
We reside in an period the place the machine studying mannequin is at its peak. In comparison with many years in the past, most individuals would by no means have heard about ChatGPT or Synthetic Intelligence. Nevertheless, these are the matters that folks preserve speaking about. Why? As a result of the values given are so important in comparison with the hassle.
The breakthrough of AI in recent times might be attributed to many issues, however one in every of them is the massive language mannequin (LLM). Many textual content technology AI folks use are powered by the LLM mannequin; For instance, ChatGPT makes use of their GPT mannequin. As LLM is a crucial matter, we must always find out about it.
This text will talk about Giant Language Fashions in 3 problem ranges, however we’ll solely contact on some elements of LLMs. We’d solely differ in a means that permits each reader to grasp what LLM is. With that in thoughts, let’s get into it.
Within the first stage, we assume the reader doesn’t learn about LLM and will know somewhat concerning the subject of knowledge science/machine studying. So, I might briefly introduce AI and Machine Studying earlier than transferring to the LLMs.
Synthetic Intelligence is the science of growing clever laptop applications. It’s meant for this system to carry out clever duties that people might do however doesn’t have limitations on human organic wants. Machine studying is a subject in synthetic intelligence specializing in knowledge generalization research with statistical algorithms. In a means, Machine Studying is attempting to attain Synthetic Intelligence through knowledge research in order that this system can carry out intelligence duties with out instruction.
Traditionally, the sphere that intersects between laptop science and linguistics known as the Pure Language Processing subject. The sphere primarily issues any exercise of machine processing to the human textual content, equivalent to textual content paperwork. Beforehand, this subject was solely restricted to the rule-based system nevertheless it turned extra with the introduction of superior semi-supervised and unsupervised algorithms that permit the mannequin to study with none course. One of many superior fashions to do that is the Language Mannequin.
The language mannequin is a probabilistic NLP mannequin to carry out many human duties equivalent to translation, grammar correction, and textual content technology. The previous type of the language mannequin makes use of purely statistical approaches such because the n-gram methodology, the place the idea is that the chance of the subsequent phrase relies upon solely on the earlier phrase’s fixed-size knowledge.
Nevertheless, the introduction of Neural Community has dethroned the earlier method. A man-made neural community, or NN, is a pc program mimicking the human mind’s neuron construction. The Neural Community method is sweet to make use of as a result of it could deal with complicated sample recognition from the textual content knowledge and deal with sequential knowledge like textual content. That’s why the present Language Mannequin is often based mostly on NN.
Giant Language Fashions, or LLMs, are machine studying fashions that study from an enormous variety of knowledge paperwork to carry out general-purpose language technology. They’re nonetheless a language mannequin, however the large variety of parameters realized by the NN makes them thought of massive. In layperson’s phrases, the mannequin might carry out how people write by predicting the subsequent phrases from the given enter phrases very properly.
Examples of LLM duties embrace language translation, machine chatbot, query answering, and plenty of extra. From any sequence of knowledge enter, the mannequin might establish relationships between the phrases and generate output appropriate from the instruction.
Virtually the entire Generative AI merchandise that boast one thing utilizing textual content technology are powered by the LLMs. Huge merchandise like ChatGPT, Google’s Bard, and plenty of extra are utilizing LLMs as the premise of their product.
The reader has knowledge science data however must study extra concerning the LLM at this stage. On the very least, the reader can perceive the phrases used within the knowledge subject. At this stage, we’d dive deeper into the bottom structure.
As defined beforehand, LLM is a Neural Community mannequin educated on large quantities of textual content knowledge. To grasp this idea additional, it might be helpful to grasp how neural networks and deep studying work.
Within the earlier stage, we defined {that a} neural neuron is a mannequin miming the human mind’s neural construction. The principle component of the Neural Community is the neurons, usually known as nodes. To elucidate the idea higher, see the everyday Neural Community structure within the picture beneath.
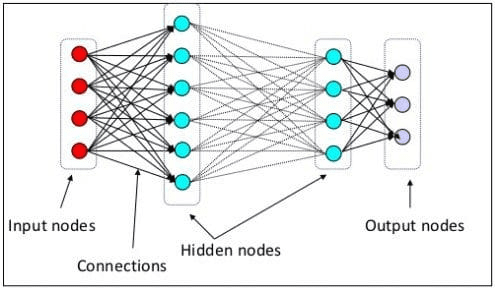
Neural Community Structure(Picture supply: KDnuggets)
As we will see within the picture above, the Neural Community consists of three layers:
- Enter layer the place it receives the data and transfers it to the opposite nodes within the subsequent layer.
- Hidden node layers the place all of the computations happen.
- Output node layer the place the computational outputs are.
It is known as deep studying once we practice our Neural Community mannequin with two or extra hidden layers. It’s known as deep as a result of it makes use of many layers in between. The benefit of deep studying fashions is that they robotically study and extract options from the info that conventional machine studying fashions are incapable of.
Within the Giant Language Mannequin, deep studying is vital because the mannequin is constructed upon deep neural community architectures. So, why is it known as LLM? It’s as a result of billions of layers are educated upon large quantities of textual content knowledge. The layers would produce mannequin parameters that assist the mannequin study complicated patterns in language, together with grammar, writing model, and plenty of extra.
The simplified means of the mannequin coaching is proven within the picture beneath.
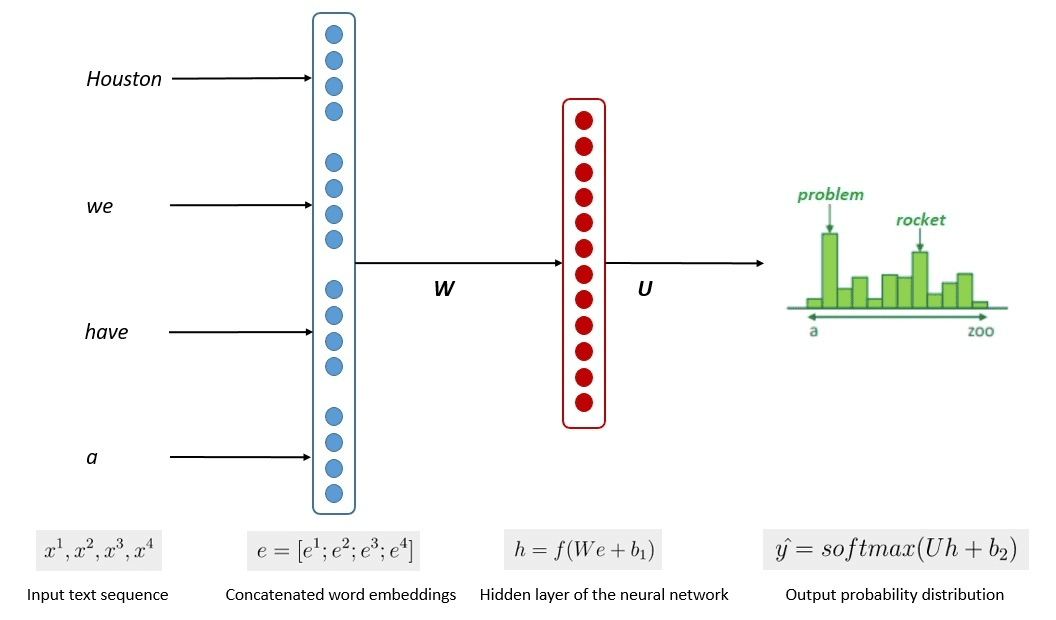
Picture by Kumar Chandrakant (Supply: Baeldung.com)
The method confirmed that the fashions might generate related textual content based mostly on the chance of every phrase or sentence of the enter knowledge. Within the LLMs, the superior method makes use of self-supervised studying and semi-supervised studying to attain the general-purpose functionality.
Self-supervised studying is a way the place we don’t have labels, and as a substitute, the coaching knowledge offers the coaching suggestions itself. It’s used within the LLM coaching course of as the info often lacks labels. In LLM, one might use the encompassing context as a clue to foretell the subsequent phrases. In distinction, Semi-supervised studying combines the supervised and unsupervised studying ideas with a small quantity of labeled knowledge to generate new labels for a considerable amount of unlabeled knowledge. Semi-supervised studying is often used for LLMs with particular context or area wants.
Within the third stage, we’d talk about the LLM extra deeply, particularly tackling the LLM construction and the way it might obtain human-like technology functionality.
Now we have mentioned that LLM relies on the Neural Community mannequin with Deep Studying strategies. The LLM has usually been constructed based mostly on transformer-based structure in recent times. The transformer relies on the multi-head consideration mechanism launched by Vaswani et al. (2017) and has been utilized in many LLMs.
Transformers is a mannequin structure that tries to unravel the sequential duties beforehand encountered within the RNNs and LSTMs. The previous means of the Language Mannequin was to make use of RNN and LSTM to course of knowledge sequentially, the place the mannequin would use each phrase output and loop them again so the mannequin wouldn’t overlook. Nevertheless, they’ve issues with long-sequence knowledge as soon as transformers are launched.
Earlier than we go deeper into the Transformers, I wish to introduce the idea of encoder-decoder that was beforehand utilized in RNNs. The encoder-decoder construction permits the enter and output textual content to not be of the identical size. The instance use case is a language translation, which regularly has a unique sequence measurement.
The construction could be divided into two. The primary half known as Encoder, which is part that receives knowledge sequence and creates a brand new illustration based mostly on it. The illustration could be used within the second a part of the mannequin, which is the decoder.
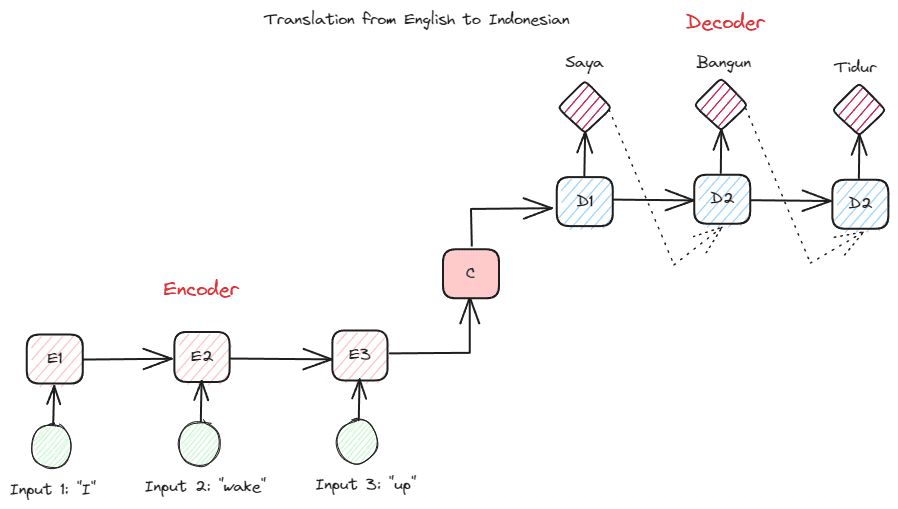
Picture by Creator
The issue with RNN is that the mannequin may need assistance remembering longer sequences, even with the encoder-decoder construction above. That is the place the eye mechanism might assist remedy the issue, a layer that would remedy lengthy enter issues. The eye mechanism is launched within the paper by Bahdanau et al. (2014) to unravel the encoder-decoder kind RNNs by specializing in an vital a part of the mannequin enter whereas having the output prediction.
The transformer’s construction is impressed by the encoder-decoder kind and constructed with the eye mechanism strategies, so it doesn’t have to course of knowledge in sequential order. The general transformers mannequin is structured just like the picture beneath.
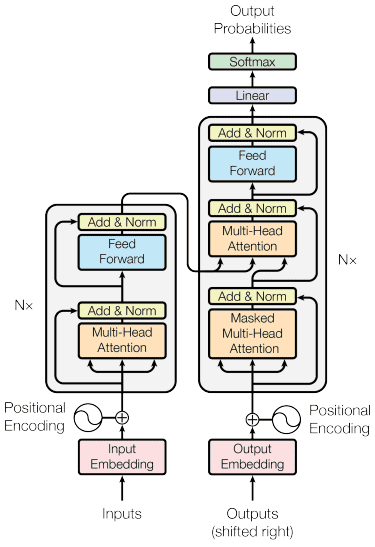
Transformers Structure (Vaswani et al. (2017))
Within the construction above, the transformers encode the info vector sequence into the phrase embedding whereas utilizing the decoding to rework knowledge into the unique kind. The encoding can assign a sure significance to the enter with the eye mechanism.
Now we have talked a bit about transformers encoding the info vector, however what’s a knowledge vector? Let’s talk about it. Within the machine studying mannequin, we will’t enter the uncooked pure language knowledge into the mannequin, so we have to rework them into numerical kinds. The transformation course of known as phrase embedding, the place every enter phrase is processed by the phrase embedding mannequin to get the info vector. We will use many preliminary phrase embeddings, equivalent to Word2vec or GloVe, however many superior customers attempt to refine them utilizing their vocabulary. In a fundamental kind, the phrase embedding course of could be proven within the picture beneath.
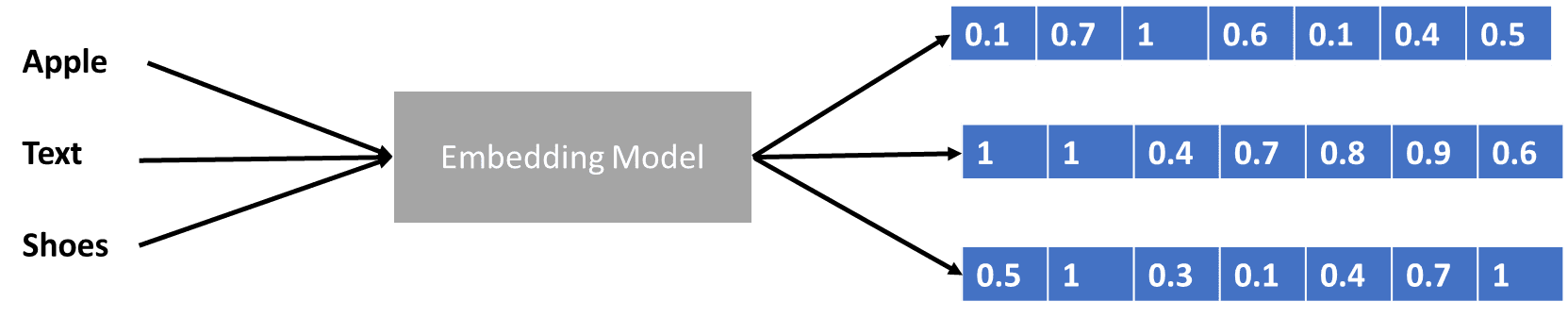
Picture by Creator
The transformers might settle for the enter and supply extra related context by presenting the phrases in numerical kinds like the info vector above. Within the LLMs, phrase embeddings are often context-dependent, typically refined upon the use circumstances and the meant output.
We mentioned the Giant Language Mannequin in three problem ranges, from newbie to superior. From the final utilization of LLM to how it’s structured, you will discover an evidence that explains the idea in additional element.
Cornellius Yudha Wijaya is a knowledge science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Information suggestions through social media and writing media.

OnePlus Nord CE 3 Lite 5G (Chromatic Gray, 8GB RAM, 128GB Storage)
₹17,999.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord CE 3 Lite 5G (Pastel Lime, 8GB RAM, 128GB Storage)
₹17,999.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Rockerz 255 Pro+ Bluetooth Neckband with Upto 60 Hours Playback, ASAP Charge, IPX7, Dual Pairing and Bluetooth v5.2(Navy Blue)
₹1,099.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme narzo 60X 5G(Nebula Purple 6GB,128GB Storage ) Up to 2TB External Memory | 50 MP AI Primary Camera | Segments only 33W Supervooc Charge
₹12,499.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
boAt Airdopes Atom 81 TWS Earbuds with Upto 50H Playtime, Quad Mics ENx™ Tech, 13MM Drivers,Super Low Latency(50ms), ASAP™ Charge, BT v5.3(Opal Black)
₹1,099.00 (as of February 15, 2024 21:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000Dpi, Led Tracking, Scrolling Wheel, Plug and Play
₹269.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
TP-Link AC750 Wifi Range Extender | Up to 750Mbps | Dual Band WiFi Extender, Repeater, Wifi Signal Booster, Access Point| Easy Set-Up | Extends Wifi to Smart Home & Alexa Devices (RE200)
₹1,799.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
FUR JADEN Anti Theft Number Lock Backpack Bag with 15.6 Inch Laptop Compartment, USB Charging Port & Organizer Pocket for Men Women Boys Girls
₹679.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ZEBRONICS Zeb-Comfort Wired USB Mouse, 3-Button, 1000 DPI Optical Sensor, Plug & Play, for Windows/Mac, Black
₹99.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Sounce Fast Phone Charging Cable & Data Sync USB Cable Compatible for iPhone 13, 12,11, X, 8, 7, 6, 5, iPad Air, Pro, Mini & iOS Devices
₹199.00 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AMD Ryzen 5 5600X 6-core, 12-Thread Unlocked Desktop Processor with Wraith Stealth Cooler
$157.45 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Crucial RAM 16GB DDR4 3200MHz CL22 (or 2933MHz or 2666MHz) Laptop Memory CT16G4SFRA32A
$38.98 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Rioddas External CD/DVD Drive for Laptop USB 3.0 CD/DVD Player Portable +/-RW Burner CD ROM Reader Rewriter Writer Disk Duplicator Compatible with Laptop Desktop PC Windows Apple Mac Pro Macbook Linux
$19.99 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermalright Peerless Assassin 120 SE CPU Cooler, 6 Heat Pipes AGHP Technology, Dual 120mm PWM Fans, 1550RPM Speed, for AMD:AM4 AM5/Intel LGA 1700/1150/1151/1200,PC Cooler
$33.90 (as of February 15, 2024 21:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)