
Copying from PDFs generally is a difficult job. When pasting the copied textual content or information, usually the formatting have to be fastened, with spacing, alignment, and particular characters everywhere. Cleansing it up can take ages.
Extracting content material from PDF information generally is a trouble, however with the appropriate instruments and methods, it may be carried out with ease. This complete information will stroll you thru completely different strategies to repeat numerous forms of content material from PDF information, making the extraction course of quicker and extra environment friendly.
1. Use Adobe Acrobat Reader’s Choose instrument to repeat textual content
Adobe Acrobat Reader is among the many most fashionable PDF viewers on the market. In the event you don’t wish to set up or join further software program, use Acrobat Reader’s built-in textual content choice instrument.
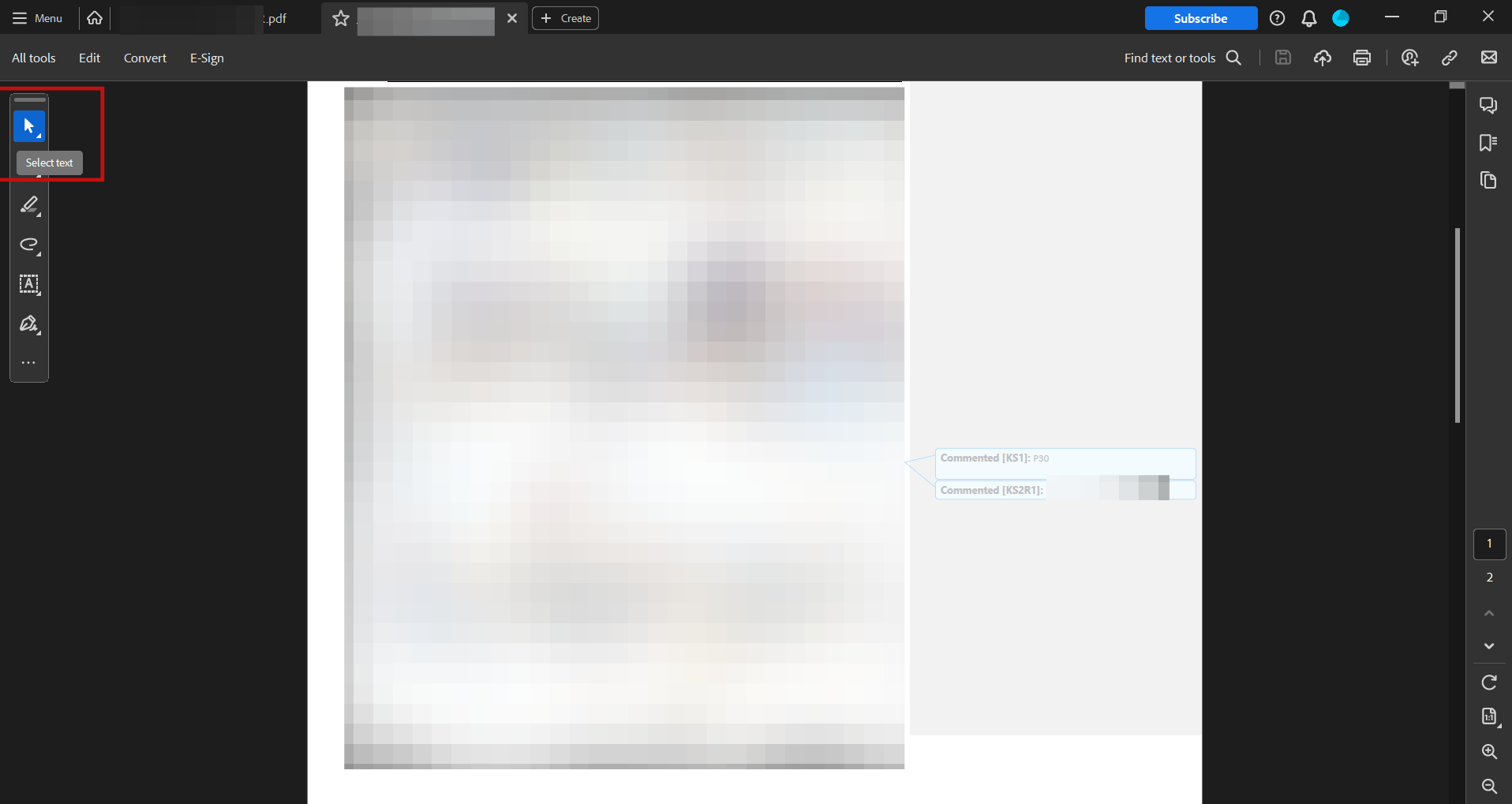
Observe these steps to get began:
- Open your PDF in Adobe Acrobat Reader.
- Click on the “Choose Device” button (arrow icon) within the toolbar to spotlight textual content within the PDF.
- Click on and drag to pick the textual content. You possibly can choose textual content throughout a number of pages if wanted.
- Spotlight the textual content, right-click, choose “Copy”, or use Ctrl+C on Home windows or Command+C on Mac.
- Paste the textual content utilizing Ctrl+V or Cmd+V.
This methodology is right for easy PDFs comprised largely of textual content. You possibly can manually copy the content material in segments and paste it into your goal doc. In contrast to different PDF readers, Acrobat Reader preserves the formatting effectively.
Acrobat Reader struggles with complicated PDFs — these with a number of columns and pictures combined with textual content, tables, and textual content on coloured backgrounds. The copied textual content may lose formatting and be pasted as plain textual content, needing guide cleanup or modifying later.
It might not be perfect for bulk textual content extraction from PDFs. For instance, processing vendor contracts and extracting key phrases and clauses from a whole bunch of PDFs will be tedious and time-consuming. Scanned pages are much more tough to repeat textual content from.
General, Acrobat Reader’s built-in copy textual content function works effectively for easy PDFs or rapidly grabbing textual content from nearly any PDF.
Do you simply wish to copy information from a bunch of PDFs? MS Excel’s Get Information function works wonders. It might robotically extract tables and information from PDF information into Excel spreadsheets.

Observe these easy steps:
- Open Excel and go to the Information tab.
- Click on Get Information > From File> From PDF.
- Choose the PDF file(s) you want to import information from. Excel will robotically detect and extract tables from the PDF doc(s).
- The Import Information dialog field shows a preview of the info. Select the desk(s) you want to import and click on Load.
- The extracted PDF information will likely be inserted into the spreadsheet as a desk, permitting for clear information for evaluation.
The information extraction works effectively for textual PDFs. You possibly can choose a desk or a number of tables to import from a number of PDF information. Excel can intelligently separate the info into rows and columns. It additionally permits customers so as to add filters or remodel the imported information inside Excel. This makes it simple to rapidly get usable information out of PDFs into Excel for additional evaluation and dashboarding.
Nevertheless, Excel struggles to extract the info for scanned paperwork or PDFs precisely with complicated layouts, similar to textual content columns or textual content over photos. It really works finest with textual PDFs with clearly outlined information tables and grid-like layouts. In case your PDF information is neatly organized in tables, utilizing Excel can prevent tons of guide copying, pasting, and reformatting work.
You may want extra superior information extraction capabilities for unstructured information locked in scanned paperwork or complicated experiences.
3. Open the PDF utilizing Google Docs or MS Phrase
Google Docs and Microsoft Phrase are two of the most well-liked textual content processors. They now have built-in optical character recognition (OCR) capabilities to transform photos and scanned paperwork into editable textual content.
Right here’s how one can make the most of this:
- Open Google Docs or Phrase and go to File> Open.
- Choose your PDF file. Google Docs/Phrase will extract the textual content and pictures from the PDF into a brand new doc.
- Copy or edit the extracted textual content as wanted.
- Paste the copied textual content into every other software or doc.
Be aware: You could want to simply accept compatibility mode prompts earlier than opening the PDF.
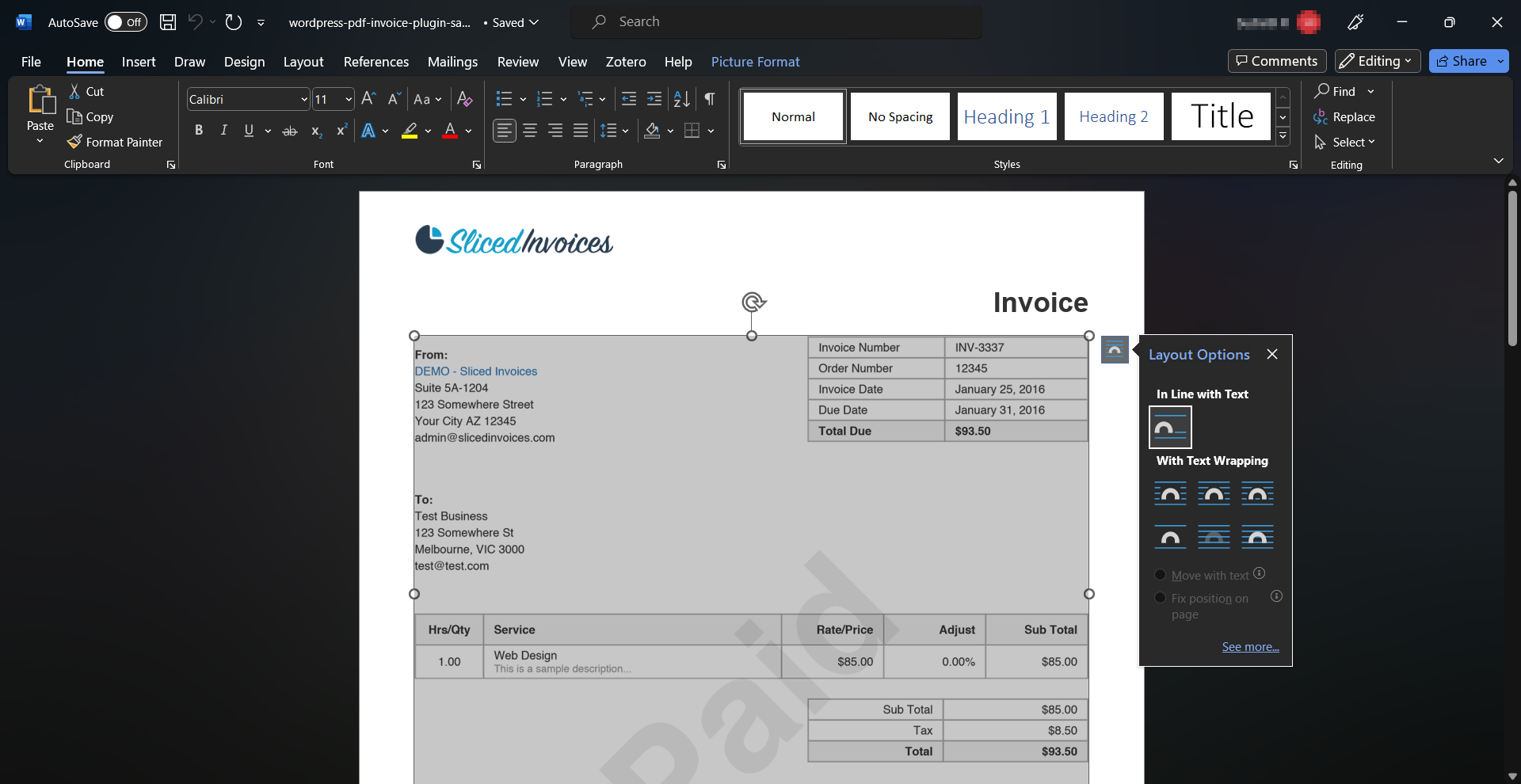
The extracted textual content retains primary formatting and is editable inside Google Docs or Phrase, permitting for cleansing up the textual content, modifying typos, or making different modifications earlier than copying it.
Advanced PDF layouts with a number of columns and text-over photos can pose challenges throughout conversion. The output doc could have formatting points or textual content within the mistaken order. So, whereas handy for easy PDFs, Google Docs and Phrase could battle with scanned or intricately designed paperwork.
General, utilizing Google Docs and Phrase to open and replica textual content from PDFs works effectively for day-to-day wants. Nevertheless, extra highly effective PDF extraction instruments are really helpful for superior information extraction from complicated experiences or bulk processing of contracts, authorized paperwork, and different paperwork.
Devoted instruments with OCR (Optical Character Recognition) capabilities can extract textual content from scanned paperwork or image-based PDFs. These handy options mean you can add your PDF file and obtain the extracted textual content again immediately with none want for software program set up.
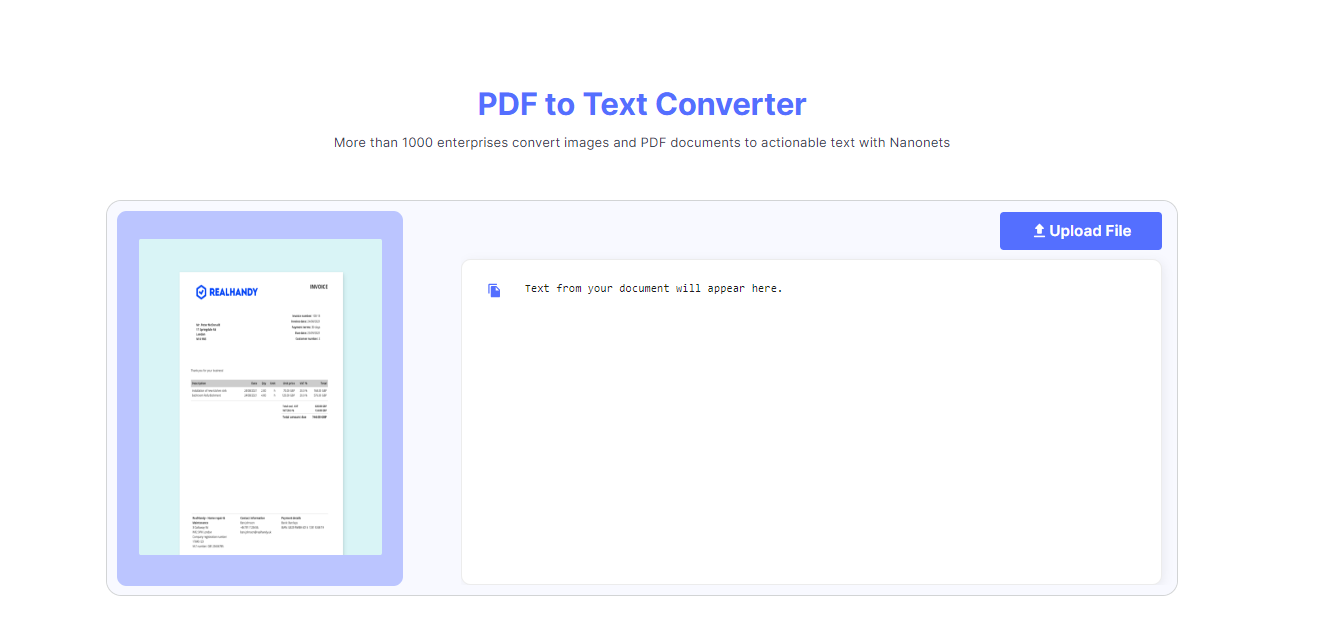
A number of the fashionable on-line OCR instruments embody:
Quite a few easy-to-use conversion instruments out there on the internet can simplify the method of extracting textual content from a PDF doc. These instruments can deal with quite a lot of output codecs and may make an image-based PDF searchable.
To make use of a web based converter:
- Go to the instrument’s web site.
- Add your PDF file or enter the URL the place it’s hosted.
- Select the output format — DOC, TXT, XLS, XLSX, JSON, or CSV.
- Click on “Convert” and look forward to the extraction of all textual content to complete.
- Obtain the output file containing the extracted textual content and replica the required textual content.
Most on-line converters supply some primary utilization without spending a dime. Nevertheless, sure superior options and elevated limits could require a paid subscription. Additionally, be conscious of privateness insurance policies earlier than importing delicate information.
Whereas handy, these instruments can falter with complicated desk layouts in PDFs. Conventional OCR instruments usually battle to precisely extract textual content from complicated layouts with textual content columns, photos, and different components. The extracted information could require intensive guide cleanup earlier than getting used for evaluation or reporting. Moreover, most on-line OCR converters have file measurement and month-to-month web page limits that may rapidly get exhausted when processing massive volumes of paperwork.
Nanonets is an AI-powered doc processing platform with superior OCR and automation capabilities to precisely extract textual content and information from PDFs and scanned paperwork.

The important thing capabilities
It might deal with complicated layouts with a number of textual content columns, photos, tables, and different components precisely. Nanonets leverages machine studying (ML) and pure language processing (NLP) to “see” and “perceive” doc buildings. This allows textual content and information extraction with context, sustaining the proper studying order and information relationships.
With built-in validation and approval workflows, you may guarantee high-quality output earlier than exporting the extracted information. Nanonets additionally supplies detailed accuracy experiences to watch OCR high quality throughout numerous doc sorts.
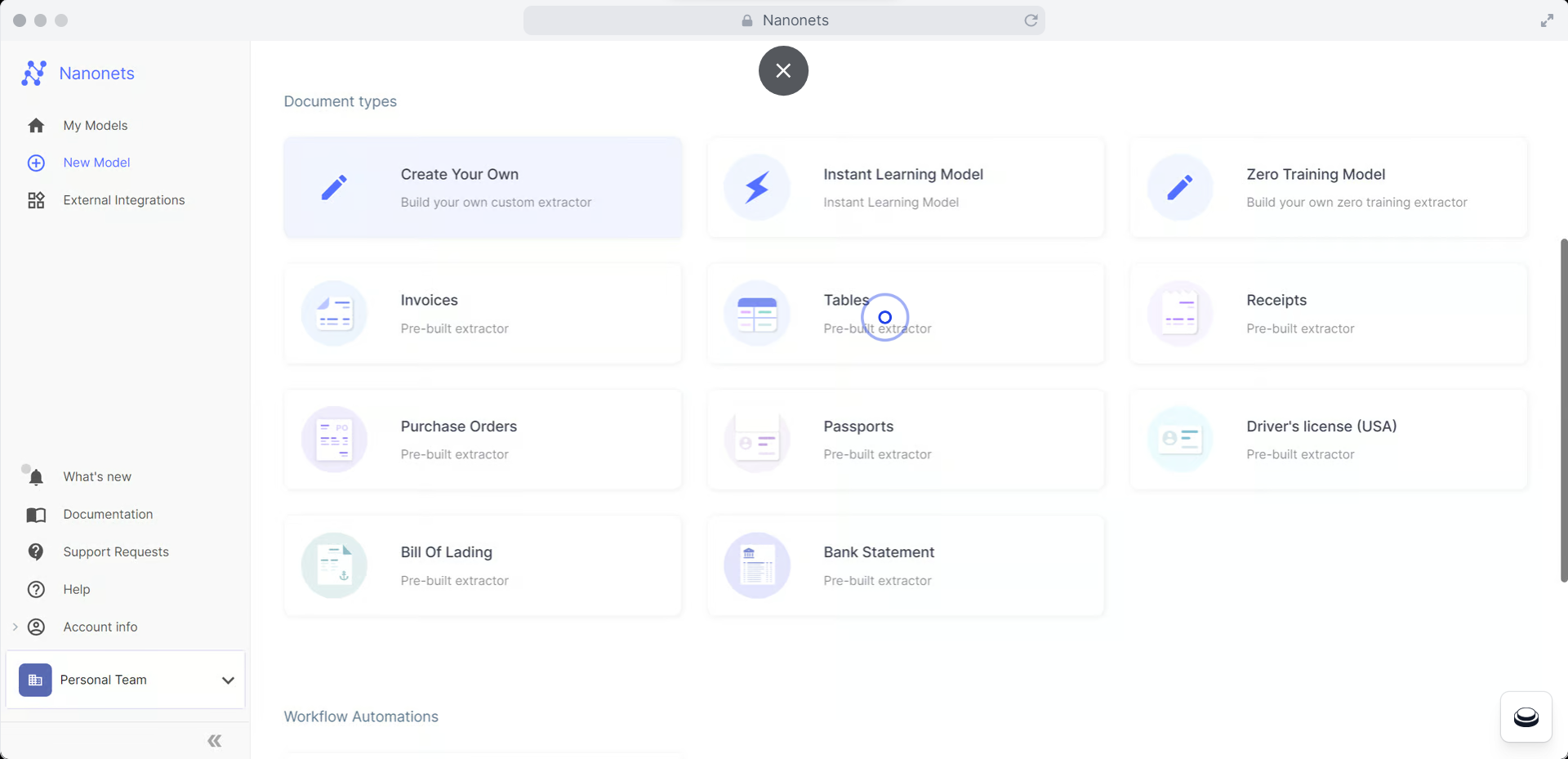
An instance
Suppose you run a recruitment agency that processes a whole bunch of PDFs every day. Your staff should manually extract names, e-mail addresses, cellphone numbers, expertise, and expertise from resumes and functions. With Nanonets, you may construct an automatic pipeline to OCR PDFs and extract structured information from resumes at scale. The platform understands resume layouts and extracts correct information fields, enabling quick processing of excessive volumes of paperwork with minimal guide work.
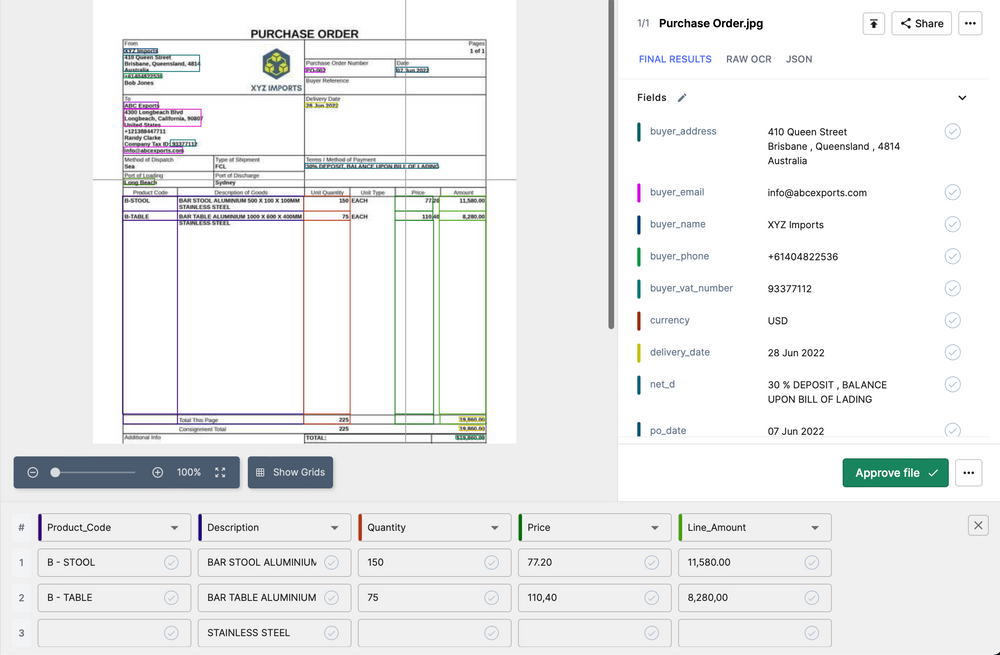
As well as, Nanonets supplies a sturdy API and integration ecosystem that permits you to join it to your current programs and workflows seamlessly. You possibly can arrange auto-import of paperwork from Gmail, Google Drive, OneDrive, and Dropbox. Integrations with instruments like Microsoft Dynamics, QuickBooks, and Xero mean you can route extracted information to your small business programs robotically. It additionally integrates with the favored workflow automation platform Zapier, which connects over 5,000 apps.
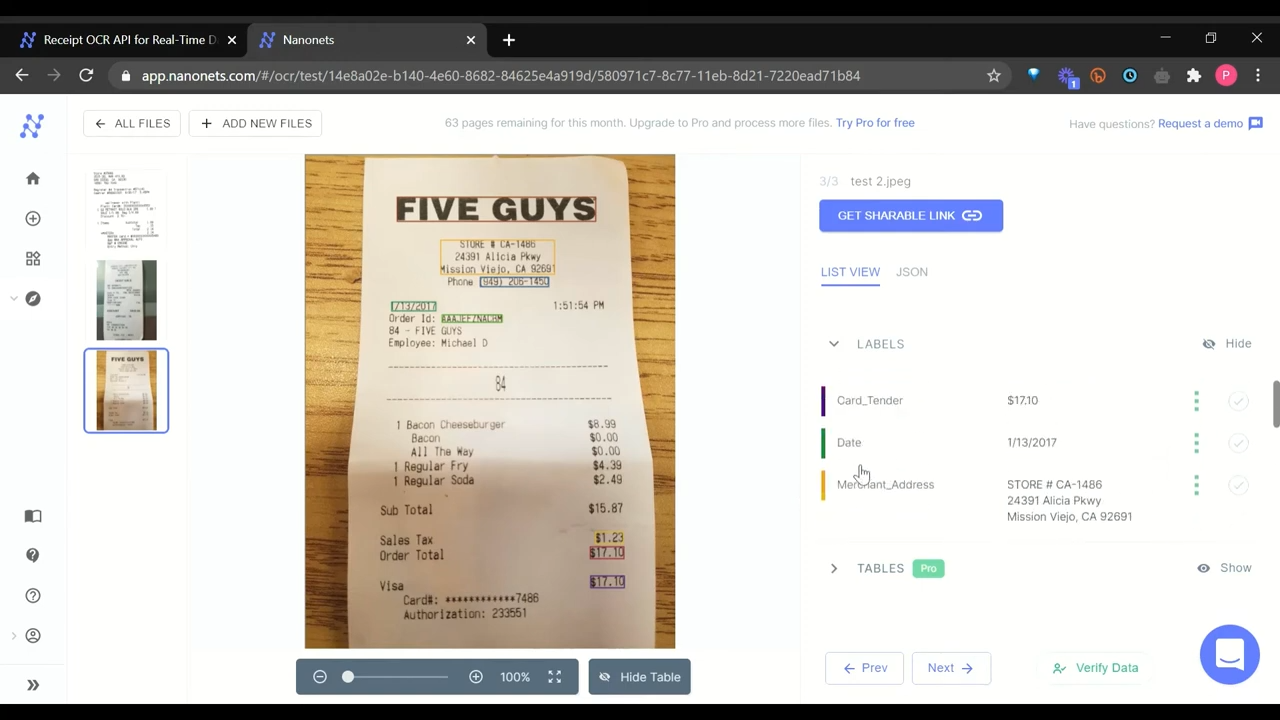
For instance, you may create an automatic workflow that OCRs resume PDFs uploaded to your Google Drive, extracts names, emails, and cellphone numbers right into a Google Sheet, after which makes use of Zapier so as to add these contacts to your CRM and assign duties to gross sales representatives to comply with up with high-potential candidates.
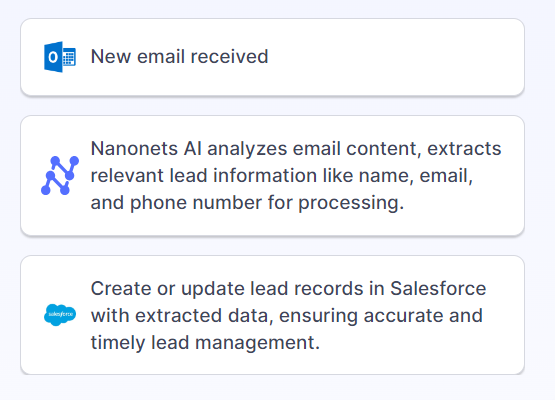
It might course of paperwork in numerous currencies, languages, layouts, and codecs with out dropping context. The AI learns from coaching information and guide interventions, bettering its accuracy.
How you can get began?
Add a pattern set of 5-10 paperwork, annotate the textual content you want to extract, and Nanonets will robotically construct a customized AI mannequin tailor-made to your paperwork. It might course of 1000’s of pages monthly whereas sustaining an accuracy price of over 95%.
The pricing for Nanonets is usage-based, permitting you to begin small and scale up as your wants develop. The primary 500 pages are free, and also you’ll have entry to 3 AI fashions, enabling you to check Nanonets on a number of doc sorts earlier than committing.
Closing ideas
Copying and pasting from PDFs does not need to be a chore. You possibly can simplify and streamline the method with the appropriate instruments and methods.
One of the best strategy will depend on your particular wants and paperwork. Assess your PDFs’ complexity, workflow wants, information privateness insurance policies, and extra. Discovering the answer that checks all of the containers on your state of affairs is crucial to long-term effectivity. The aim is to get rid of the guide drudgery of copying PDF textual content. Whether or not you deal with a couple of paperwork a month or course of 1000’s of pages every day, options exist to make your life simpler.

Noise Pulse Go Buzz Smart Watch with Advanced Bluetooth Calling, 1.69" TFT Display, SpO2, 100 Sports Mode with Auto Detection, Upto 7 Days Battery (2 Days with Heavy Calling) - Jet Black
₹1,099.00 (as of February 8, 2024 20:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Gladiator 1.96" Biggest Display Luxury Stainless Steel Smart Watch with Bluetooth Calling, Voice Assistant &123 Sports Modes, 8 Unique UI Interactions, 24/7 Heart Rate Tracking (Black)
₹1,699.00 (as of February 8, 2024 20:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Buds 3 Truly Wireless Bluetooth Earbuds with Upto 49dB Smart Adaptive Noise Cancellation,Hi-Res Sound Quality,Sliding Volume Control,10mins for 7Hours Fast Charging with Upto 44Hrs Playback
₹5,499.00 (as of February 8, 2024 20:44 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Redmi 13C (Starfrost White, 4GB RAM, 128GB Storage) | Powered by 4G MediaTek Helio G85 | 90Hz Display | 50MP AI Triple Camera
₹7,999.00 (as of February 8, 2024 20:45 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Mivi DuoPods A750 True Wireless Earbuds, Multi Device Connectivity, Metallic Finish, 55+ Hrs Playtime, 13MM Drivers, IPX 4.0, Type C Charging, AI-ENC for Call Clarity, Made in India - Black
₹1,199.00 (as of February 8, 2024 20:45 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹647.00 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
STRIFF Adjustable Laptop Tabletop Stand Patented Riser Ventilated Portable Foldable Compatible with MacBook Notebook Tablet Tray Desk Table Book with Free Phone Stand (Black)
₹299.00 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Callas Multipurpose Foldable Laptop Table with Cup Holder | Drawer | Mac Holder | Study Table, Breakfast Table, Foldable and Portable/Ergonomic & Rounded Edges/Non-Slip Legs (WA-27-Black) | Metal
₹499.00 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Zebronics-NS1500 Laptop Stand Featuring Foldable Design, Anti-Slip Silicone Rubber Pads, Supports Maximum of 5kgs Weight Tabletop
₹299.00 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell USB Wireless Keyboard and Mouse Set- KM3322W, Anti-Fade & Spill-Resistant Keys, up to 36 Month Battery Life, 3Y Advance Exchange Warranty, Black
₹1,199.00 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SanDisk 2TB Extreme Portable SSD - Up to 1050MB/s, USB-C, USB 3.2 Gen 2, IP65 Water and Dust Resistance, Updated Firmware - External Solid State Drive - SDSSDE61-2T00-G25
$149.88 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 2TB External Hard Drive HDD — USB 3.0 for PC, Mac, PlayStation, & Xbox -1-Year Rescue Service (STGX2000400)
$67.99 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Corsair VENGEANCE LPX DDR4 RAM 32GB (2x16GB) 3200MHz CL16 Intel XMP 2.0 Computer Memory - Black (CMK32GX4M2E3200C16)
$77.99 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Seagate Portable 5TB External Hard Drive HDD – USB 3.0 for PC, Mac, PS4, & Xbox - 1-Year Rescue Service (STGX5000400), Black
$119.99 (as of February 8, 2024 20:39 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)