

In synthetic intelligence, attaining effectivity in neural networks is a paramount problem for researchers resulting from its fast evolution. The hunt for strategies minimizing computational calls for whereas preserving or enhancing mannequin efficiency is ongoing. A very intriguing technique lies in optimizing neural networks by the lens of structured sparsity. This strategy guarantees an inexpensive steadiness between computational economic system and the effectiveness of neural fashions, probably revolutionizing how we practice and deploy AI programs.
Sparse neural networks, by design, intention to trim down the computational fats by pruning pointless connections between neurons. The core thought is easy: eliminating superfluous weights can considerably scale back the computational burden. Nonetheless, this process is something however easy. Conventional, sparse coaching strategies usually grapple with sustaining a fragile steadiness. They both lean in direction of computational inefficiency resulting from random removals resulting in irregular reminiscence entry patterns or compromise the community’s studying functionality, resulting in underwhelming efficiency.
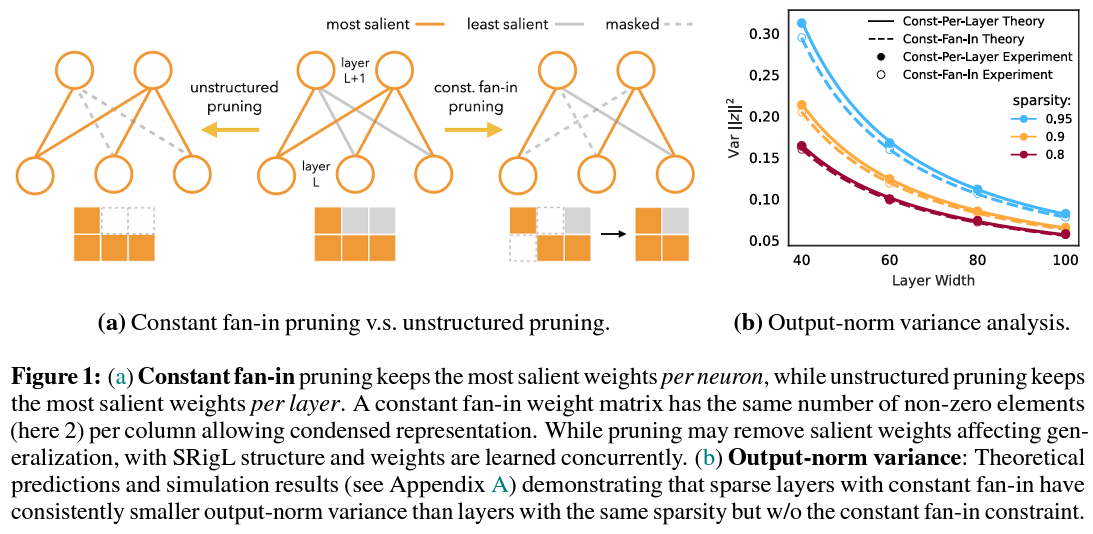
Meet Structured RigL (SRigL), a groundbreaking methodology developed by a collaborative staff from the College of Calgary, Massachusetts Institute of Expertise, Google DeepMind, College of Guelph, and the Vector Institute for AI. SRigL stands as a beacon of innovation in dynamic sparse coaching (DST), tackling the problem head-on by introducing a way that embraces structured sparsity and aligns with the pure {hardware} efficiencies of contemporary computing architectures.
SRigL is extra than simply one other sparse coaching methodology; it’s a finely tuned strategy that leverages an idea often known as N: M sparsity. This precept dictates a structured sample the place N should stay out of M consecutive weights, making certain a continuing fan-in throughout the community. This stage of structured sparsity is just not arbitrary. It’s the product of meticulous empirical evaluation and a deep understanding of the theoretical and sensible features of neural community coaching. By adhering to this structured strategy, SRigL maintains the mannequin’s efficiency at a fascinating stage and considerably streamlines computational effectivity.
The empirical outcomes supporting SRigL’s efficacy are compelling. Rigorous testing throughout a spectrum of neural community architectures, together with CIFAR-10 and ImageNet datasets benchmarks, demonstrates SRigL’s prowess. For example, using a 90% sparse linear layer, SRigL achieved real-world accelerations of as much as 3.4×/2.5× on CPU and 1.7×/13.0× on GPU for on-line and batch inference, respectively, when put next towards equal dense or unstructured sparse layers. These numbers aren’t simply enhancements; they characterize a seismic shift in what is feasible in neural community effectivity.
Past the spectacular speedups, SRigL’s introduction of neuron ablation—permitting for the strategic removing of neurons in high-sparsity eventualities—additional cements its standing as a way able to matching, and generally surpassing, the generalization efficiency of dense fashions. This nuanced technique ensures that SRigL-trained networks are sooner and smarter, able to discerning and prioritizing which connections are important for the duty.
The event of SRigL by researchers affiliated with esteemed establishments and corporations marks a major milestone within the journey in direction of extra environment friendly neural community coaching. By cleverly leveraging structured sparsity, SRigL paves the way in which for a future the place AI programs can function at unprecedented ranges of effectivity. This methodology doesn’t simply push the boundaries of what’s doable in sparse coaching; it redefines them, providing a tantalizing glimpse right into a future the place computational constraints are now not a bottleneck for innovation in synthetic intelligence.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a concentrate on Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Enhancing Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

Mivi DuoPods A750 True Wireless Earbuds, Multi Device Connectivity, Metallic Finish, 55+ Hrs Playtime, 13MM Drivers, IPX 4.0, Type C Charging, AI-ENC for Call Clarity, Made in India - Black
₹1,199.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹699.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Noise Newly Launched Buds N1 in-Ear Truly Wireless Earbuds with Chrome Finish, 40H of Playtime, Quad Mic with ENC, Ultra Low Latency(up to 40 ms), Instacharge(10 min=120 min), BT v5.3(Calm Beige)
₹1,199.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
OnePlus Nord Buds 2r True Wireless in Ear Earbuds with Mic, 12.4mm Drivers, Playback:Upto 38hr case,4-Mic Design, IP55 Rating [Deep Grey]
₹1,999.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
iQOO Z7s 5G by vivo (Norway Blue, 8GB RAM, 128GB Storage) | Ultra Bright AMOLED Display | Snapdragon 695 5G 6nm Processor | 64 MP OIS Ultra Stable Camera | 44WFlashCharge
₹16,999.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Oakter Mini UPS for 12V WiFi Router Broadband Modem | Backup Upto 4 Hours | WiFi Router UPS Power Backup During Power Cuts | UPS Broadband Modem | Current Surge & Deep Discharge Protection
₹1,299.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Canon PIXMA PG47 Black Ink Cartridge
₹700.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USB C to Lightning Cable 1M [Apple MFi Certified] iPhone Fast Charger Cable USB-C Power Delivery Charging Cord for iPhone 14/13/12/12 PRO Max/12 Mini/11/11PRO/XS/Max/XR/X/8/8Plus/iPad
₹699.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Lapster 24pcs Mix Spiral Charger Spiral Charger Cable Protectors for Wires Data Cable Saver Charging Cord Protective Cable Cover
₹99.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Dell MS116 Wired Optical Mouse, 1000DPI, LED Tracking, Scrolling Wheel, Plug and Play
₹269.00 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Toshiba Canvio Basics 1TB Portable External Hard Drive USB 3.0, Black - HDTB510XK3AA
$63.88 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
SAMSUNG T7 Shield 4TB Portable SSD - 1050MB/s, Rugged, Water & Dust Resistant, for Content Creators - Black
$249.99 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Thermal Grizzly Kryonaut, High Performance Thermal Paste for Cooling All Processors, Graphics Cards and Heat Sinks in Computers and Consoles -1.0 Gram
$8.99 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
ARCTIC MX-6 (4 g) - Ultimate Performance Thermal Paste for CPU, Consoles, Graphics Cards, laptops, Very high Thermal Conductivity, Long Durability, Non-Conductive, CPU Thermal Paste
$6.15 (as of March 1, 2024 21:17 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)