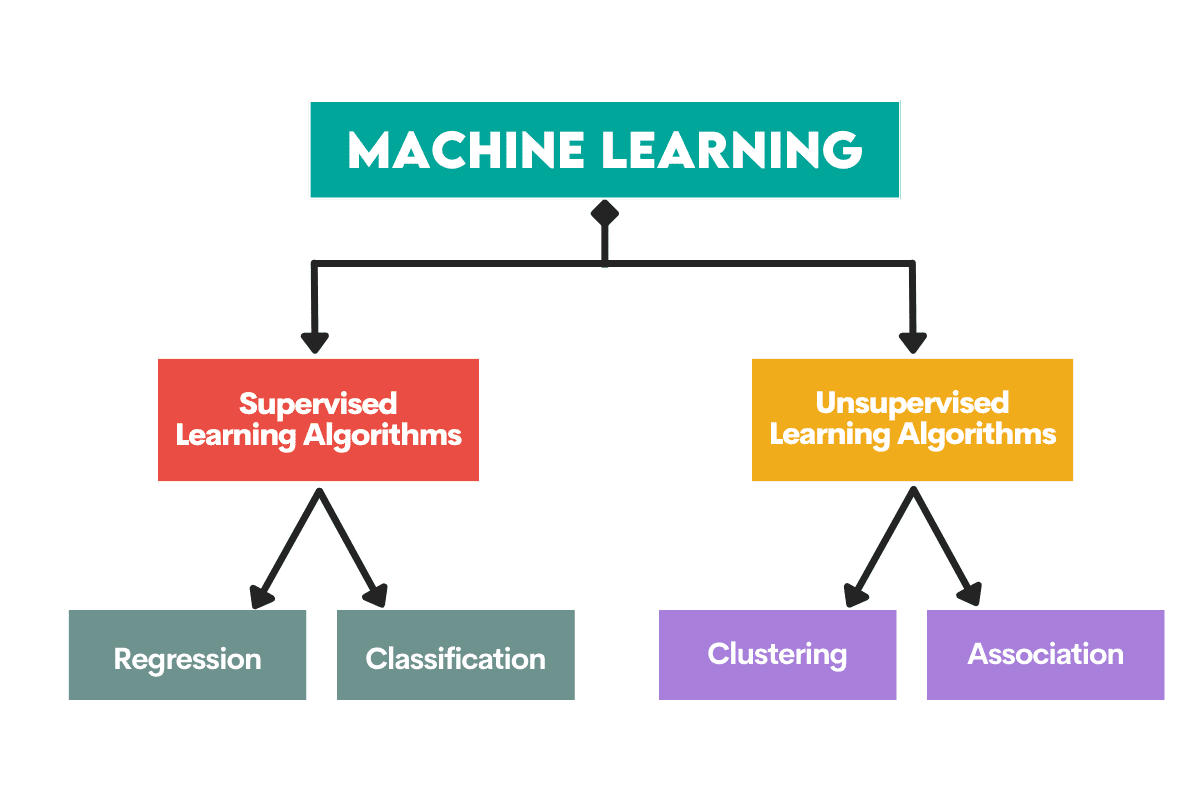
Supervised studying algorithms are skilled on a labeled dataset. This dataset serves as a supervision (therefore the title) for studying as a result of some information it incorporates is already labeled as an accurate reply. Based mostly on this enter, the algorithm can be taught and apply that studying to the remainder of the info.
Alternatively, unsupervised studying algorithms be taught on an unlabeled dataset, that means they have interaction find patterns in information with out people giving instructions.
You possibly can learn extra intimately about machine studying algorithms and sorts of studying.
There are additionally another sorts of machine studying, however not for inexperienced persons.
Algorithms are employed to unravel two important distinct issues inside every sort of machine studying.
Once more, there are some extra duties, however they don’t seem to be for inexperienced persons.
Picture by Creator
Supervised Studying Duties
Regression is the duty of predicting a numerical worth, referred to as steady end result variable or dependent variable. The prediction relies on the predictor variable(s) or impartial variable(s).
Take into consideration predicting oil costs or air temperature.
Classification is used to foretell the class (class) of the enter information. The end result variable right here is categorical or discrete.
Take into consideration predicting if the mail is spam or not spam or if the affected person will get a sure illness or not.
Unsupervised Studying Duties
Clustering means dividing information into subsets or clusters. The purpose is to group information as naturally as doable. Because of this information factors throughout the similar cluster are extra comparable to one another than to information factors from different clusters.
Dimensionality discount refers to lowering the variety of enter variables in a dataset. It principally means lowering the dataset to only a few variables whereas nonetheless capturing its essence.
Right here’s an summary of the algorithms I’ll cowl.
Picture by Creator
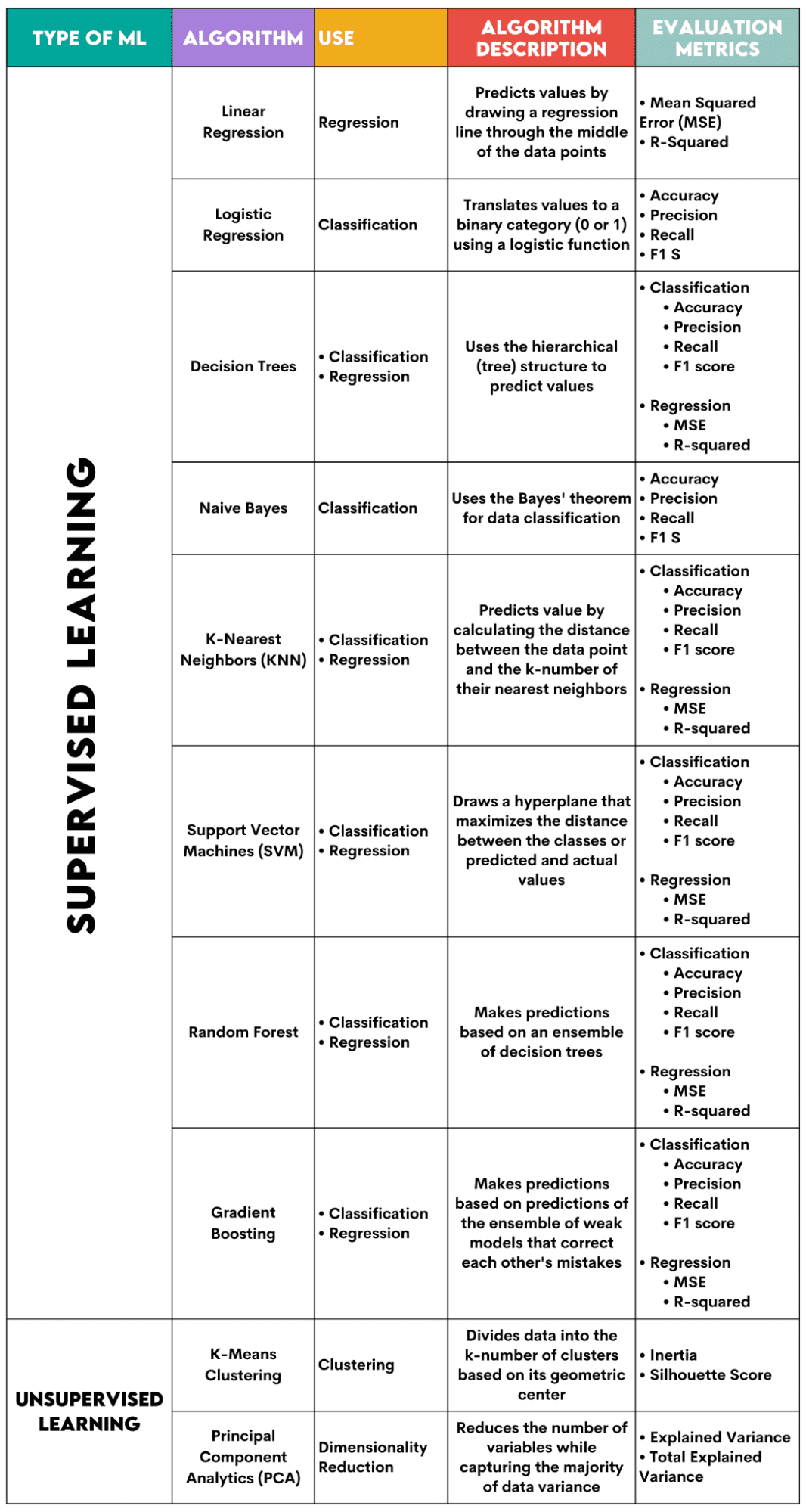
Supervised Studying Algorithms
When selecting the algorithm in your downside, it’s essential to know what process the algorithm is used for.
As a knowledge scientist, you’ll most likely apply these algorithms in Python utilizing the scikit-learn library. Though it does (nearly) every thing for you, it’s advisable that not less than the final ideas of every algorithm’s interior workings.
Lastly, after the algorithm is skilled, you must consider how properly it performs. For that, every algorithm has some customary metrics.
1. Linear Regression
Used For: Regression
Description: Linear regression attracts a straight line referred to as a regression line between the variables. This line goes roughly by means of the center of the info factors, thus minimizing the estimation error. It reveals the anticipated worth of the dependent variable primarily based on the worth of the impartial variables.
Analysis Metrics:
- Imply Squared Error (MSE): Represents the typical of the squared error, the error being the distinction between precise and predicted values. The decrease the worth, the higher the algorithm efficiency.
- R-Squared: Represents the variance proportion of the dependent variable that may be predicted by the impartial variable. For this measure, you must try to get to 1 as shut as doable.
2. Logistic Regression
Used For: Classification
Description: It makes use of a logistic operate to translate the info values to a binary class, i.e., 0 or 1. That is completed utilizing the edge, often set at 0.5. The binary end result makes this algorithm excellent for predicting binary outcomes, corresponding to YES/NO, TRUE/FALSE, or 0/1.
Analysis Metrics:
- Accuracy: The ratio between right and whole predictions. The nearer to 1, the higher.
- Precision: The measure of mannequin accuracy in constructive predictions; proven because the ratio between right constructive predictions and whole anticipated constructive outcomes. The nearer to 1, the higher.
- Recall: It, too, measures the mannequin’s accuracy in constructive predictions. It’s expressed as a ratio between right constructive predictions and whole observations made within the class. Learn extra about these metrics right here.
- F1 Rating: The harmonic imply of the mannequin’s recall and precision. The nearer to 1, the higher.
3. Choice Timber
Used For: Regression & Classification
Description: Choice bushes are algorithms that use the hierarchical or tree construction to foretell worth or a category. The basis node represents the entire dataset, which then branches into choice nodes, branches, and leaves primarily based on the variable values.
Analysis Metrics:
- Accuracy, precision, recall, and F1 rating -> for classification
- MSE, R-squared -> for regression
4. Naive Bayes
Used For: Classification
Description: This can be a household of classification algorithms that use Bayes’ theorem, that means they assume the independence between options inside a category.
Analysis Metrics:
- Accuracy
- Precision
- Recall
- F1 rating
5. Okay-Nearest Neighbors (KNN)
Used For: Regression & Classification
Description: It calculates the gap between the take a look at information and the k-number of the closest information factors from the coaching information. The take a look at information belongs to a category with a better variety of ‘neighbors’. Relating to the regression, the anticipated worth is the typical of the okay chosen coaching factors.
Analysis Metrics:
- Accuracy, precision, recall, and F1 rating -> for classification
- MSE, R-squared -> for regression
6. Assist Vector Machines (SVM)
Used For: Regression & Classification
Description: This algorithm attracts a hyperplane to separate totally different lessons of knowledge. It’s positioned on the largest distance from the closest factors of each class. The upper the gap of the info level from the hyperplane, the extra it belongs to its class. For regression, the precept is comparable: hyperplane maximizes the gap between the anticipated and precise values.
Analysis Metrics:
- Accuracy, precision, recall, and F1 rating -> for classification
- MSE, R-squared -> for regression
7. Random Forest
Used For: Regression & Classification
Description: The random forest algorithm makes use of an ensemble of choice bushes, which then decide forest. The algorithm’s prediction relies on the prediction of many choice bushes. Knowledge can be assigned to a category that receives essentially the most votes. For regression, the anticipated worth is a median of all of the bushes’ predicted values.
Analysis Metrics:
- Accuracy, precision, recall, and F1 rating -> for classification
- MSE, R-squared -> for regression
8. Gradient Boosting
Used For: Regression & Classification
Description: These algorithms use an ensemble of weak fashions, with every subsequent mannequin recognizing and correcting the earlier mannequin’s errors. This course of is repeated till the error (loss operate) is minimized.
Analysis Metrics:
- Accuracy, precision, recall, and F1 rating -> for classification
- MSE, R-squared -> for regression
Unsupervised Studying Algorithms
9. Okay-Means Clustering
Used For: Clustering
Description: The algorithm divides the dataset into k-number clusters, every represented by its centroid or geometric heart. By means of the iterative means of dividing information right into a k-number of clusters, the purpose is to attenuate the gap between the info factors and their cluster’s centroid. Alternatively, it additionally tries to maximise the gap of those information factors from the opposite clusters’s centroid. Merely put, the info belonging to the identical cluster must be as comparable as doable and as totally different as information from different clusters.
Analysis Metrics:
- Inertia: The sum of the squared distance of every information level’s distance from the closest cluster centroid. The decrease the inertia worth, the extra compact the cluster.
- Silhouette Rating: It measures the cohesion (information’s similarity inside its personal cluster) and separation (information’s distinction from different clusters) of the clusters. The worth of this rating ranges from -1 to +1. The upper the worth, the extra the info is well-matched to its cluster, and the more severe it’s matched to different clusters.
10. Principal Part Analytics (PCA)
Used For: Dimensionality Discount
Description: The algorithm reduces the variety of variables utilized by developing new variables (principal elements) whereas nonetheless making an attempt to maximise the captured variance of the info. In different phrases, it limits information to its commonest elements whereas not dropping the essence of the info.
Analysis Metrics:
- Defined Variance: The proportion of the variance coated by every principal part.
- Whole Defined Variance: The proportion of the variance coated by all principal elements.
Machine studying is an important a part of information science. With these ten algorithms, you’ll cowl the most typical duties in machine studying. In fact, this overview offers you solely a normal concept of how every algorithm works. So, that is only a begin.
Now, you might want to learn to implement these algorithms in Python and remedy actual issues. In that, I like to recommend utilizing scikit-learn. Not solely as a result of it’s a comparatively easy-to-use ML library but additionally due to its intensive supplies on ML algorithms.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from prime firms. Nate writes on the newest traits within the profession market, offers interview recommendation, shares information science tasks, and covers every thing SQL.

USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹699.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
POCO C55 (Cool Blue, 6GB RAM, 128GB Storage)
₹6,499.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme Buds T300 Truly Wireless in-Ear Earbuds with 30dB ANC, 360° Spatial Audio Effect, 12.4mm Dynamic Bass Boost Driver with Dolby Atmos Support, Upto 40Hrs Battery and Fast Charging (Dome Green)
₹2,099.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oneplus Bullets Z2 Bluetooth Wireless in Ear Earphones with Mic, Bombastic Bass - 12.4 mm Drivers, 10 Mins Charge - 20 Hrs Music, 30 Hrs Battery Life, IP55 Dust and Water Resistant (Magico Black)
₹1,499.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord Buds 2 TWS in Ear Earbuds with Mic,Upto 25dB ANC 12.4mm Dynamic Titanium Drivers, Playback:Upto 36hr case, 4-Mic Design, IP55 Rating, Fast Charging [Thunder Gray]
₹2,499.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹667.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth Wireless in Ear Earphones with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.2(Moon White)
₹1,299.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,399.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹649.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Mpad Mouse Mat 230X190X3mm Gaming Mouse Pad, Non-Slip Rubber Base, Waterproof Surface, Premium-Textured, Compatible with Laser and Optical Mice(Universe Black)
₹99.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)Auto Amazon Links: No products found.