

The seek for fashions that may effectively course of multidimensional knowledge, starting from photographs to complicated time sequence, has change into more and more essential. Earlier Transformer fashions, famend for his or her means to deal with numerous duties, typically battle with lengthy sequences on account of their quadratic computational complexity. This limitation has sparked a surge of curiosity in creating architectures that scale higher and improve efficiency when coping with large-scale datasets.
The effectivity of dealing with lengthy knowledge sequences is pivotal, particularly as the quantity and complexity of information in purposes comparable to picture processing and time sequence forecasting proceed to develop. The computational calls for of present strategies pose important challenges, pushing researchers to innovate architectures that streamline processing with out sacrificing accuracy. Selective State Area Fashions (S6) have emerged as a promising resolution, selectively focusing computational assets on probably the most informative knowledge segments, doubtlessly revolutionizing the effectivity and effectiveness of information processing.
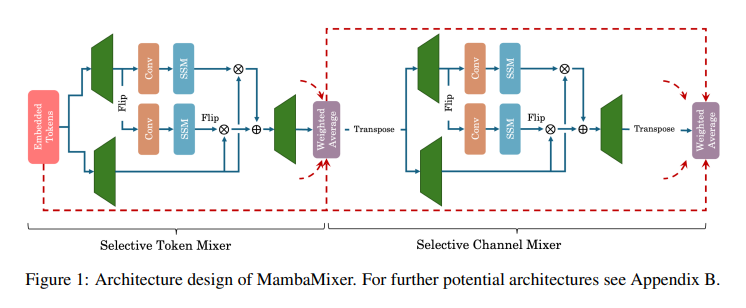
Researchers from Cornell College and the NYU Grossman Faculty of Medication current MambaMixer, a novel structure that includes data-dependent weights. This structure leverages a singular twin choice mechanism, the Selective Token and Channel Mixer, to effectively navigate tokens and channels. A weighted averaging course of additional augments this twin choice mechanism to make sure seamless info move throughout the mannequin’s layers for optimizing processing effectivity and mannequin efficiency.
The utility and effectiveness of the MambaMixer structure are exemplified in its specialised purposes: the Imaginative and prescient MambaMixer (ViM2) for image-related duties and the Time Sequence MambaMixer (TSM2) for forecasting time sequence knowledge. These implementations spotlight the structure’s versatility and energy. As an example, in difficult benchmarks like ImageNet, ViM2 achieves aggressive efficiency towards well-established fashions. Nonetheless, it surpasses SSM-based imaginative and prescient fashions, demonstrating superior effectivity and accuracy in picture classification, object detection, and semantic segmentation duties.
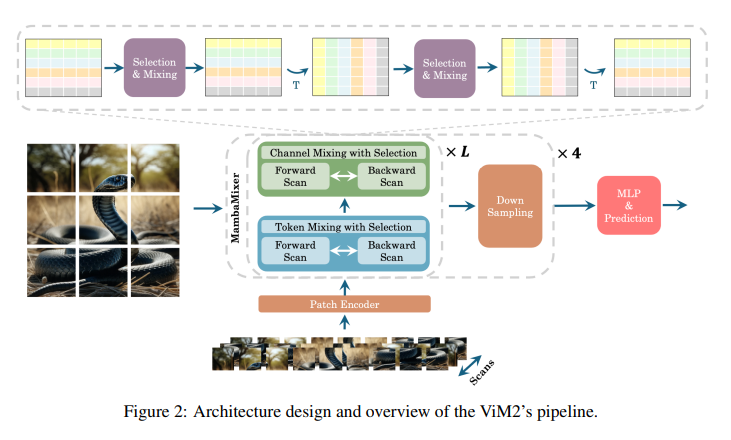
ViM2 has demonstrated aggressive efficiency in difficult benchmarks like ImageNet. It achieved top-1 classification accuracies of 82.7%, 83.7%, and 83.9% for its Tiny, Small, and Base variants, respectively, outperforming well-established fashions like ViT, MLP-Mixer, and ConvMixer in sure configurations. A weighted averaging mechanism enhances the knowledge move and captures the complicated dynamics of options, contributing to its state-of-the-art efficiency. TSM2 showcases groundbreaking leads to time sequence forecasting, setting new data in numerous benchmarks. As an example, its utility to the M5 dataset demonstrates an enchancment in WRMSSE scores.
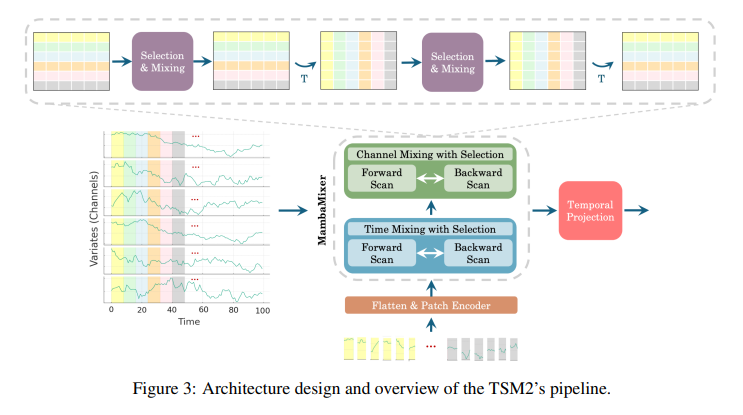
The structure’s achievements, for example, in semantic segmentation duties on the ADE20K dataset, ViM2 fashions confirmed mIoU (single-scale) enhancements of 1.3, 3.7, and 4.2 for the Tiny, Small, and Medium configurations, respectively, when in comparison with different main fashions. These outcomes underscore the structure’s capability to course of info selectively and effectively.

In conclusion, as datasets proceed to broaden in dimension and complexity, the event of fashions like MambaMixer, which might effectively and selectively course of info, turns into more and more important. This structure represents a important step ahead, providing a scalable and efficient framework for tackling the challenges of recent machine-learning duties. Its success in each imaginative and prescient and time sequence modeling duties demonstrates its potential and evokes additional analysis and growth in environment friendly knowledge processing strategies.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 39k+ ML SubReddit
Hiya, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about expertise and need to create new merchandise that make a distinction.

Portronics Luxcell Wireless Mini 10k 10000mAh 15W Magnetic Wireless Fast Charging Smallest Power Bank with 22.5 Wired Output Compatible with iPhone 12 & Above & Other QI Enabled Devices(Black)
₹1,469.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
realme Buds 2 Wired in Ear Earphones with Mic (Black)
₹599.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Fire-Boltt Phoenix Ultra Luxury Stainless Steel, Bluetooth Calling Smartwatch, AI Voice Assistant, Metal Body with 120+ Sports Modes, SpO2, Heart Rate Monitoring (Gold)
₹1,749.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z9 5G (Brushed Green, 8GB RAM, 256GB Storage) | Dimensity 7200 5G Processor | Sony IMX882 OIS Camera | 120Hz AMOLED with 1800 nits Local Peak Brightness | 44W Charger in The Box
₹21,999.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HP 680 Original Ink Advantage Cartridge (Black)
₹799.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Ambrane Unbreakable 3 in 1 USB Fast Charging Cable with Type C, Lightning, Micro USB Port with 2.1 A, Compatible with iPhone, iPad, Samsung, OnePlus, Mi, Oppo, Vivo, Xiaomi, 1.25M (Trio-11, Black)
₹249.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000DPI, LED Tracking, Scrolling Wheel, Plug and Play
₹309.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toysbuddy Re-Writable LCD Writing Tablet Pad with Screen 21.5cm (8.5Inch) for Drawing, Playing, Handwriting Best Birthday Gifts for Adults & Kids Girls Boys, Multicolor
₹139.00 (as of April 1, 2024 14:09 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)Auto Amazon Links: No products found.